Proteogenomics 3: Novel peptide analysis
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to verify the spectra of novel proteoforms?
How to assign genomic allocation to these novel proteoforms?
Requirements:
How to assign and visualize the genomic localization of these identified novel proteoforms?
Time estimation: 30 minutesLevel: Intermediate IntermediateSupporting Materials:Published: Nov 20, 2018Last modification: May 15, 2025License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00233rating Rating: 5.0 (1 recent ratings, 10 all time)version Revision: 20
The third and the last workflow in the proteogenomics tutorial is to identifying the “Novel peptides” using BlastP and to localize the peptides to its genomic coordinates. Inputs from both workflow 1 and 2 will be used in this workflow. Please look at the following tutorials in this proteogenomics series before starting this tutorial:
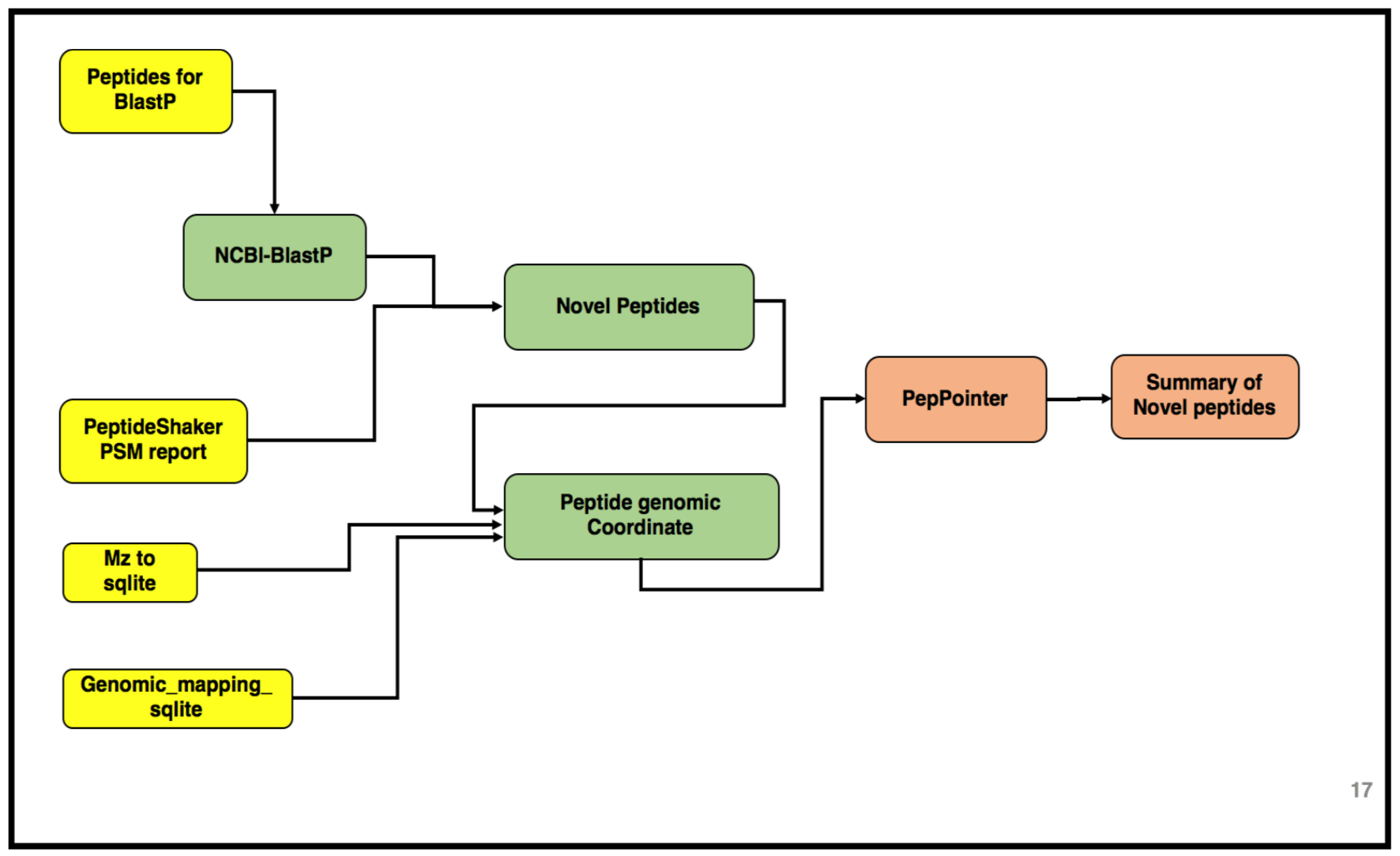
AgendaIn this tutorial, we will deal with:
Pretreatments
All the files to run this workflow can be obtained from the second tutorial output. Once the tabular output is generated, we convert this tabular report into a FASTA file. This can be achieved by using the Tabular to FASTA convertion tool.
Hands On: data organization
- The inputs for this workflow are:
- Fasta file – “Peptides for BlastP analysis” From (Proteogenomics 2: Database Search)
- Tabular file – “PeptideShaker_PSM” From (Proteogenomics 2: Database Search)
- Mz to sqlite From (Proteogenomics 2: Database Search)
- Genomic mapping sqlite From (Proteogenomics 1: Database Creation)
- Reference Annotation File From (Proteogenomics 1: Database Creation)
If you do not have these files from the previous tutorials in this series, you can import them from Zenodo
https://zenodo.org/records/15391695/files/Peptides_for_Blast-P_analysis.fasta https://zenodo.org/records/15390920/files/PeptideShaker_PSM.tabular https://zenodo.org/record/1489208/files/mz_to_sqlite.mz.sqlite https://zenodo.org/record/1489208/files/genomic_mapping_sqlite.sqlite https://zenodo.org/records/1489208/files/Mus_musculus.GRCm38.86.gtfVerify that the mz_to_sqlite file has the format
mz.sqlite
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select
mz.sqlitefrom “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
Peptide Selection
BLAST is a web-based tool used to compare biological sequences. BlastP, matches protein sequences against a protein database. More specifically, it looks at the amino acid sequence of proteins and can detect and evaluate the amount of differences between say, an experimentally derived sequence and all known amino acid sequences from a database. It can then find the most similar sequences and allow for the identification of known proteins or for the identification of potential peptides associated with novel proteoforms.
The first step in this tutorial is to perform BLAST-P analysis using the NCBI-NR database. The output from BLASTP will determine the identification of the novel peptides. The result is a tabular file with 25 columns containing all the information regarding the alignment of these peptides with the sequences in the NCBI-NR database.
Hands On: NCBI BLAST+ blastp
- NCBI BLAST+ blastp ( Galaxy version 2.16.0+galaxy0) with the following parameters:
- param-file Protein query sequence(s) -
Peptides for Blast-P analysis.fasta- Subject database/sequences -
Locally installed BLAST database
- Protein BLAST database -
NCBI-NR(dated)- Type of BLAST -
blast-p short- Set expectation value cutoff -
200000.0- Output format -
Tabular (extended 25 columns)- Advanced Options -
show advanced options
- Scoring matrix and gap costs -
PAM30
- Gap Costs -
Existence:9 Extension:1- Maximum hits to consider/show -
1- Maximum number of HSPs (alignments) to keep for any single query-subject pair -
1- Word size for wordfinder algorithm -
2- Multiple hits window size: use 0 to specify 1-hit algorithm, leave blank for default -
40- Minimum score to add a word to the BLAST lookup table -
11- Composition-based statistics -
0: no composition-based statistics- Click Run Tool and inspect the query results file after it turned green.
Once Blast-P search is performed, it provides a tabular output containing “Novel peptides”. Now this output is further processed by comparing the Novel Peptide output with the PSM report for selecting only distinct peptides which meet the criteria.
Hands On: Query Tabular
- Query Tabular ( Galaxy version 3.3.2) with the following parameters:
- param-repeat Insert Database Table
- “Tabular Dataset for Table” : Result of
blastp- Section Table Options
- “Specify Name for Table”:
blast- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
qseqid,sseqid,pident,length,mismatch,gapopen,qstart,qend,sstart,send,evalue,bitscore,sallseqid,score,nident,positive,gaps,ppos,qframe,sframe,qseq,sseq,qlen,slen,salltitles- “Only load the columns you have named into database”:
Yes- param-repeat Insert Table Index
- “This is a unique index”:
No- “Index on Columns”:
qseqid- param-repeat Insert Database Table
- “Tabular Dataset for Table” :
PeptideShaker_PSM- Section Filter Dataset Input
- param-repeat Filter Tabular Input Lines
- “Filter by”:
skip leading lines- “Skip lines”:
1- Section Table Options
- “Specify Name for Table”:
psm- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
ID,Proteins,Sequence,AAs_Before,AAs_After,Position,Modified_Sequence,Variable_Modifications,Fixed_Modifications,Spectrum_File,Spectrum_Title,Spectrum_Scan_Number,RT,mz,Measured_Charge,Identification_Charge,Theoretical_Mass,Isotope_Number,Precursor_mz_Error_ppm,Localization_Confidence,Probabilistic_PTM_score,Dscore,Confidence,Validation- “Only load the columns you have named into database”:
Yes“Save the sqlite database in your history”:
NoComment: Querying an SQLite DatabaseQuery Tabular can also use an existing SQLite database. Activating
Save the sqlite database in your historywill store the created database in the history, allowing to reuse it directly.- “SQL Query to generate tabular output”:
SELECT distinct psm.* FROM psm join blast ON psm.Sequence = blast.qseqid WHERE blast.pident < 100 OR blast.gapopen >= 1 OR blast.length < blast.qlen ORDER BY psm.Sequence, psm.IDComment: Query informationThe query wants a tabular list of peptides in which the lenght of the PSM sequence is equal to the length of the Blast sequence, where in the pident (percentage identity) is less that 100 i.e. Peptide cannot be a 100% identical to the NCBI-nr reference database. Or it should fulfill the criteria that there should be atleast 1 gap present (blast.gapopen >= 1) or the length of the peptide in NCBI-nr should be less than the length of the query length. If the peptide follows all this then it is accepted as a “Novel” proteoform.
- “Include query result column headers”:
YesClick Run Tool and inspect the query results file after it turned green.
- Rename the output as
PSM_Novel_Peptides
Once this step is completed, a tabular output containing novel proteoforms are displayed. These novel proteforms fulfill our criteria of not being present in the existing NCBI repository. The next step is to remove any duplicate sequences. For this, we use the Query tabular tool again to select distinct sequences from the tabular output.
Hands On: Query Tabular
- Query Tabular ( Galaxy version 3.3.2)
- param-repeat Insert Database Table
- “Tabular Dataset for Table” : Result of
Query Tabular- Section Filter Dataset Input
- param-repeat Insert Filter Tabular Input Lines
- “Filter by”:
skip leading lines- “Skip lines”:
1- Section Table Options
- “Specify Name for Table”:
psm- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
ID,Proteins,Sequence- “Only load the columns you have named into database”:
Yes- “SQL Query to generate tabular output”:
SELECT distinct Sequence from psm- “include query result column headers”:
YesClick Run Tool and inspect the query results file after it turned green.
- Rename the output as
Novel Peptides
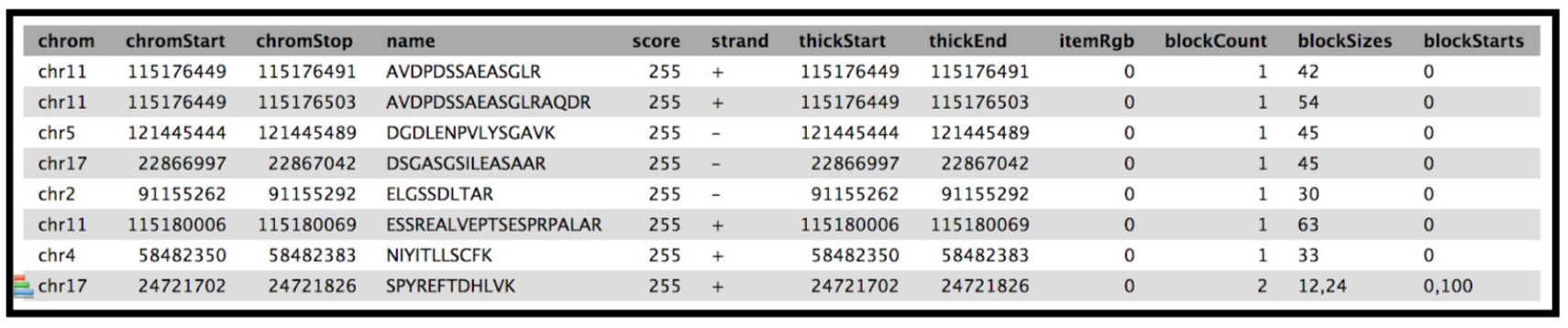
The next tool in the workflow is the Peptide genomic coordinate tool which takes the “novel peptides” as the input along with the mztosqlite file and the genomic mapping sqlite file (obtained during creation of the database). This tool helps create a bed file with the genomic coordinate information of the peptides based on the sqlite files.
Obtain Peptide genomic Coordinates
Gets genomic coordinate of peptides based on the information in mzsqlite and genomic mapping sqlite files. This program loads two sqlite databases (mzsqlite and genomic mapping sqlite files) and calculates the genomic coordinates of the peptides provided as input. This outputs bed file for peptides.
Hands On: Peptide genomic Coordinate
- Run Peptide genomic Coordinate ( Galaxy version 1.0.0) with the following parameters:
“Input”:
Novel Peptides,mzsqlite sqlite DB file, andgenomic mapping sqlite DB file
- Click Run Tool and inspect the resulting files
Multiomics Visualization Platform (MVP)
The Multiomics Visualization Platform is a Galaxy visualization plugin that allows the user to browse the selected proteomics data. It uses the SQlite database which allows the data to be filtered and aggregated in a user-defined manner. It allows various features such as; the PSM can be displayed with a lorikeet spectral view, the selected peptide can be displayed in a protein view and an IGV browser is also available for the selected protein. The step-by-step guide shown below will provide a walkthrough on how to use this plugin (NOTE: the example shown below is a representative peptide that is subjected to change, so while you are running this tool please take a look at the “Novel Peptide” output from the previous steps).
Hands On: Guide to MVPThe spectra belonging to these “Novel peptides” can be viewed using MVP, this can be achieved by selecting the output from the
mz to sqlite tool(Generated in the second workflow). Make sure the database associated with the dataset ismm10Here is a step-by-step guide to obtain the proteogenomic view of the “Novel peptides”.
Click on the Visualize in MVP application, it will open up options for visualization application in the center pane, Select MVP Application from the options (or Right-click to open in a new window).
This will open in the Center Pane. Select the MVP application.
This is how it will look.
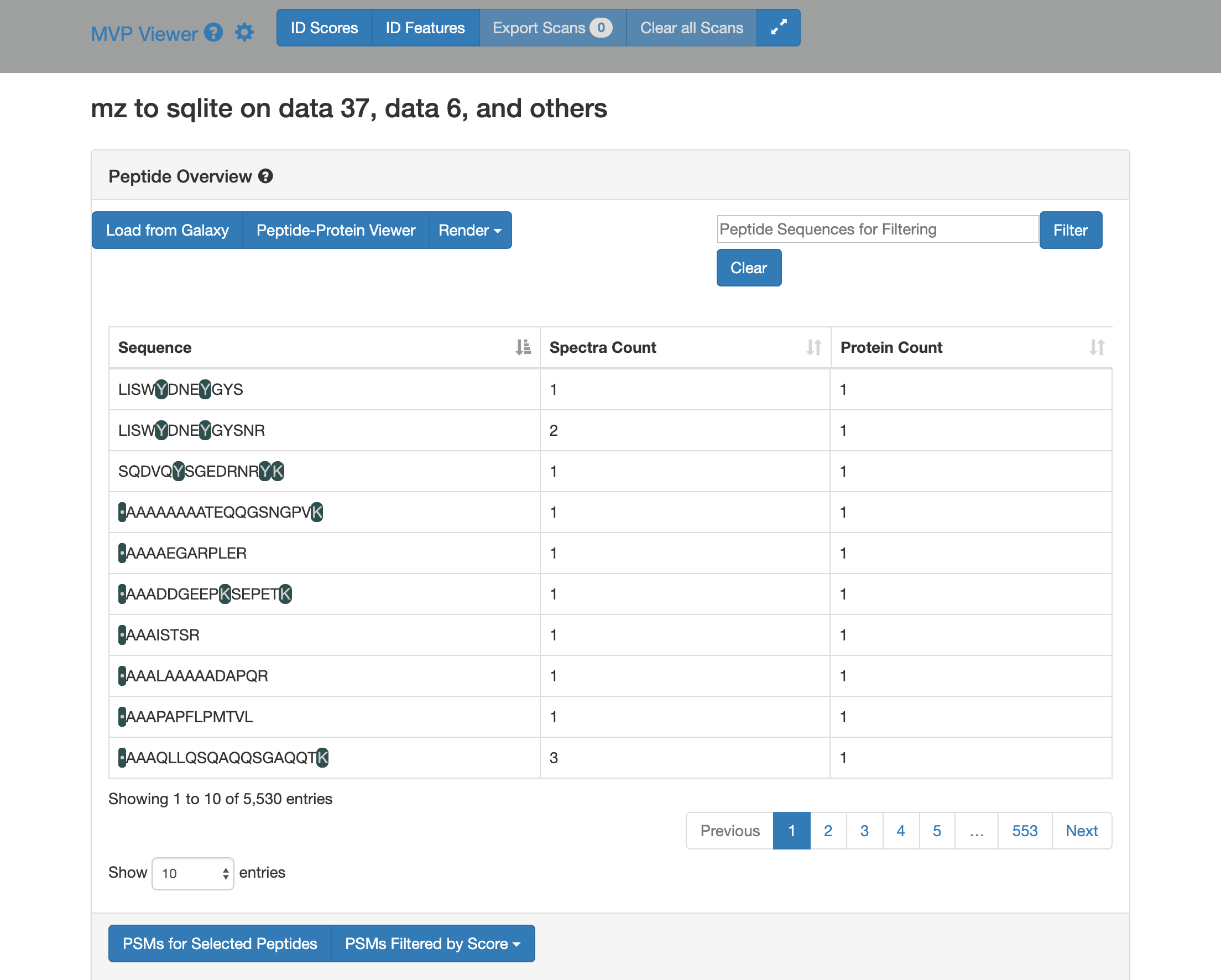
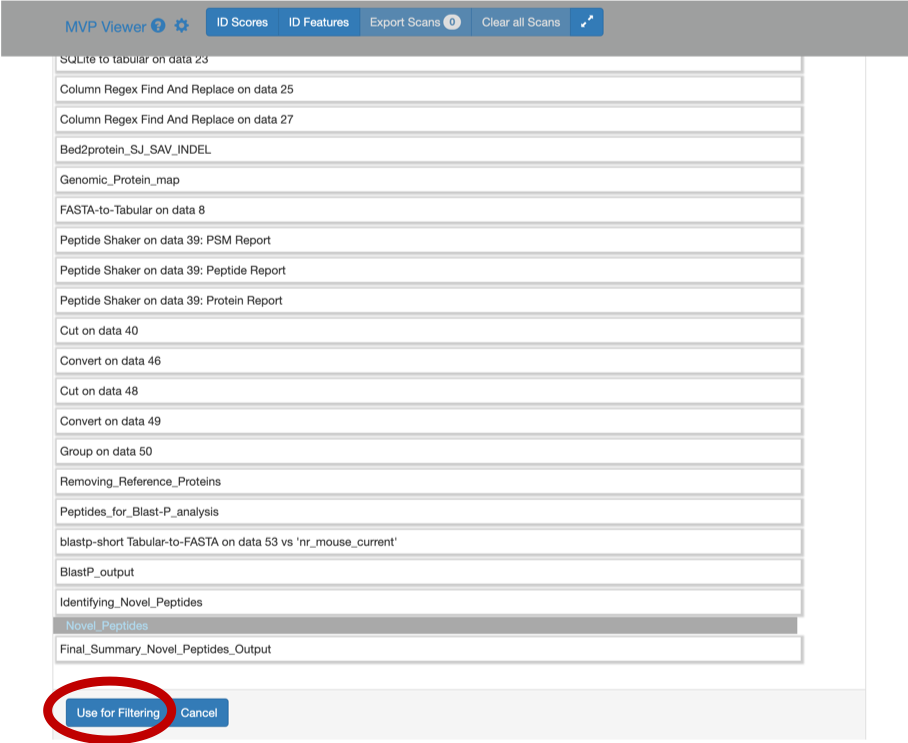
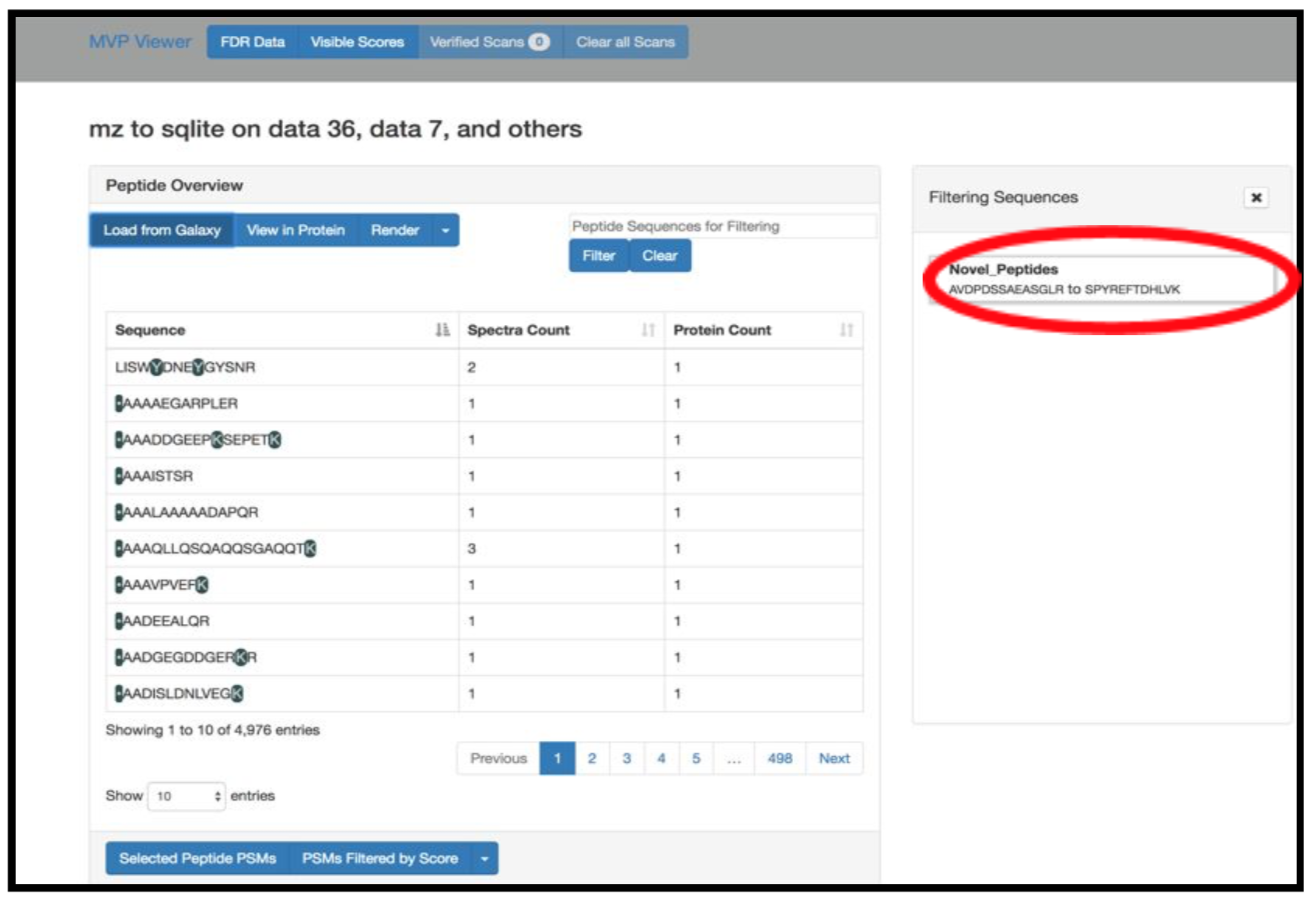
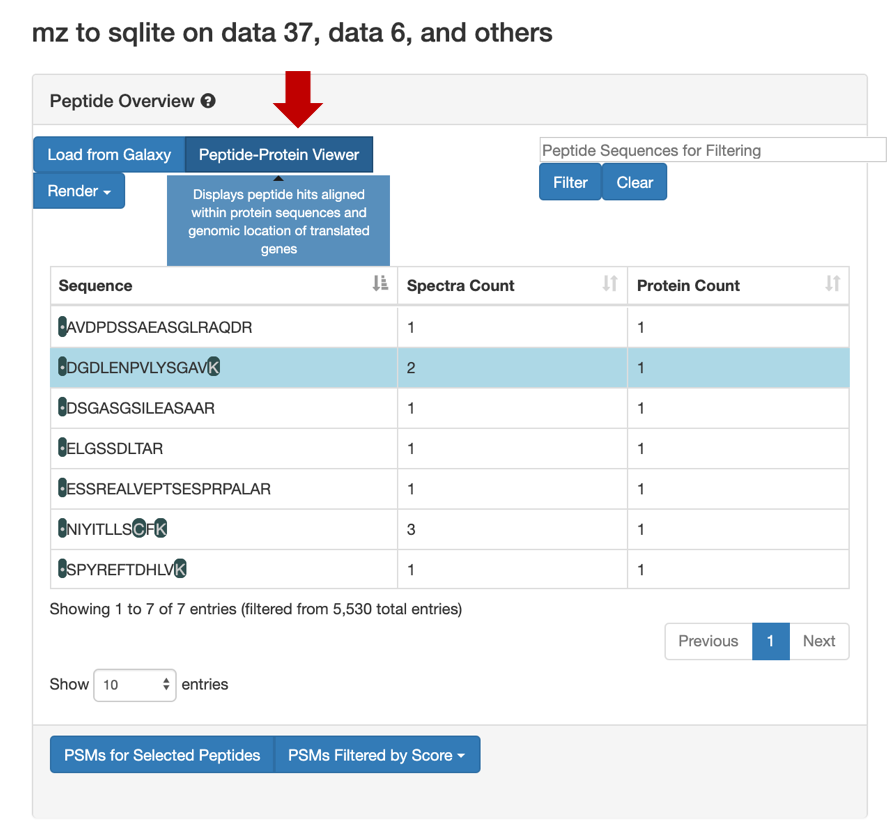
Click on Load from Galaxy to open the list of peptides you would like to view.
This will open a dropdown list. Select the novel peptides from there.
Select Novel Peptides from the right hand side.
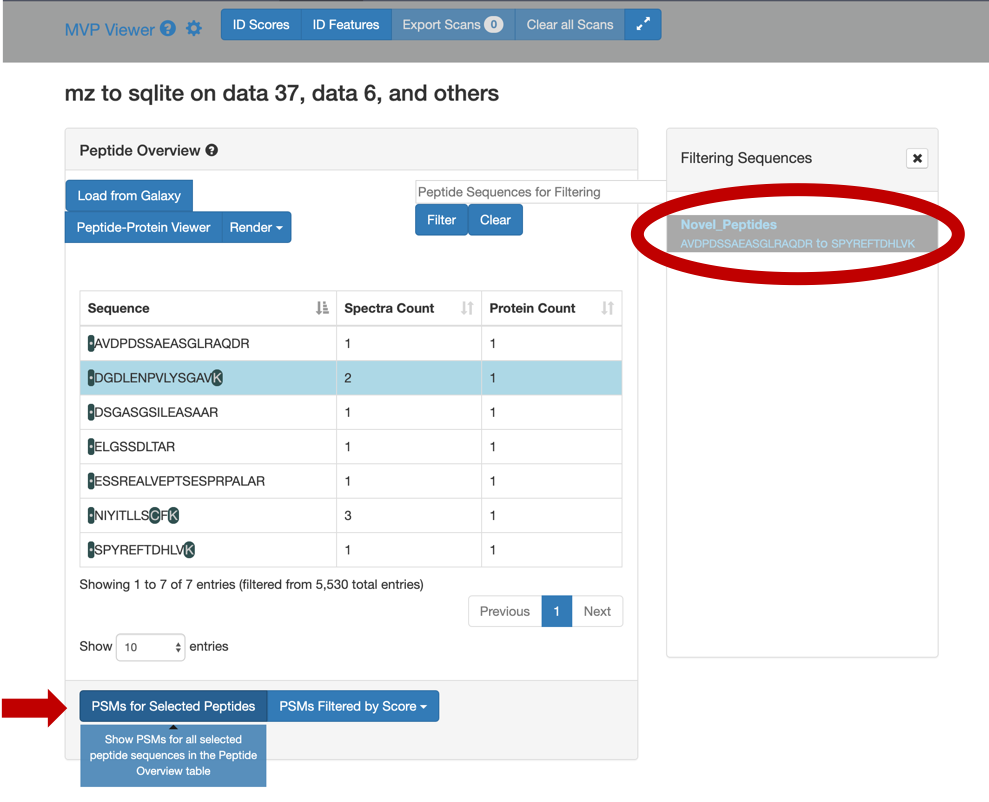
Select any peptide, For eg:
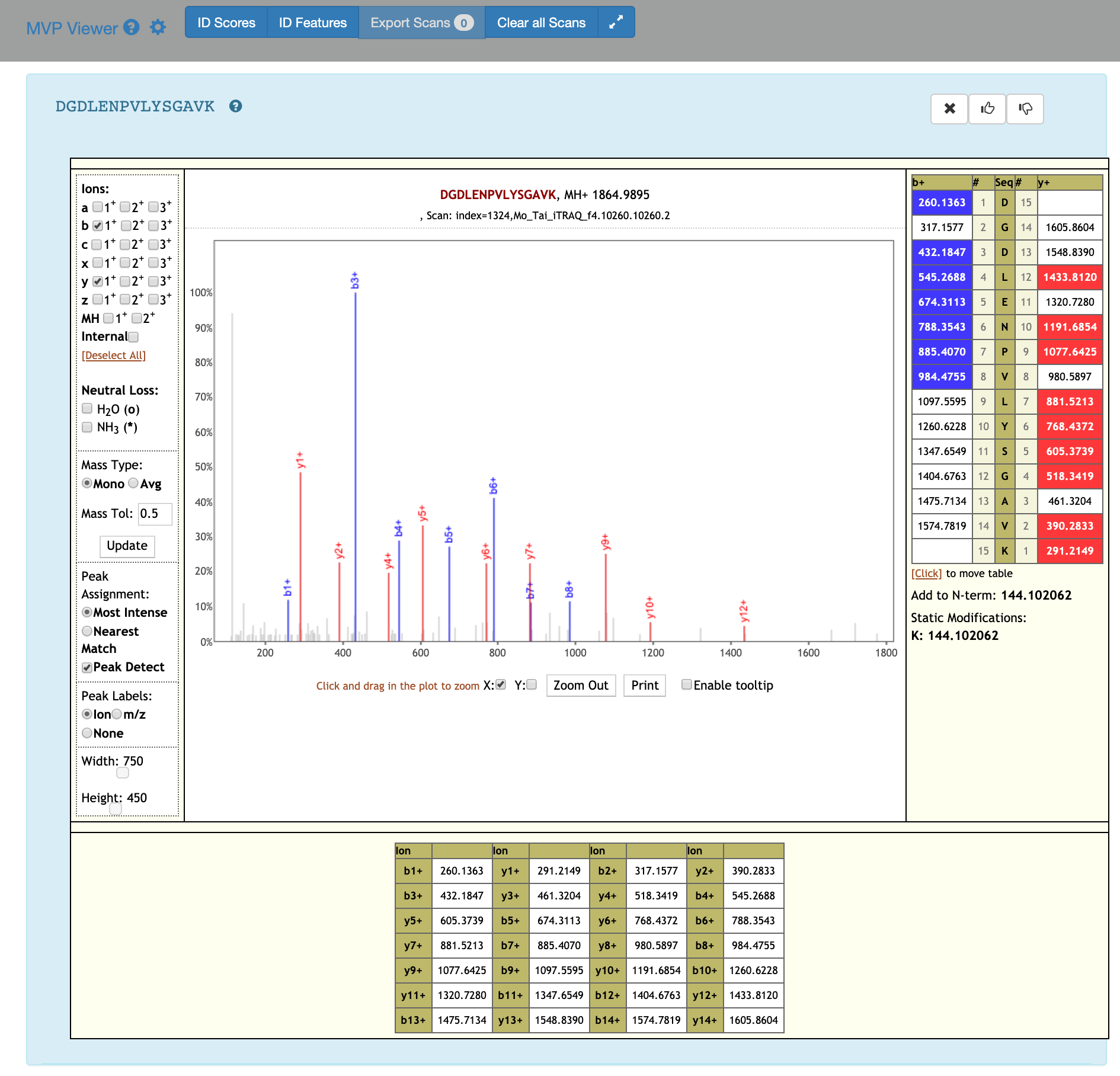
DGDLENPVLYSGAV, and then click on PSMs for Selected Peptide.
If you scroll down, the PSM associated with the peptide will be displayed. By clicking on the PSM, the Lorikeet values will be shown. The Lorikeet visualization is interactive, i.e the user can change the values or select any parameter and click on Update button to view these changes.
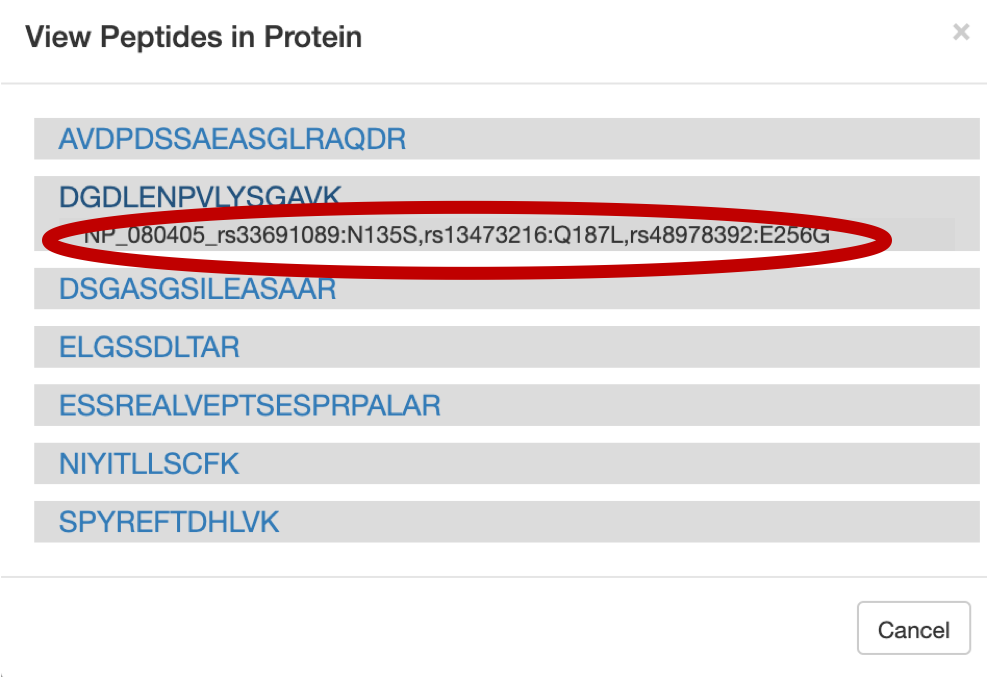
For a Protein centric view, click on View in Protein , it will open up all the proteins associate with the peptides. For eg: Select the
DGDLENPVLYSGAVpeptide and click on the first protein. The chromosome location of the peptide will be displayed.
Once you click on protein it will show the list of proteins the belongs to the peptides.
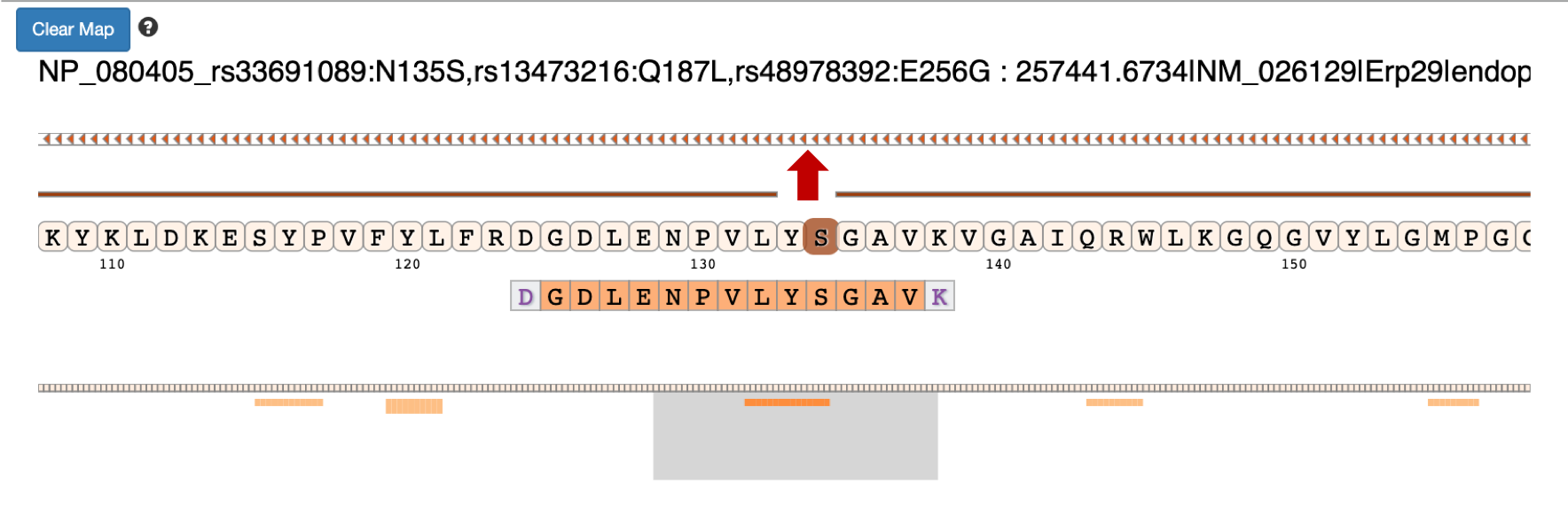
Once you select the protein that you want to visualize you can click on the protein view.
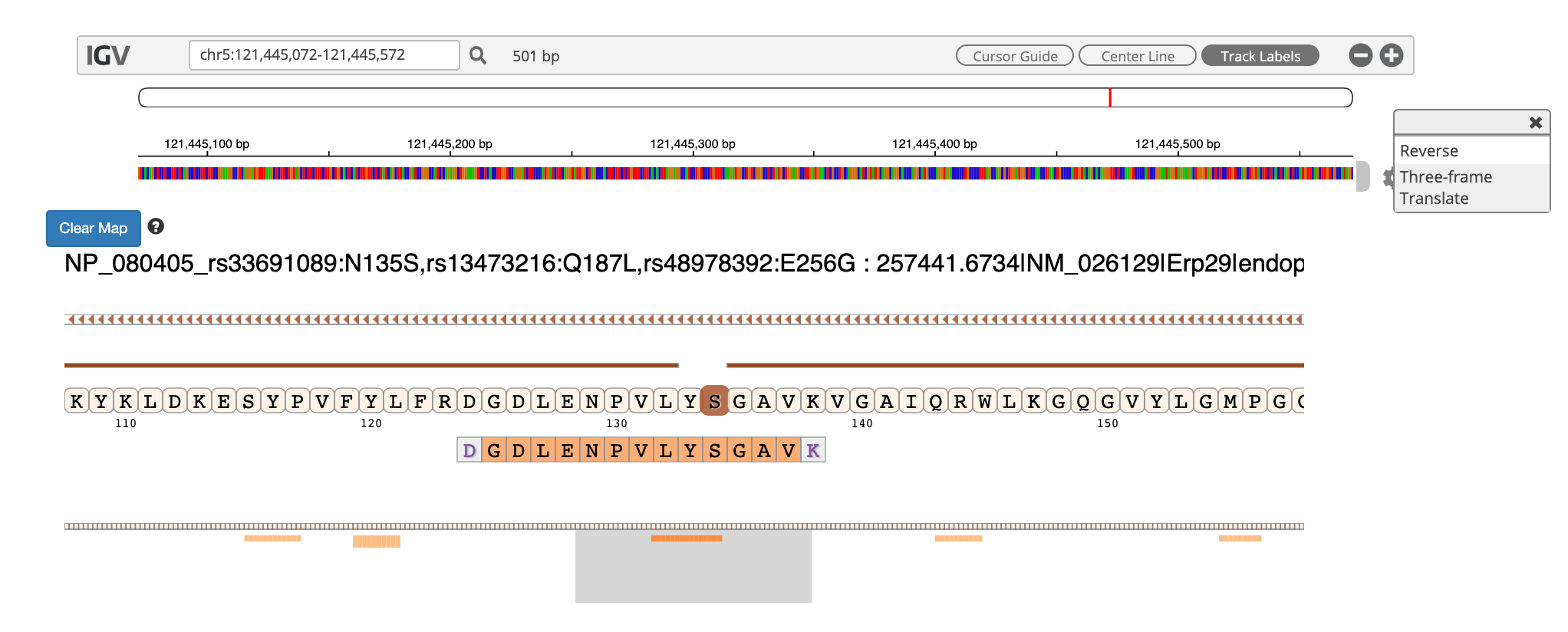
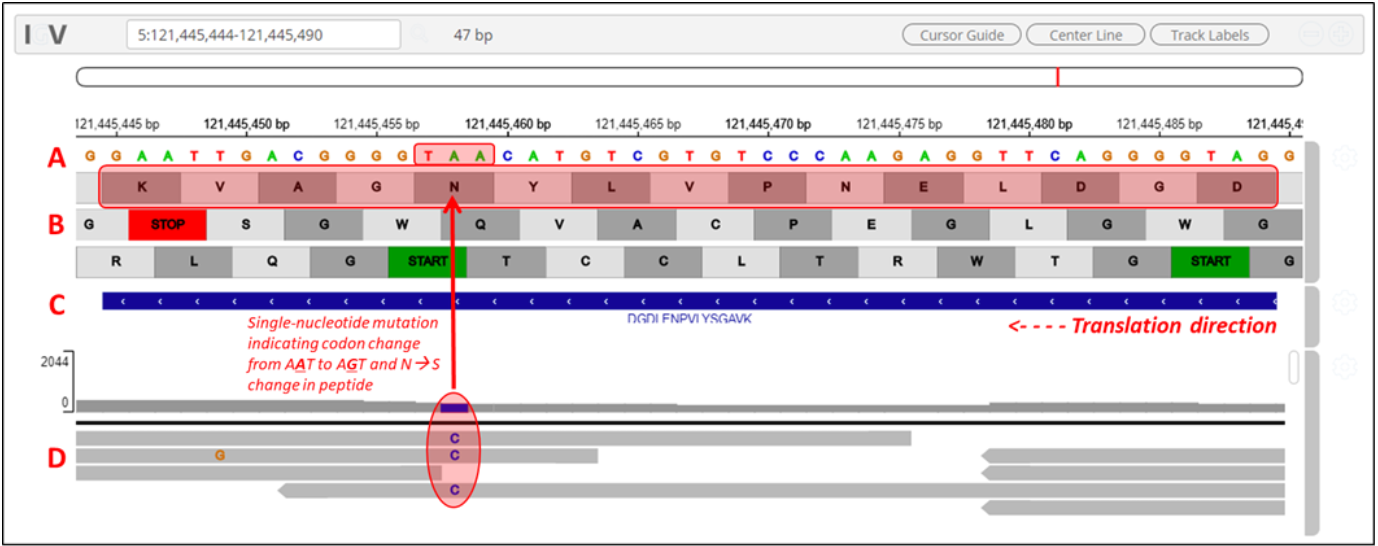
Clicking on the arrow marks will open up the IGV(js) visualization tool, where-in the genomic localization of the peptide will be displayed.
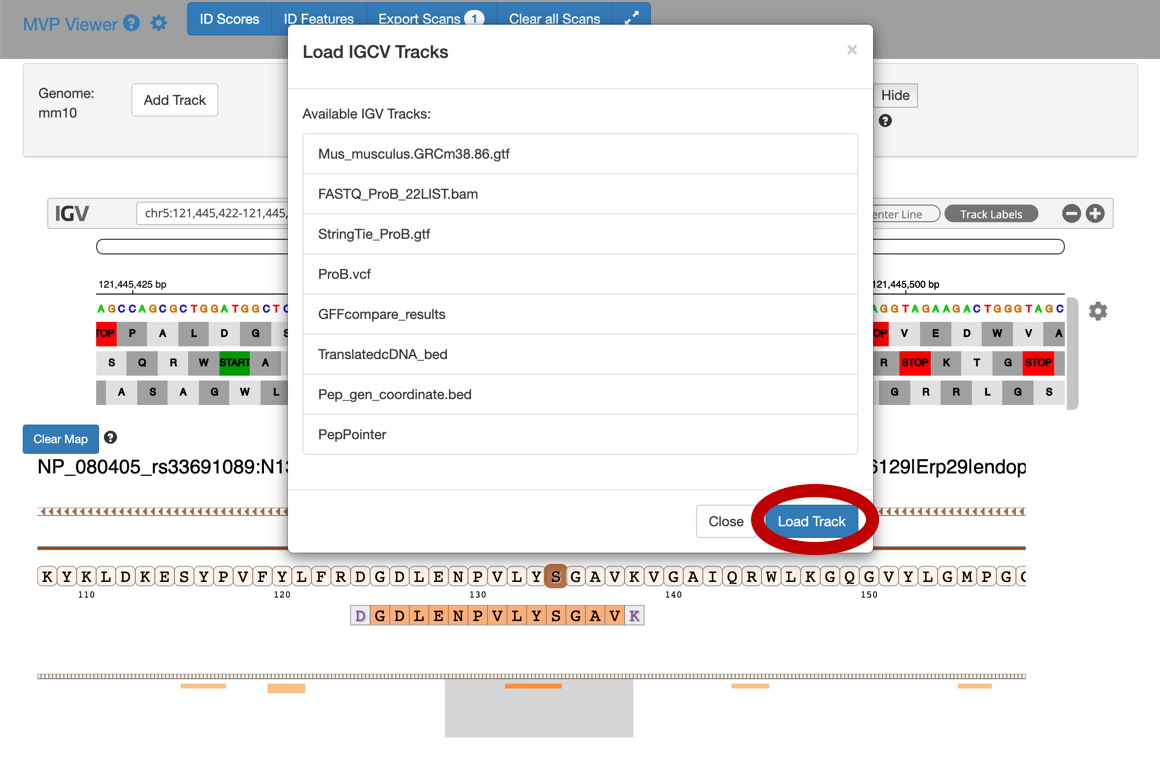
To add tracks to your IGV viewer, click on Add Track. This will open up a list of tracks that are compatible to view in your IGV viewer. For eg. Select the
Pep_gen_coordinate.bedfile and then click on Load Track. This will open up the bed will below the nucleotide sequence.
By clicking the wheel, you can select the three frame translate which will show the three frame translated region of your sequence.
The IGV is inbuilt in the MVP viewer and is very interactive, you could also load more tracks such as the aligned proBAM file (from HISAT) or the identified probam file (one of the input file). MVP has many useful features beyond those covered in this workshop and is under active development.



Classify Peptides
Given chromosomal locations of peptides in a BED file, PepPointer classifies them as CDS, UTR, exon, intron, or intergene.
Hands On: Peppointer
- Peppointer ( Galaxy version 0.1.3) with the following parameters:
- param-select “Choose the source of the GTF file” -
From History- param-file “GTF file with the genome of interest” -
Mus_musculus.GRCm38.86.gtf- param-file “BED file with chromosomal coordinates of peptides”:
Bed file from Peptide genomic coordinate tool- Click Run Tool and inspect the query results file after it turned green.
This tool provides a bed output with the classification of the genomic location of the peptides.The Mus-musculus GTF file will be in your history if you have completed the proteogenomics 1 tutorial.
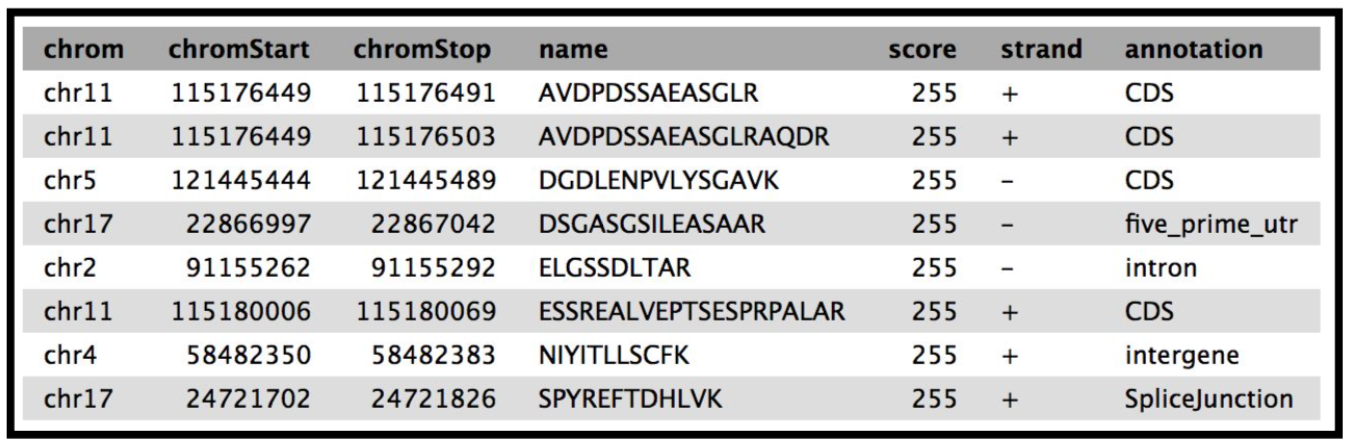
The final tool for this workflow generates a tabular output that summarizes the information after running these workflows. The final summary output consists of the Peptide sequence, the spectra associated with the peptides, the protein accession number, the chromosome number, Start and Stop of the genomic coordinate, the annotation, the genomic coordinate entry for viewing in Integrative Genomics Viewer (IGV), MVP or UCSC genome browser and the URL for viewing it on UCSC genome browser. This summary is created with the help of the query tabular tool.
Final Summary Output
Hands On: Query Tabular
- Query Tabular ( Galaxy version 3.3.2)
- param-repeat Insert Database Table
- Section Table Options:
- “Specify Name for Table”:
bed_pep_pointer- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
chrom,start,end,peptide,score,strand,annot- “Only load the columns you have named into database”:
No- param-repeat Insert Database Table
- Section Filter Dataset Input
- param-repeat Insert Filter Tabular Input Lines
- “Filter by”:
skip leading lines- “Skip lines”:
1- Section Table Options
- “Specify Name for Table”:
psm- “Use first line as column names” :
No- “Specify Column Names (comma-separated list)”:
ID,Proteins,Sequence,AAs_Before,AAs_After,Position,Modified_Sequence,Variable_Modifications,Fixed_Modifications,Spectrum_File,Spectrum_Title,Spectrum_Scan_Number,RT,mz,Measured_Charge,Identification_Charge,Theoretical_Mass,Isotope_Number,Precursor_mz_Error_ppm,Localization_Confidence,Probabilistic_PTM_score,Dscore,Confidence,Validation- “Only load the columns you have named into database”:
No- “SQL Query to generate tabular output”:
SELECT psm.Sequence AS PeptideSequence, count(psm.Sequence) AS SpectralCount, psm.Proteins AS Proteins, bed_pep_pointer.chrom AS Chromosome, bed_pep_pointer.start AS Start, bed_pep_pointer.end AS End, bed_pep_pointer.strand AS Strand, bed_pep_pointer.annot AS Annotation, bed_pep_pointer.chrom||':'||bed_pep_pointer.start||'-'||bed_pep_pointer.end AS GenomeCoordinate, 'https://genome.ucsc.edu/cgi-bin/hgTracks?db=mm10&position='||bed_pep_pointer.chrom||'%3A'||bed_pep_pointer.start||'-'||bed_pep_pointer.end AS UCSC_Genome_Browser FROM psm INNER JOIN bed_pep_pointer on bed_pep_pointer.peptide = psm.Sequence GROUP BY psm.Sequence- “include query result column headers”:
YesClick Run Tool and inspect the query results file after it turns green. If everything goes well, it should look similar:
Rename output as
Final_Summary_Novel_Peptides
The Final summary displays a tabular output containing the list of novel peptides and its corresponding protein. It also provides the users with the chromosomal location of the novel proteoform along with the peptide’s start and end position. The output also features the strand information, gene annotation and the genomic coordinates in a specific format that could be used on IGV or UCSC browser. It also provides the user with a UCSC Genome Browser link, which the user can directly copy and paste it on a web browser to learn more about the novel proteoform. Here we are demonstrating the use of proteogenomics workflow on an example trimmed mouse dataset. This study explores the possibilities for downstream biological /functional analysis of peptides corresponding to novel proteoforms.

Conclusion
This completes the proteogenomics workflow analysis. This training workflow uses mouse data. For any other organism, the data, tool parameters and workflow will need to be modified accordingly. This workflow is also available at usegalaxy.eu. All the tools are in the most stable version here (published in 2018), the tools are subject to changes and upgrades, hence there could be minor formatting that would be required.
This workflow was developed by the Galaxy-P team at the University of Minnesota. For more information about Galaxy-P or our ongoing work, please visit us at galaxyp.org
You've Finished the Tutorial
Key points
Learning how to visualize proteomic data and to perform its genomic allocation
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Subina Mehta, Timothy J. Griffin, Pratik Jagtap, Ray Sajulga, James Johnson, Praveen Kumar, Proteogenomics 3: Novel peptide analysis (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/proteogenomics-novel-peptide-analysis/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{proteomics-proteogenomics-novel-peptide-analysis, author = "Subina Mehta and Timothy J. Griffin and Pratik Jagtap and Ray Sajulga and James Johnson and Praveen Kumar", title = "Proteogenomics 3: Novel peptide analysis (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/proteogenomics-novel-peptide-analysis/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Do you want to extend your knowledge?Follow one of our recommended follow-up trainings:
You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/proteomics/tutorials/proteogenomics-novel-peptide-analysis/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: ncbi_blast_plus owner: devteam revisions: fc35ffc8c548 tool_panel_section_label: NCBI Blast tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: pep_pointer owner: galaxyp revisions: 073a2965e3b2 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: pep_pointer owner: galaxyp revisions: a6282baa8c6f tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: peptide_genomic_coordinate owner: galaxyp revisions: cb0378d2d487 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: query_tabular owner: iuc revisions: cf4397560712 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/