Proteogenomics 2: Database Search
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to identify variant proteoforms in MS data by searching with the customized Protein database?
Requirements:
A proteogenomic data analysis of mass spectrometry data to identify and visualize variant peptides.
Time estimation: 15 minutesLevel: Intermediate IntermediateSupporting Materials:Published: Nov 20, 2018Last modification: Apr 22, 2026License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00232rating Rating: 5.0 (1 recent ratings, 9 all time)version Revision: 25
In this tutorial, we perform proteogenomic database searching using the Mass Spectrometry data. The inputs for performing the proteogenomic database searching are the peaklist MGF files and the FASTA database file. The FASTA database is obtained by running the first workflow “Uniprot_cRAP_SAV_indel_translatedbed.FASTA”. The second workflow focuses on performing database search of the peak list files (MGFs).
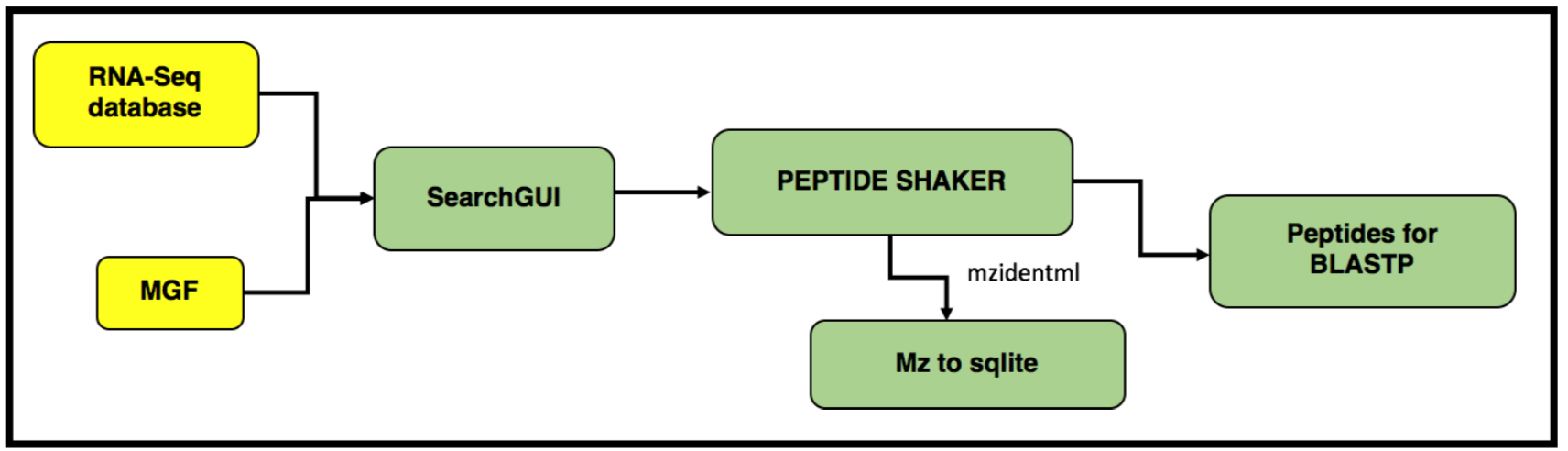
AgendaIn this tutorial, we will deal with:
Pretreatments
Hands On: data upload and organization
- Create a new history and name it something meaningful (e.g. Proteogenomics DB search)
- Import the four MGF MS/MS files and the Trimmed_ref_5000_uniprot_cRAP.FASTA sequence file from Zenodo.

https://zenodo.org/record/1489208/files/Mo_Tai_Trimmed_mgfs__Mo_Tai_iTRAQ_f4.mgf https://zenodo.org/record/1489208/files/Mo_Tai_Trimmed_mgfs__Mo_Tai_iTRAQ_f5.mgf https://zenodo.org/record/1489208/files/Mo_Tai_Trimmed_mgfs__Mo_Tai_iTRAQ_f8.mgf https://zenodo.org/record/1489208/files/Mo_Tai_Trimmed_mgfs__Mo_Tai_iTRAQ_f9.mgf https://zenodo.org/records/15359565/files/Uniprot_cRAP_SAV_indel_translatedbed.fasta https://zenodo.org/records/13270741/files/Reference_Protein_Accessions.tabular
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
- Rename the datasets to something more recognizable (strip the URL prefix)
Verify that the
Reference_Protein_Accessions.tabularformat istabular.
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select
tabularfrom “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
Build a Dataset list for the four MGF files, name it as
Mo_Tai_MGFs
- Click on galaxy-selector Select Items at the top of the history panel
- Check all the datasets in your history you would like to include
Click n of N selected and choose Advanced Build List
You are in collection building wizard. Choose Flat List and click ‘Next’ button at the right bottom corner.
Double clcik on the file names to edit. For example, remove file extensions or common prefix/suffixes to cleanup the names.
- Enter a name for your collection
- Click Build to build your collection
- Click on the checkmark icon at the top of your history again



Match peptide sequences
The search database labeled Uniprot_cRAP_SAV_indel_translatedbed.FASTA is the input database that
will be used to match MS/MS to peptide sequences via a sequence database search.
For this, the sequence database-searching program called SearchGUI will be used.The generated dataset collection of the three MGF files in the history is used as the MS/MS input. We will walk through a number of these settings in order to utilize SearchGUI on these example MGF files.
SearchGUI
Hands On: SearchGUI
- Identification Parameters ( Galaxy version 4.0.41+galaxy1) with the following parameters:
- “Fixed Modifications”:
Carbamidomethylation of C, ITRAQ-4Plex of K, ITRAQ-4Plex of peptide N-term- “Variable modifications”:
Oxidation of M, ITRAQ-4Plex of Y- “Fragment Tolerance (Daltons)”:
0.05(this is high resolution MS/MS data)- “Minimum charge”:
2- “Maximum charge”:
6- Section Search Engine Options:
- “X!Tandem Options”:
Advanced- “X!Tandem: Advanced Search Related”:
Set Advanced Search Parameters
- “X!Tandem: Quick Acetyl”:
No- “X!Tandem: Quick Pyrolidone”:
No- Section X!Tandem peptide model refinement
- “X!Tandem: Maximum Valid Expectation Value, refinement” :
100- Search GUI ( Galaxy version 4.0.41+galaxy2) with the following parameters:
- param-file “Identification Parameters file”:
Identification Parameters: PAR fileparam-file “Protein Database”:
Uniprot_cRAP_SAV_indel_translatedbed.FASTA(Or however you named theFASTAfile)CommentThe “Uniprot_cRAP_SAV_indel_translatedbed” FASTA database is obtained when you run the first proteogenomics workflow “Proteogenomics 1: Database Creation”. Please make sure to run the 1st workflow.
param-collection “Input Peak lists (mgf)”:
Mo_Tai_MGFsdataset collection.
Click the Dataset collection icon on the left of the input field:
Select the appropriate dataset collection from the list
- Section Search Engine Options:
param-check “DB-Search Engines”:
X!TandemCommentThe section Search Engine Options contains a selection of sequence database searching programs that are available in SearchGUI. Any combination of these programs can be used for generating PSMs from MS/MS data. For the purpose of this tutorial, X!Tandem we will be used.
Once the database search is completed, the SearchGUI tool will output a file (called a SearchGUI archive file) that will serve as an input for the next section, PeptideShaker. Rename the output as “Compressed SearchGUI results”
CommentNote that sequence databases used for proteogenomics are usually much larger than the excerpt used in this tutorial. When using large databases, the peptide identification step can take much more time for computation. In proteogenomics, choosing the optimal database is a crucial step of your workflow.
PeptideShaker
PeptideShaker is a post-processing software tool that processes data from the SearchGUI software tool. It serves to organize the Peptide-Spectral Matches (PSMs) generated from SearchGUI processing and is contained in the SearchGUI archive. It provides an assessment of confidence of the data, inferring proteins identified from the matched peptide sequences and generates outputs that can be visualized by users to interpret results. PeptideShaker has been wrapped in Galaxy to work in combination with SearchGUI outputs.
Comment: File FormatsThere are a number of choices for different data files that can be generated using PeptideShaker. A compressed file can be made containing all information needed to view them results in the standalone PeptideShaker viewer. A
mzidentMLfile can be generated that contains all peptide sequence matching information and can be utilized by compatible downstream software. Other outputs are focused on the inferred proteins identified from the PSMs, as well as phosphorylation reports, relevant if a phosphoproteomics experiment has been undertaken.
Hands On: PeptideShaker
- Peptide Shaker ( Galaxy version 2.0.33+galaxy2) with the following parameters:
- param-file “Compressed SearchGUI results”: The
Search GUIarchive file- “Include the protein sequences in mzIdentML”:
No- “Output options”: Select the
PSM Report(Peptide-Spectral Match) and theCertificate of AnalysisComment: Certificate of AnalysisThe “Certificate of Analysis” provides details on all the parameters used by both SearchGUI and PeptideShaker in the analysis. This can be downloaded from the Galaxy instance to your local computer in a text file if desired.
- Inspect galaxy-eye the resulting files
A number of new items will appear in your History, each corresponding to the outputs selected in the PeptideShaker parameters. The Peptide Shaker’s PSM report is used as an input for the BlastP analysis. Before performing BlastP analysis. The Query Tabular tool and few test manipulation tools are used to remove spectra that belongs to the reference proteins. The output tabular file “Peptides_for_Blast-P_analysis” will contain only those spectra that did not belong to any known proteins.
Create a SQLite database for peptide, protein and genomic annotation visualization
The mzidentml output from the Peptide shaker is converted into an sqlite database file by using the mz to sqlite tool. This sqlite output is used to open the Multi-omics visualization platform, wherein you can view the spectra of the peptides using Lorikeet parameters. To open the MVP viewer, click on the “Visualize” galaxy-visualise icon and select “MVP Application” ( this will open the interactive multi-omics viewer)
Hands On: mz to sqliteThis tool extracts mzidentml and its associated proteomics datasets into a sqlite db
- mz to sqlite ( Galaxy version 2.1.1+galaxy0) with the following parameters:
- param-file “Proteomics identification files”:
PeptideShaker_mzidentml- param-collection “Proteomics Spectrum files”:
Mo_Tai_MGFs- param-file “Proteomics Search Database Fasta”:
Uniprot_cRAP_SAV_indel_translatedbed.FASTA
The next step is to remove known peptides from the list of PSMs that we acquired from the Peptide Shaker results. For that, we need to perform Query tabular to extract the list of known peptides from the UniProt and cRAP database.
Query Tabular
Hands On: Remove Reference proteins
Query Tabular ( Galaxy version 3.3.2) with the following parameters:
- param-repeat Insert Database Table (b):
PSM report
- Section Filter Dataset Input:
- param-repeat Insert Filter Tabular Input Lines
- “Filter by”:
skip leading lines- “Skip lines”:
1- Section Table Options:
- “Specify Name for Table”:
psms- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
id,Proteins,Sequence- “Only load the columns you have named into database”:
Yes- param-repeat Table Index
- “This is a unique index”:
No- “Index on Columns”:
idparam-repeat Insert Database Table (c):
PSM report- Section Filter Dataset Input
- param-repeat Insert Filter Tabular Input Lines
- “Filter by”:
skip leading lines- “Skip lines”:
1- param-repeat Insert Filter Tabular Input Lines
- “Filter by”:
select columns- “Enter column numbers to keep”:
1,2- param-repeat Insert Filter Tabular Input Lines
- “Filter by”:
normalize list columns,replicate rows for each item in the list- “Enter column numbers to normalize”:
2- “List item delimiter in column”:
,- Section Table Options:
- “Specify Name for Table”:
prots- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
id,prot- “Only load the columns you have named into database”:
Yes- param-repeat Insert Table Index:
- “This is a unique index”:
No- “Index on Columns”:
prot,id- param-repeat Insert Database Table (a):
Reference_Protein_Accessions- Section Table Options:
- “Tabular Dataset for Table”:
Uniprot- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
prot- param-repeat Insert Table Index:
- “This is a unique index”:
No- “Index on Columns”:
protCommentBy default, table columns will be named: c1,c2,c3,…,cn (column names for a table must be unique). You can override the default names by entering a comma separated list of names, e.g.
,name1,,,name2would rename the second and fifth columns. Check your input file to find the settings which best fits your needs.“Save the sqlite database in your history”:
NoComment: Querying an SQLite DatabaseQuery Tabular can also use an existing SQLite database. Activating
Save the sqlite database in your historywill store the generated database in the history, allowing to reuse it directly.- “SQL Query to generate tabular output”:
SELECT psms.* FROM psms WHERE psms.id NOT IN (SELECT distinct prots.id FROM prots JOIN uniprot ON prots.prot = uniprot.prot) ORDER BY psms.id- “include query result column headers”:
Yes
- Click Run Tool and inspect the query results file after it turns green.
The output from this step is that the resultant peptides would be those which doesn’t belong in the Uniprot or cRAP database. The query tabular tool is used again to create a tabular output containing peptides ready for Blast P analysis.
Hands On: Query Tabular
Query Tabular ( Galaxy version 3.3.2) with the following parameters:
- param-repeat Insert Database Table (b):
Query results- Section Filter Dataset Input:
- param-repeat Insert Filter Tabular Input Lines
- “Filter by”:
skip leading lines- “Skip lines”:
1- Section Table Options:
- “Specify Name for Table”:
psm- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
id,Proteins,Sequence- “Only load the columns you have named into database”:
Yes- “SQL Query to generate tabular output”:
SELECT Sequence || ' PSM=' || group_concat(id,',') || ' length=' || length(Sequence) as "ID",Sequence FROM psm WHERE length(Sequence) >6 AND length(Sequence) <= 30 GROUP BY Sequence ORDER BY length(Sequence),Sequence“include query result column headers”:
Yes- Click Run Tool and inspect the query results file after it turns green.
Rename galaxy-pencil the output as
Peptides_for_Blast-P_analysis
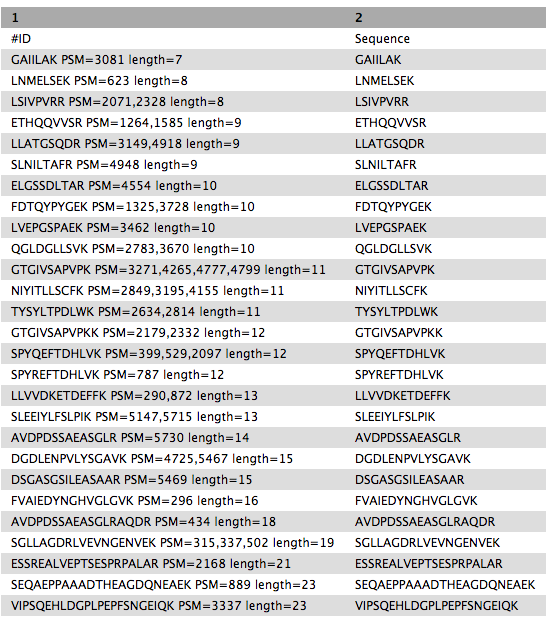
Getting data Blast-P ready
BlastP search is carried out with the PSM report (output from PeptideShaker). Before, BlastP analysis the “Peptides_for_Blast-P_analysis” is first converted from Tabular format to FASTA file format which can be easily read by the BlastP algorithm. This is done with the help of “Tabular to FASTA” conversion tool. The short BlastP uses parameters for short peptide sequences (8-30 aas). Please use the rerun option to look at the parameters used.
Hands On: Tabular to FASTA (version 1.1.1)
- Tabular-to-FASTA ( Galaxy version 1.1.1) with the following parameters:
- “Tab-delimited file”:
Peptides_for_Blast-P_analysis- “Title column”:
1- “Sequence Column”:
2
The output FASTA file is going to be subjected to BLAST-P analysis.
Comment: Tool VersionsThe tools are subjected to changes while being upgraded. Thus, running the workflow provided with the tutorial, the user might need to make sure they are using the latest version including updating the parameters.
Conclusion
This completes the walkthrough of the proteogenomics database search workflow. This tutorial is a guide to performing database searching with mass spectrometry files and having peptides ready for Blast-P analysis, you can perform follow-up analysis using the next GTN “Proteogenomics Novel Peptide Analysis”. Researchers can use this workflow with their data also, please note that the tool parameters, reference genomes, and the workflow will need to be modified accordingly.
This workflow was developed by the Galaxy-P team at the University of Minnesota. For more information about Galaxy-P or our ongoing work, please visit us at galaxyp.org
You've Finished the Tutorial
Key points
With SearchGUI and PeptideShaker you can gain access to multiple search engines
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Subina Mehta, Timothy J. Griffin, Pratik Jagtap, Ray Sajulga, James Johnson, Praveen Kumar, Delphine Lariviere, Proteogenomics 2: Database Search (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/proteogenomics-dbsearch/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{proteomics-proteogenomics-dbsearch, author = "Subina Mehta and Timothy J. Griffin and Pratik Jagtap and Ray Sajulga and James Johnson and Praveen Kumar and Delphine Lariviere", title = "Proteogenomics 2: Database Search (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/proteogenomics-dbsearch/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Do you want to extend your knowledge?Follow one of our recommended follow-up trainings:
You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/proteomics/tutorials/proteogenomics-dbsearch/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: tabular_to_fasta owner: devteam revisions: 0a7799698fe5 tool_panel_section_label: FASTA/FASTQ tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: mz_to_sqlite owner: galaxyp revisions: 705821bf30d2 tool_panel_section_label: Convert Formats tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: peptideshaker owner: galaxyp revisions: 3ec27b4cee7c tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: peptideshaker owner: galaxyp revisions: c9b13d4069c8 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: peptideshaker owner: galaxyp revisions: c9b13d4069c8 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: query_tabular owner: iuc revisions: cf4397560712 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/