SARS-CoV-2 Viral Sample Alignment and Variant Visualization
| Author(s) |
|
| Editor(s) |
|
| Reviewers |
|
| Infrastructure |
|
OverviewQuestions:
Objectives:
How do I check my data quality?
How do I put together my dataset of fragmented sequences into a full sequence?
How do I visually explore the variants in my SARS-CoV-2 sample?
Requirements:
Gather and evaluate experimental evidence, including qualitative and quantitative data
Generate and interpret graphs displaying experimental results
Critique large data sets and use bioinformatics to assess genetics data
Tap into the interdisciplinary nature of science
Time estimation: 1 hourLevel: Introductory IntroductorySupporting Materials:Published: Jul 10, 2023Last modification: Feb 29, 2024License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00356version Revision: 2
There is a growing need for undergraduate students to learn cutting-edge concepts in genomics data science, including performing analysis on the cloud instead of a personal computer.
This lesson aims to introduce a mutant detection bioinformatics pipeline based on a publicly available genetic sample of SARS-CoV-2. Students will be introduced to the sequencing revolution, variants, genetic alignments, and essentials of cloud computing prior to the lab activity. During the lesson, students will work hands-on with the point-and-click Galaxy interface on the AnVIL cloud computing resource to check data, perform an alignment, and visualize their results.
AgendaIn this tutorial we will deal with:
Background Concepts
What is a Variant?
This lecture module introduces genetic variants. It provides several examples of genetic variants, background on the structure of DNA, and a review of the “Central Dogma” of molecular biology - the process of turning DNA into RNA into protein.
Learning Objectives
- Answer “what is a genetic variant?”
- Learn about the molecular structure of a variant

The Sequencing Revolution
This lecture module introduces the history of the sequencing revolution. It highlights the enormous proliferation of genomic data that has accompanied the rapidly growing technology. It also suggests opportunities for careers in genomics, as well as an in-depth look at how some sequencing technologies actually work.
Learning Objectives
- Learn the history the sequencing revolution
- Introduce the sequencing workforce
- Explore the evolution of sequencing technology

Alignments
This lecture module introduces the structure of genomic data and how alignments work. It touches on the “shredded book” analogy, demonstrates how short chunks of data can be compared to find variation, and reviews data files needed for alignments, including reference genomes and read data. It also reviews some diverse applications of variant detection made possible via alignment tools.
Learning Objectives
- Learn about data as “reads” & shredded books
- Become familiar with reference genomes and alignments
- Explore the file structure of genomic data and quality scoring

Cloud Computing
This lecture module introduces cloud computing and computing architecture. It reviews the utility of cloud computing for genomics and also highlights how all modules of this activity fit together.
Learning Objectives
- Learn about different types of computers
- Answer the question “What is cloud computing?”
- Learn about cloud computing for genomics
- Revisit the big picture, from variants to alignments

Overview
This overview video introduces the lab activity. It briefly reviews some of the essential background for the activity, highlights key areas to focus on for activity assessment questions, and provides a detailed walk-through of the steps - from starting AnVIL and Galaxy to browsing the genome and shutting down the cloud computing instance.
Learning Objectives:
- Review lecture content
- Review big steps in the analysis
- Cover the setup on AnVIL in detail

Set Up
In the next few steps, you will walk through how to get set up to use Galaxy on the AnVIL platform. AnVIL is centered around different “Workspaces”. Each Workspace functions almost like a mini code laboratory - it is a place where data can be examined, stored, and analyzed. The first thing we want to do is to copy or “clone” a Workspace to create a space for you to experiment.
CommentBecause AnVIL runs on a commerical cloud provider, you will need to have set up billing for yourself or through your institution to follow along with this exercise, or you will need to be added to a billing account created for a training event.
Learn more about options for creating billing accounts at this link: https://jhudatascience.org/AnVIL_Book_Getting_Started/overview-pis.html.
- At this point, it might make things easier to open up a new window in your browser and split your screen. That way, you can follow along with this guide on one side and execute the steps on the other.
Hands On: Clone the Workspace
- Use a web browser to go to the AnVIL website. In the browser type:
anvil.terra.bio. Log into AnVIL.- Click “View Workspaces”.
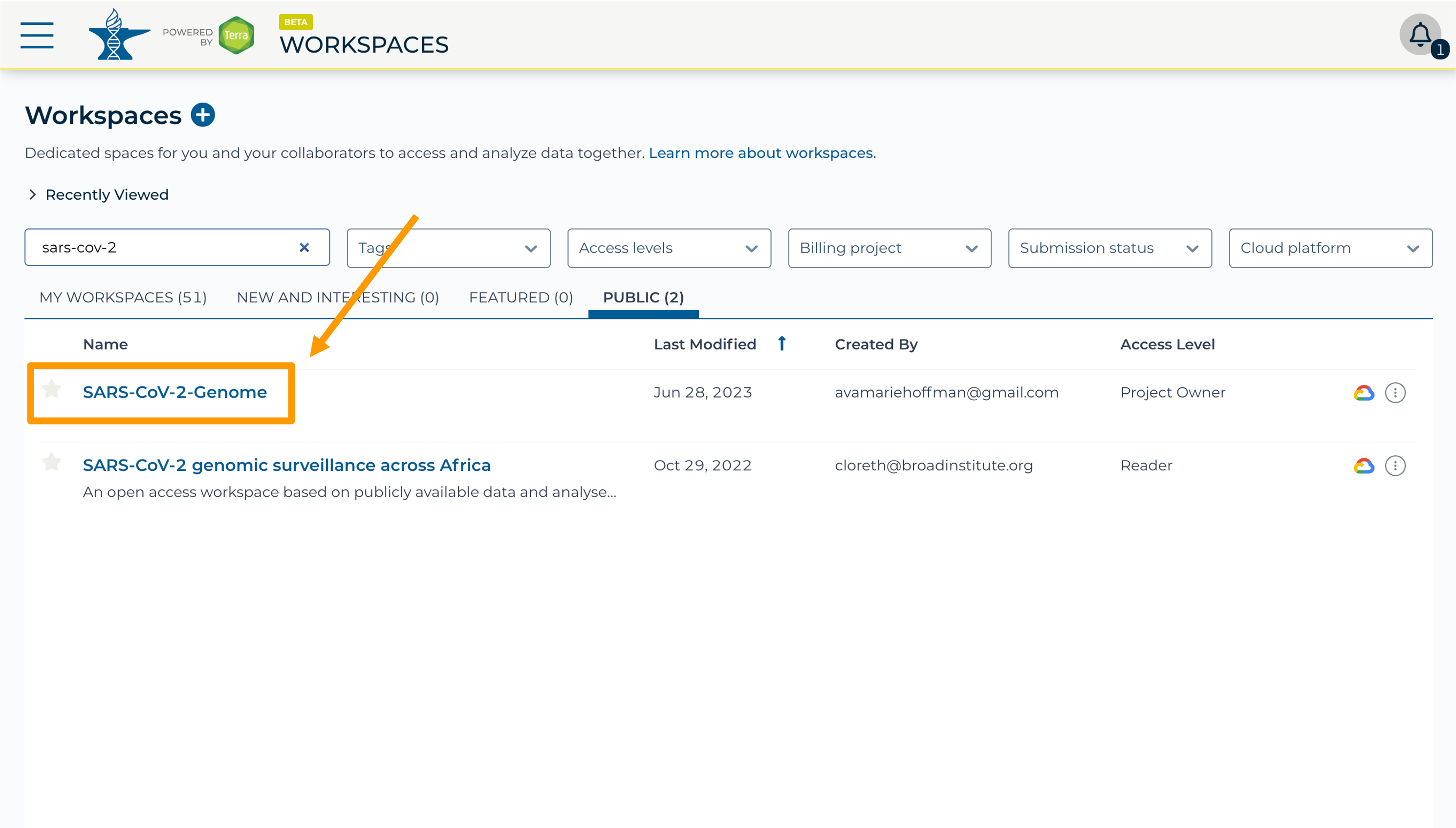
- Select the “Public” tab.
- In the top search bar type the activity workspace
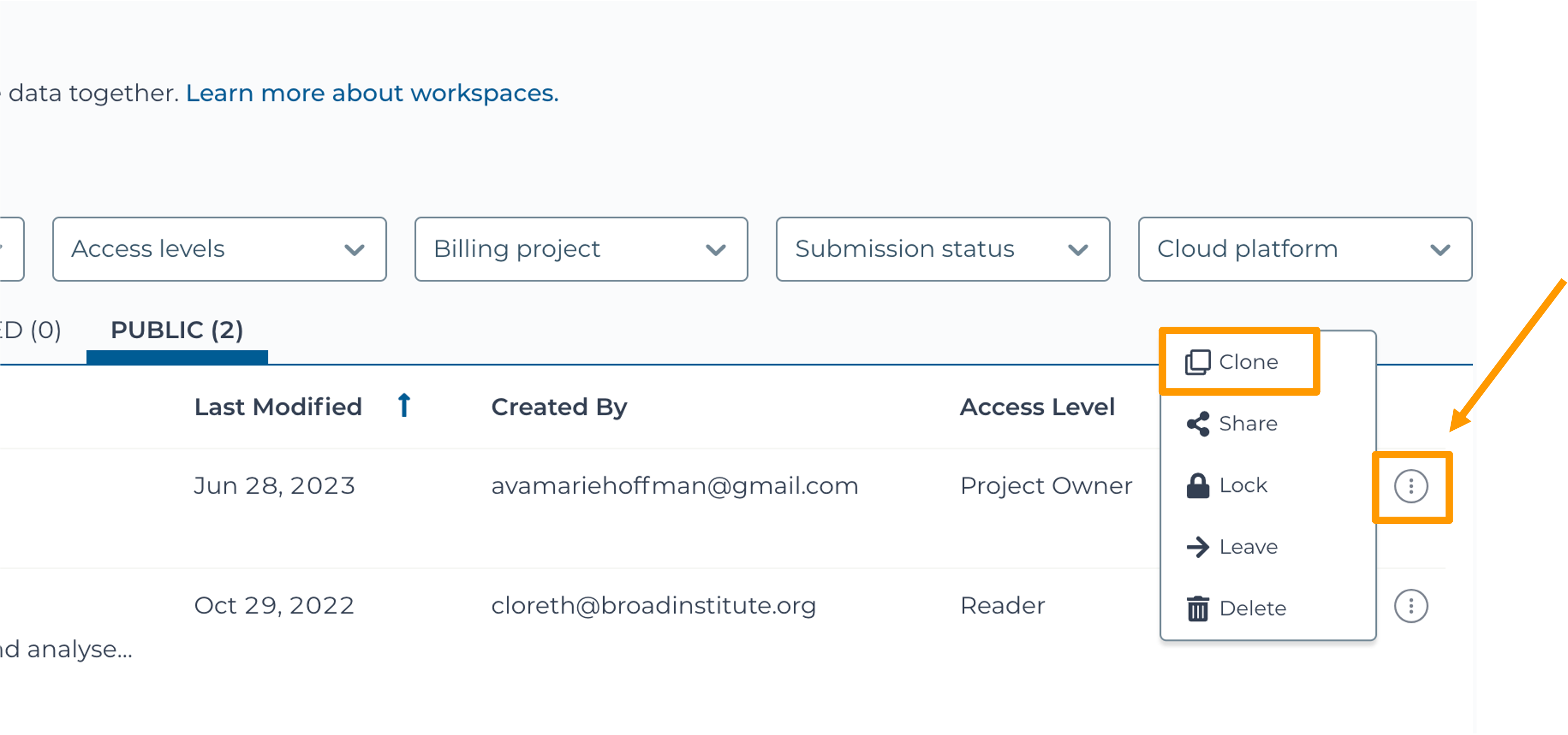
SARS-CoV-2-Genome. You can also go directly to the following link: https://anvil.terra.bio/#workspaces/gdscn-exercises/SARS-CoV-2-Genome.- Clone the workspace by clicking the teardrop button and selecting “Clone”.
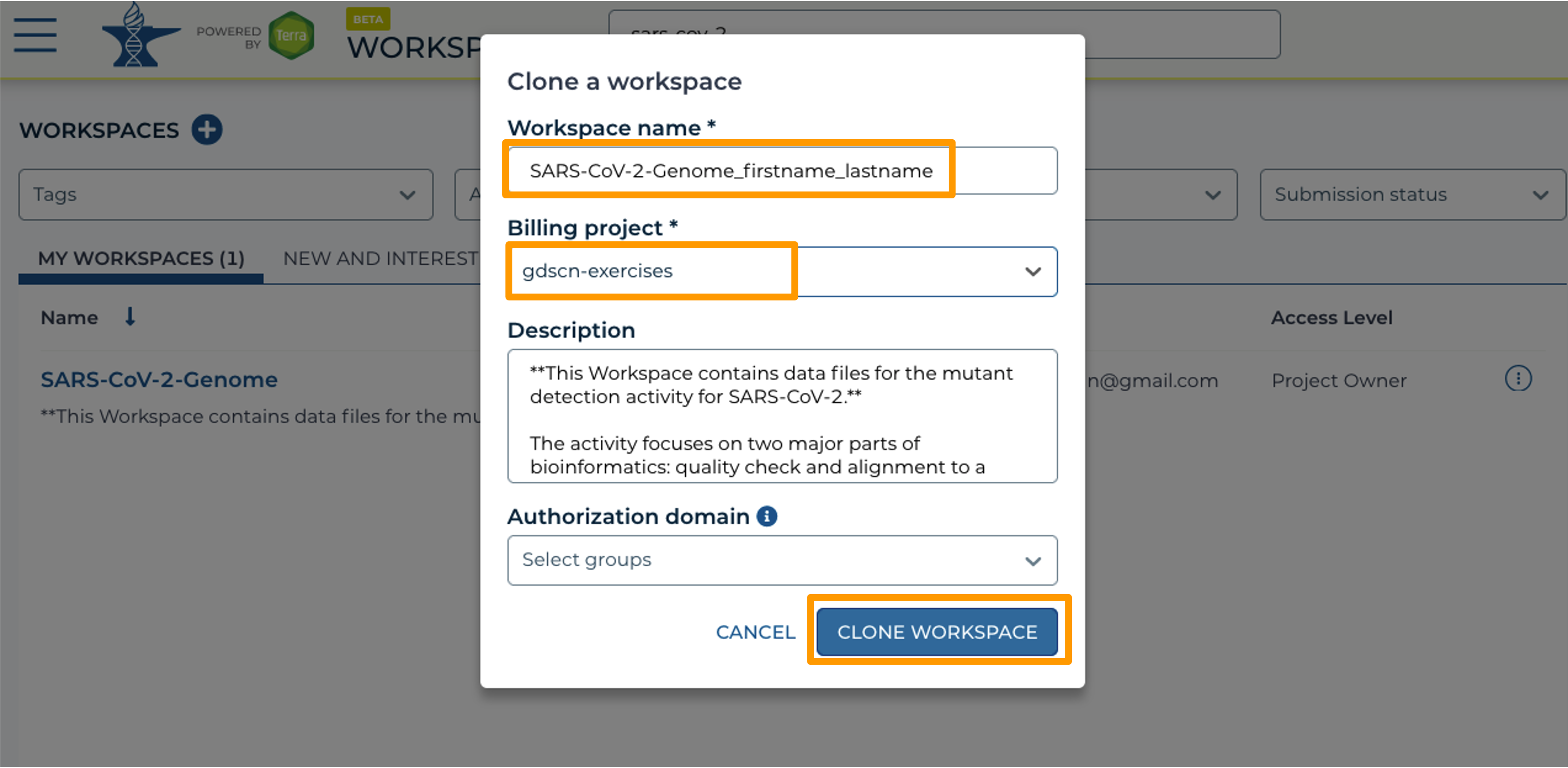
- In the new window, give your Workspace clone a name by adding an underscore (“_”) and your name.
- Next, select the Billing project provided by your instructor.
- Leave the Description and Authorization Domain boxes as-is.
- Click “CLONE WORKSPACE”.
Starting Galaxy
Galaxy is a great tool for performing bioinformatics analysis without having to update software or worry too much about coding. In order to use Galaxy, we need to create a cloud environment. This is like quickly renting a few computers from Google as the engine to power our Galaxy analysis.
Warning: Internet BrowserGoogle Chrome is the most recommended browser to use AnVIL Galaxy cloud environments to operate as expected. Safari and Firefox may be used as well, though there may be some functionality that is not supported in these or other browsers.
Hands On: Clone the Workspace
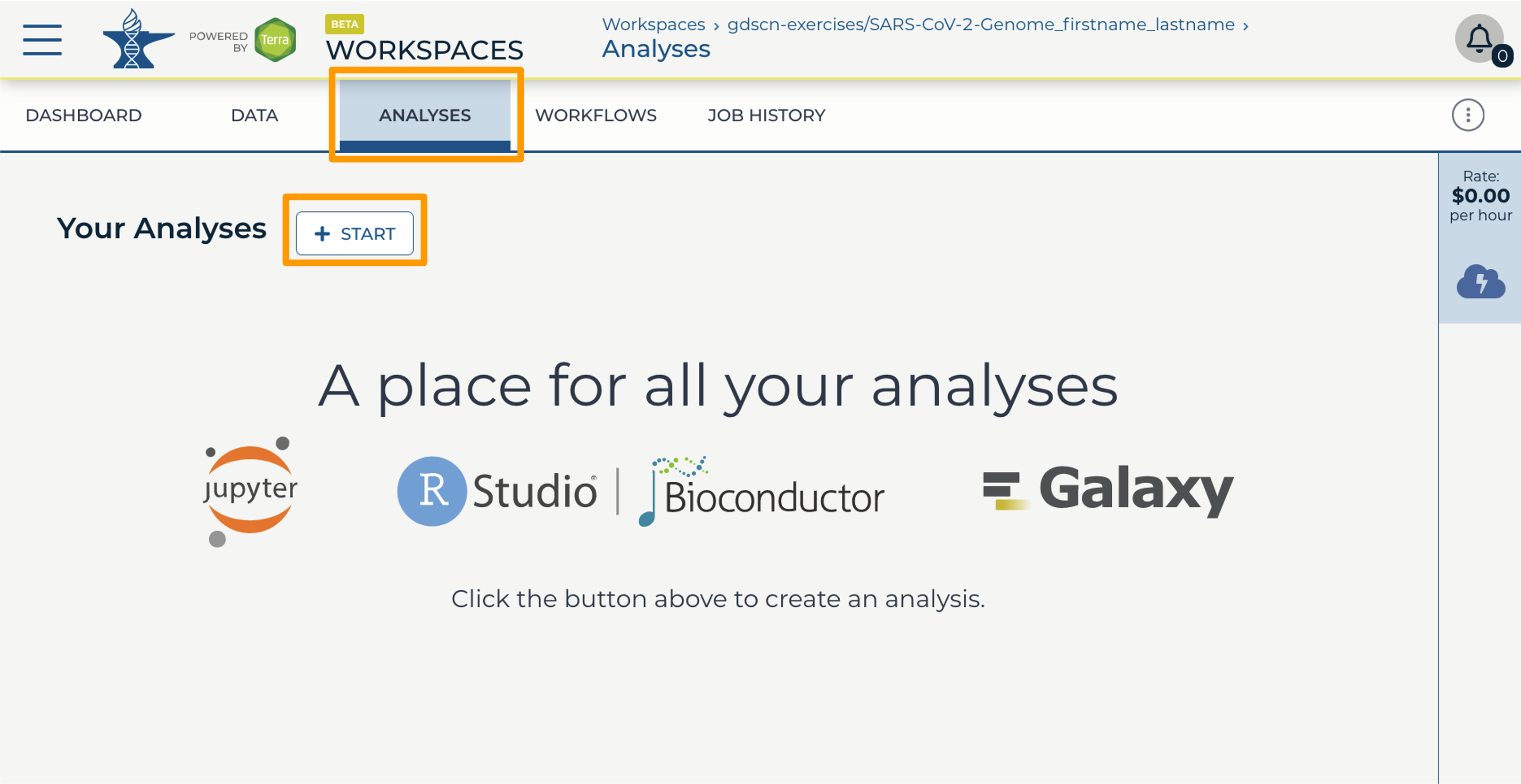
- In your new Workspace, click on the “ANALYSES” tab. Next, click on “START”. You should see a popup window on the right side of the screen.
- Click on the Galaxy logo to proceed.
- Click on “NEXT” and “CREATE” to keep all settings as-is.
- Click on the Galaxy icon. You will see that the environment is still being set up. This will take 8-10 minutes.
- When it is done, click “Open”. You might need to refresh the page.
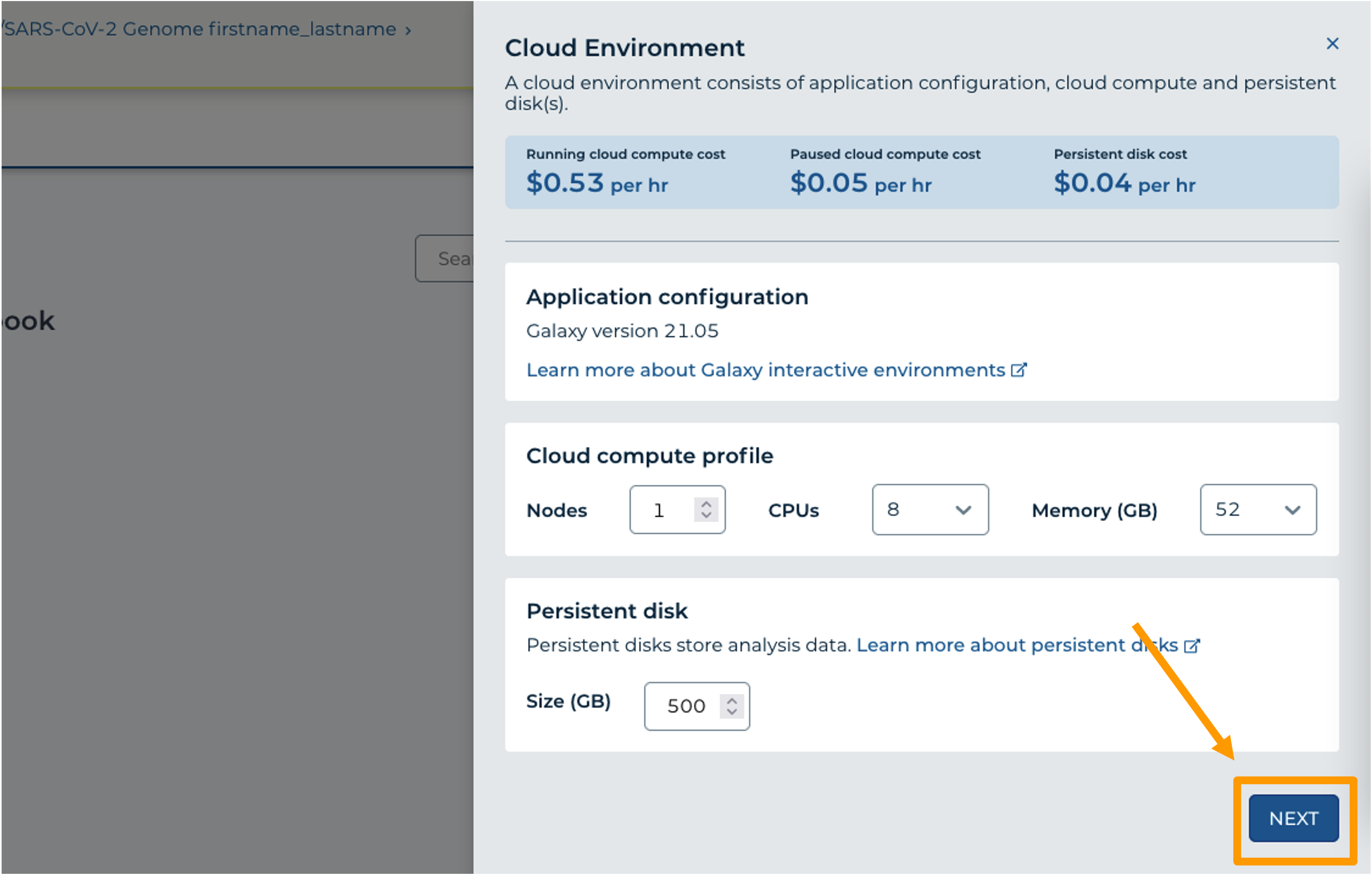


Remember that you can refresh your browser or navigate away at any time. This is because the connection to the environment is in the cloud, not on your personal computer.
You can also follow along with the first ~2 minutes of this video to start Galaxy on AnVIL.
Navigating Galaxy
Notice the three main sections.
Tools - These are all of the bioinformatics tool packages available for you to use.
The Main Dashboard - This contains flash messages and posts when you first open Galaxy, but when we are using data this is the main interface area.
History - When you start a project you will be able to see all of the documents in the project in the history. Now be aware, this can become very busy. Also the naming that Galaxy uses is not very intuitive, so you must make sure that you label your files with something that makes sense to you.
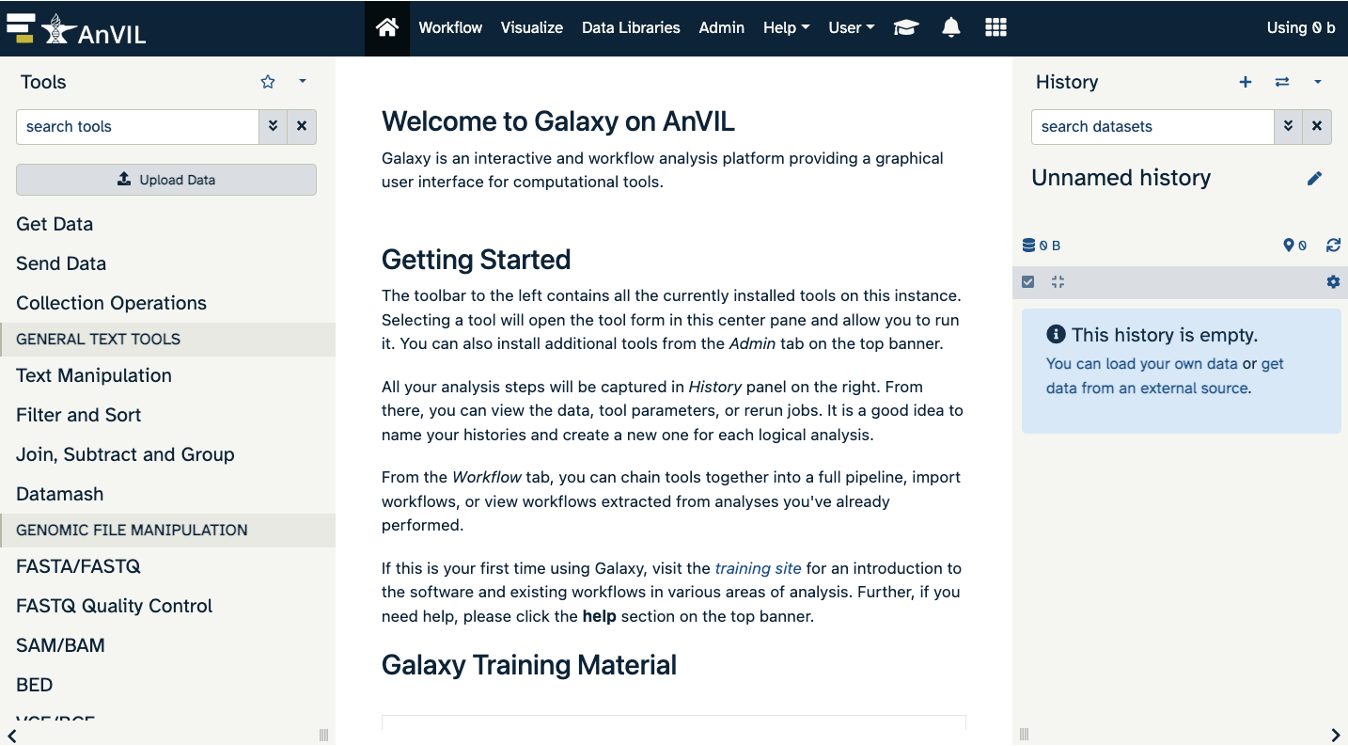
The welcome page includes links to tutorials. You may try these out on your own. If you want to try a new analysis this is a good place to start.
Exercise One: Importing Data into Galaxy
Luckily, we linked to the original data when we cloned our Workspace! We have three files we will need for our activity. These are (1) the reference genome for SARS-CoV-2, and both forward (2) and reverse (3) reads for our sample. Our sample has two sets of reads because the scientists who collected it used paired-end sequencing. The reference genome ends in “.fasta” because it has already been cleaned up by scientists. The sample we are looking at ends in “.fastq” because it is raw data from the sequencer.
Hands On: Import Data from the Workspace
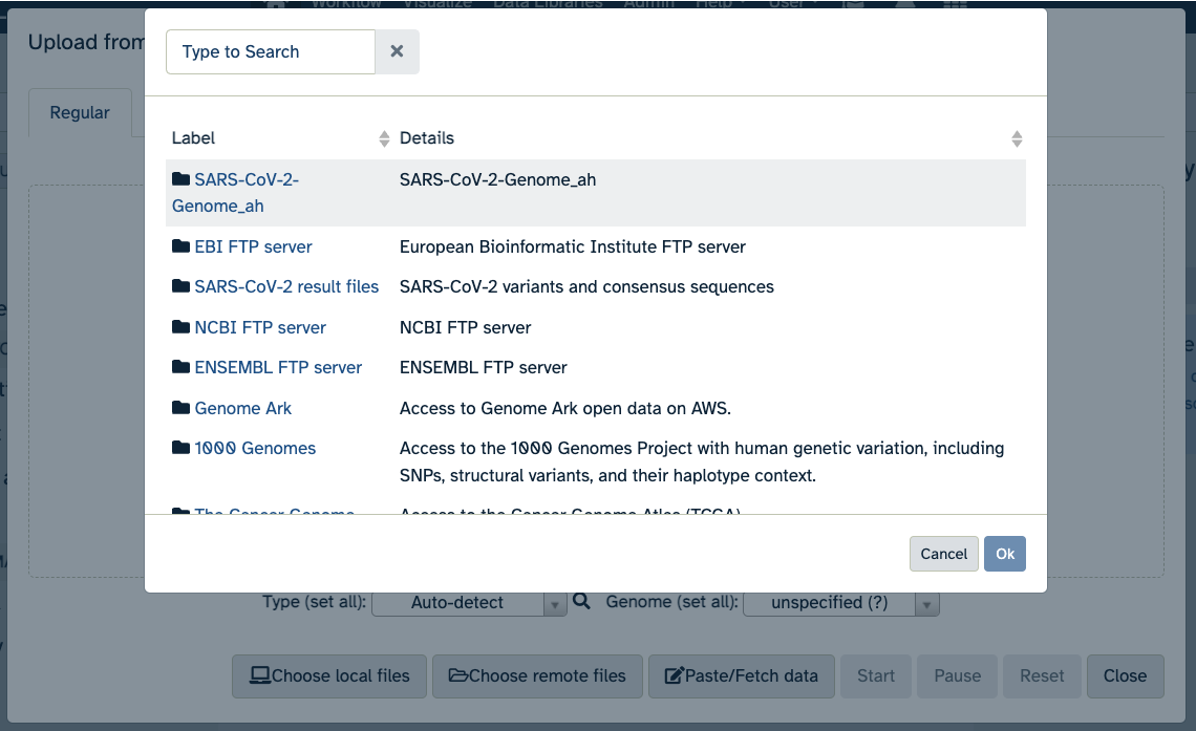
- Click on Upload Data in the Tools pane.
- Click on “Choose remote files” at the bottom of the popup. Double-click the top selection, which is the Workspace folder, then “Tables/” then “reference/”. Click the reference .fasta file so that it is highlighted in green and click “Ok”.
- Now that your reference has been added, click “Choose remote files” again to add the two sample files. Double-click the Workspace folder, then “Tables/” then “samples/”. Click the two sample
fastqfiles so that they are highlighted in green and click “OK”.- Click “Start” and once complete, you can click “Close”.
- Confirm your upload worked by looking at the file names in the History pane.
Exercise Two: Examining Files in Galaxy
Now we have some data in our account we can look at it. In this exercise we will see data in fastq format. This is the typical output from an Illumina Sequencer, but also the standard format for most alignment software.
Examining Inputs
Use your mouse and click on the eye icon galaxy-eye of the first file VA_sample_forward_reads.fastq. In the Main screen you will see something like this:
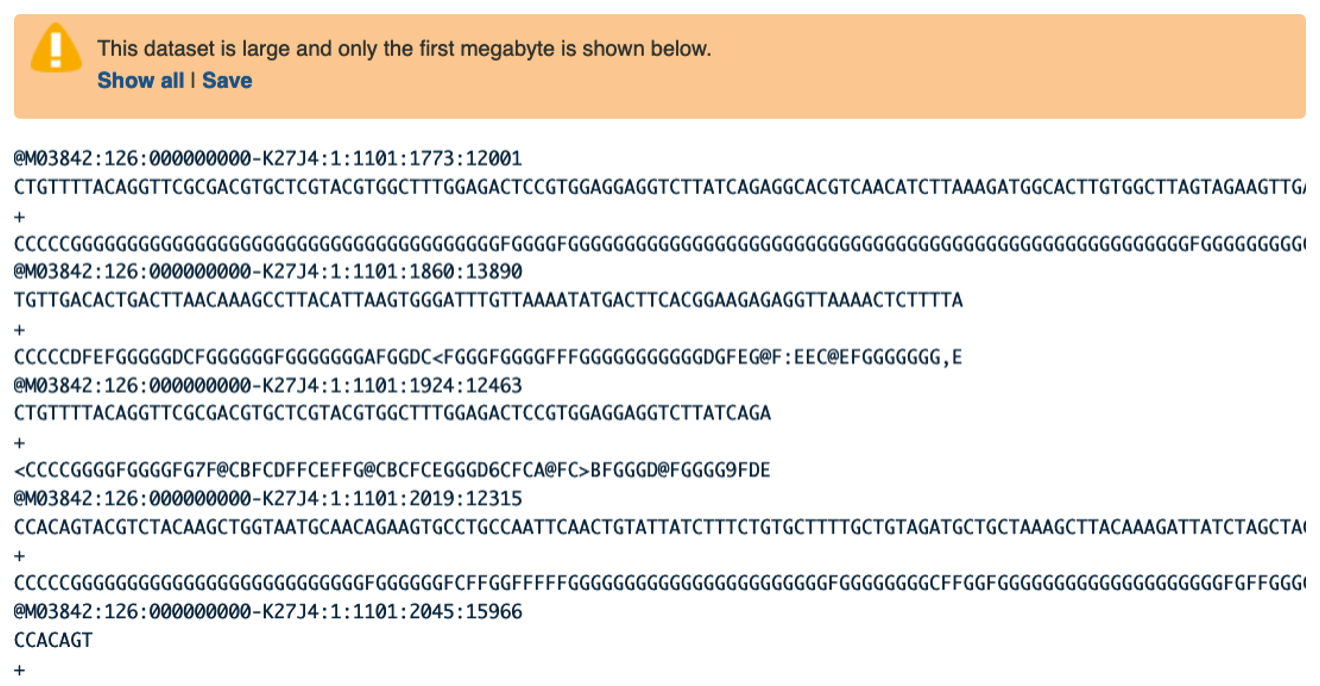
Question
- How many lines in a .fastq file represent an individual read?
- What does each line represent?
- Why is the final line for each read (the quality score) important?
- Four lines represent one read.
- The lines represent: 1 - A sequence identifier, 2 - The sequence (the base calls; A, C, T, G and N), 3 - A separator (not really data), 4 - The base call quality scores.
- It can help us filter out data that is wrong and/or low quality.
Quality Scoring
FastQC is a tool which aims to provide simple quality control checks on raw sequence data coming from high throughput sequencing pipelines. It provides a set of analyses which you can use to get a quick impression of whether your data has any problems of which you should be aware before doing any further analysis.
Hands On: Determine the Quality of the Samples
- Find FastQC ( Galaxy version 0.73+galaxy0) in the GENOMIC FILE MANIPULATION: FASTQ Quality Control tool folder.
- param-file “Raw read data from your current history”:
VA_sample_forward_reads.fastq- Run the tool.
The main dash will highlight in green if everything is okay. In the history, you will see the new files turn yellow, then green. If the job fails it will show an error.
Click on the eye icon galaxy-eye in the new file in the history “FASTQC on data2 Webpage”.
You will open up a summary report for the sequencing file:
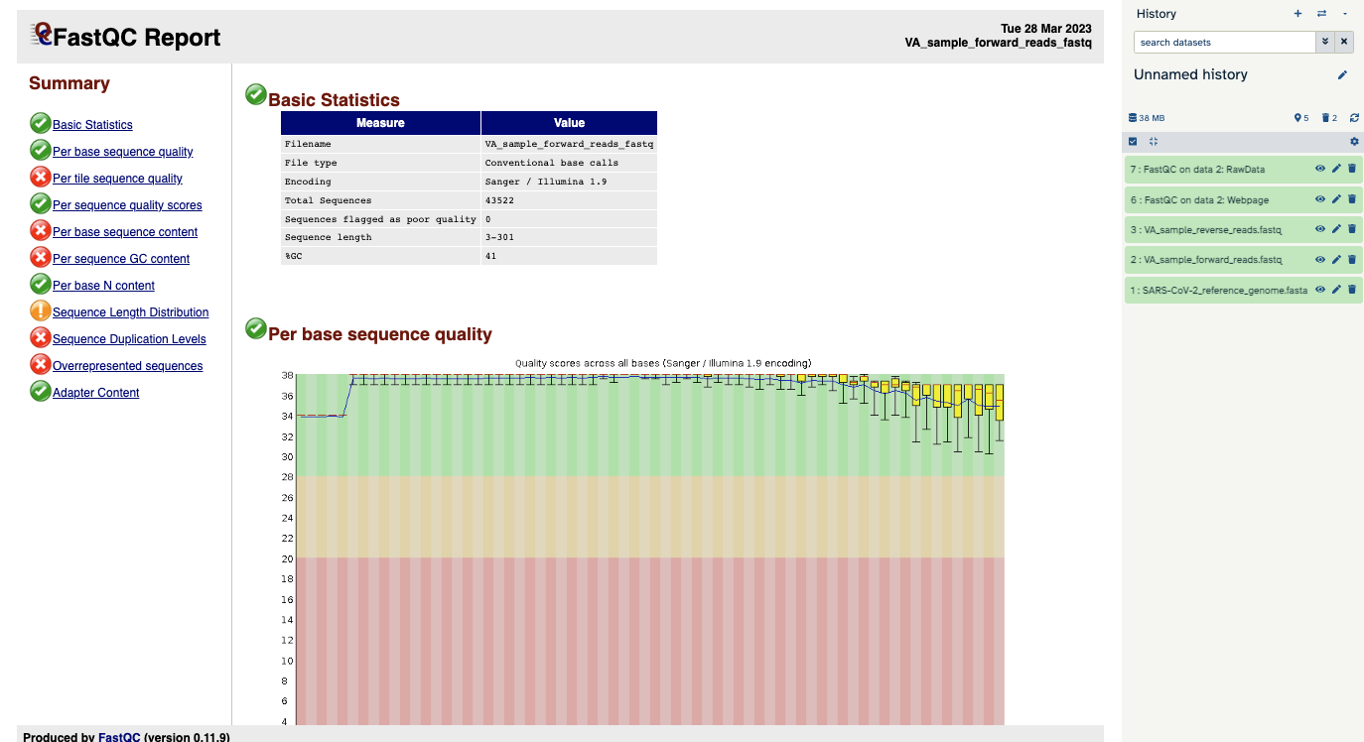
Question
- Explore “Basic Statistics”. How many total reads are there? Have any been flagged as poor quality? What is the sequence length?
- Explore “Per base sequence quality”. Based on the Basic Statistics, is 28-40 a good or bad quality score?
- Is it okay to proceed based on the per base sequence quality?
- 43,522 reads. Zero flagged as poor quality. Sequence length is 3-301 base pairs.
- 28-40 is pretty good.
- Yes, because the per base sequence quality is good (“in the green”).
But what does this quality score mean?
The quality score for each sequence is a string of characters, one for each base of the nucleotide sequence, used to characterize the probability of misidentification of each base. The score is encoded using the ASCII character table (with some historical differences):
To save space, the sequencer records an ASCII character to represent scores 0-42. For example 10 corresponds to “+” and 40 corresponds to “I”. FastQC knows how to translate this. This is often called “Phred” scoring.
So there is an ASCII character associated with each nucleotide, representing its Phred quality score, the probability of an incorrect base call:
Phred Quality Score Probability of incorrect base call Base call accuracy 10 1 in 10 90% 20 1 in 100 99% 30 1 in 1000 99.9% 40 1 in 10,000 99.99% 50 1 in 100,000 99.999% 60 1 in 1,000,000 99.9999% What does 0-42 represent? These numbers, when plugged into a formula, tell us the probability of an error for that base. This is the formula, where Q is our quality score (0-42) and P is the probability of an error:
Q = -10 log10(P)Using this formula, we can calculate that a quality score of 40 means only 0.00010 probability of an error!

Exercise Three: Alignment
Given that our data has passed some quality checks, we will try to align the data to the reference genome. In this case it is simple, a viral genome. A human sequencing project will generate much larger data sets. There are many aligners, but we will start off looking at a simple aligner BWA-MEM. This example uses paired data.
We will use our two SARS data files, which are ready for alignment.
VA_sample_forward_reads.fastqVA_sample_reverse_reads.fastq
Hands On: Align to the Reference Dataset
- Go to GENOMICS ANALYSIS and expand the Mapping menu. Select Map with BWA-MEM ( Galaxy version 0.7.17.2). This program will align your reads to your SARS reference genome. Some of our reads are >100 base pairs so we will use the MEM option.
- “Will you select a reference genome from your history or use a built-in index?”: Use a genome from history and build index.
- param-file “Use the following dataset as the reference sequence”:
SARS-CoV-2_reference_genome.fasta- “Single or Paired-end reads”:
Paired- “Select first set of reads”:
VA_sample_forward_reads.fastq- “Select second set of reads”:
VA_sample_reverse_reads.fastq- Run the tool.
The output file is a BAM file, which lists where each read aligns to the reference genome and whether there are any differences. You can click the eye button to preview the results, but the results are not easy to interpret visually (much like the fastq files). Instead you will use a genome viewer in the next step.
Question
- What is alignment software (for example, BWA-MEM) actually doing?
- In this example, we are using paired fastq (“paired end”) data. What is an advantage of using paired data?
- Alignment tools figure out the optimal positioning of the reads next to the reference genome to minimize mismatches and gaps.
- Paired data is made up of fragments that are read twice (forward and reverse). Paired data improves data accuracy.
Viewing aligned data
We have aligned our data but it is currently a table of where the reads align. This is hard to read, so we will use JBrowse to view the data.
Hands On: Visualize Reference Data
- Scroll down in the Tools menu to STATISTICS AND VISUALIZATION. Under “Graph/Display Data”, select JBrowse ( Galaxy version 1.16.9+galaxy0).
- param-select “Reference genome to display”:
Use a genome from history- param-select “Select the reference genome”:
SARS-CoV-2_reference_genome.fasta- Click “Run Tool”.
- You should see a new JBrowse item appear in your history. Click the eye icon galaxy-eye to open JBrowse.
You will need to click on the magnifying glasses to zoom in, but you should see the A,C,G, and Ts and their corresponding colors that make up the SARS-CoV-2 genome!
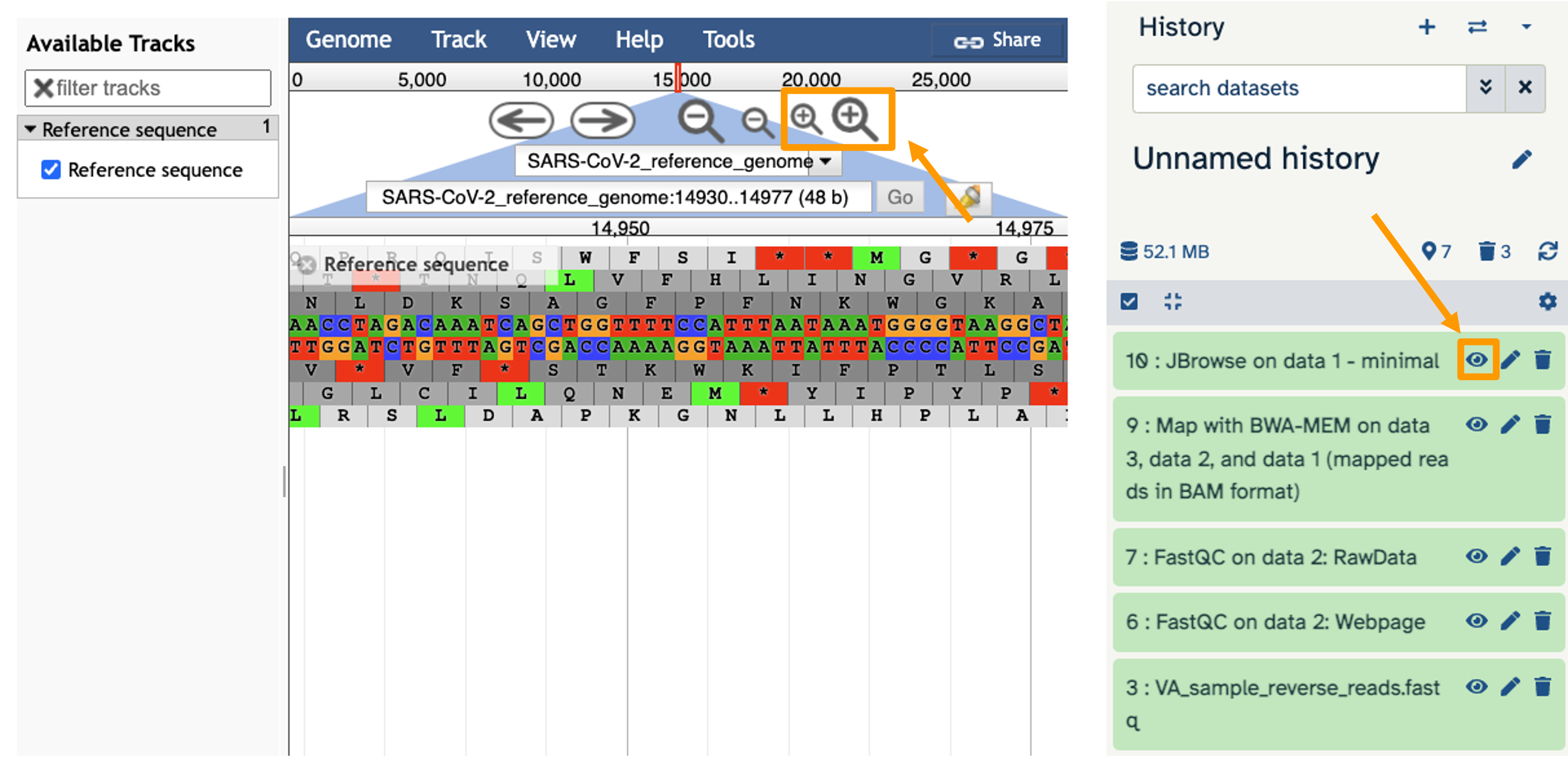
This is interesting, but it doesn’t let us compare the genome to the sample we have. We suspect there may be some differences that indicate our sample is the delta variant.
Hands On: Visualize Aligned Data
- Scroll down in the Tools menu to STATISTICS AND VISUALIZATION. Under “Graph/Display Data”, select JBrowse ( Galaxy version 1.16.9+galaxy0).
- param-select “Reference genome to display”:
Use a genome from history- param-select “Select the reference genome”:
SARS-CoV-2_reference_genome.fasta- param-repeat ”+ Insert Track Group”
- param-repeat “+ Insert Annotation Track”
- param-select “Track Type”:
BAM Pileups- param-toggle “Autogenerate SNP Track”:
Yes- param-text “Maximum size of BAM chunks”: Add one more zero:
50000000- Click “Run Tool”.
You should see a new JBrowse item appear in your history. Click the eye icon galaxy-eye to open JBrowse. Make sure that all boxes are checked on the left side: “Available Tracks”. The tracks will show up in the order that you click on them.
Hands On: Visualize Aligned Data
- Select the tracks from the BWA-MEM tool run.
- param-check
Map with BWA-MEM on data 9, data 8, and data 7 (mapped reads in BAM format)- param-check
Map with BWA-MEM on data 9, data 8, and data 7 (mapped reads in BAM format) - SNPs/Coverage- You should see a new JBrowse item appear in your history. Click the eye icon galaxy-eye to open JBrowse.
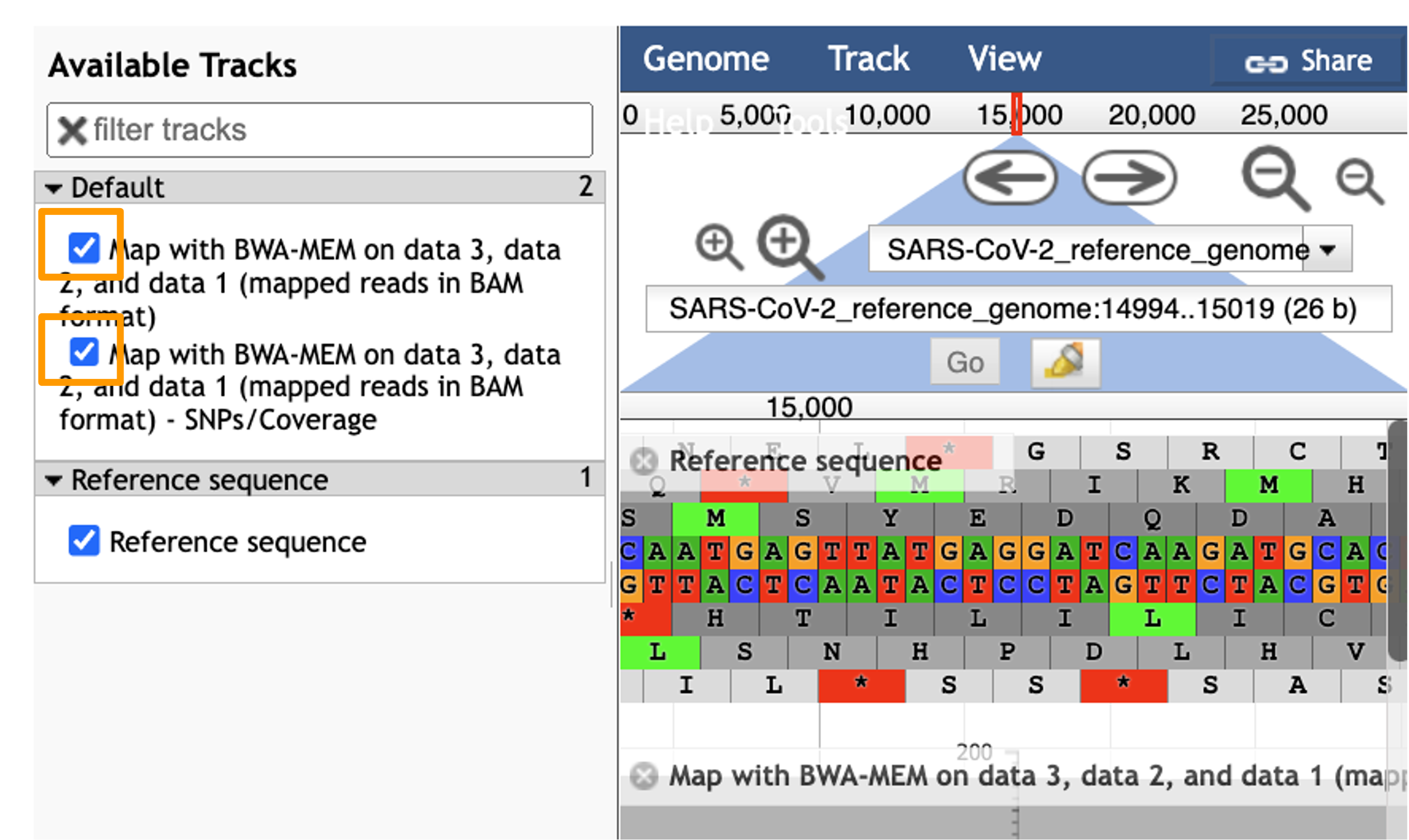
Let’s look at an example mutation in our sample. Type in the reference position “24410” and click “Go”. You should see a bunch of “A”s highlighted in green throughout our sample. The reference sequence (top line) is a “G” but all of the reads are an “A”. This means that our sample is genetically different from the established SARS-CoV-2 reference genome! Researchers often call these single base differences “SNPs” - Single Nucleotide Polymorphisms.
Question
- How long is the SARS-CoV-2 genome? Hint: zoom out and scroll to the end of the genome.
- Locate position 23,603. This is the site of an important mutation in the spike protein of the delta variant “P681R”. In this mutation, the amino acid proline is replaced by arginine. Is this mutation present at position 23,603 in our sample? Based on the evidence, do you think this sample is a delta variant?
- ~29,904 bp
- Yes! C has become a G. Yes, this sample is probably a delta variant because this mutation is indicative of the delta variant.
It’s possible to make mistakes in the data preparation before we get to the data analysis. Sometimes this happens when the samples are being prepared in the lab and sometimes this happens because the sequencer makes a mistake. This is one reason why quality scores are helpful. With millions of reads of data, it’s more likely that we see a “SNP” that is actually an accident. Multiple copies of the same areas of our data (“read depth”) help us be sure it’s a real SNP. When we compare across lots of aligned reads of the same area, we can determine the actual sequence by consensus. For example, we can be reasonably confident that the “G” at position 1,203 is just a sequencing or lab mistake.
Export Your History
It’s a good idea to export your “History” so that your collaborators can see what you did.
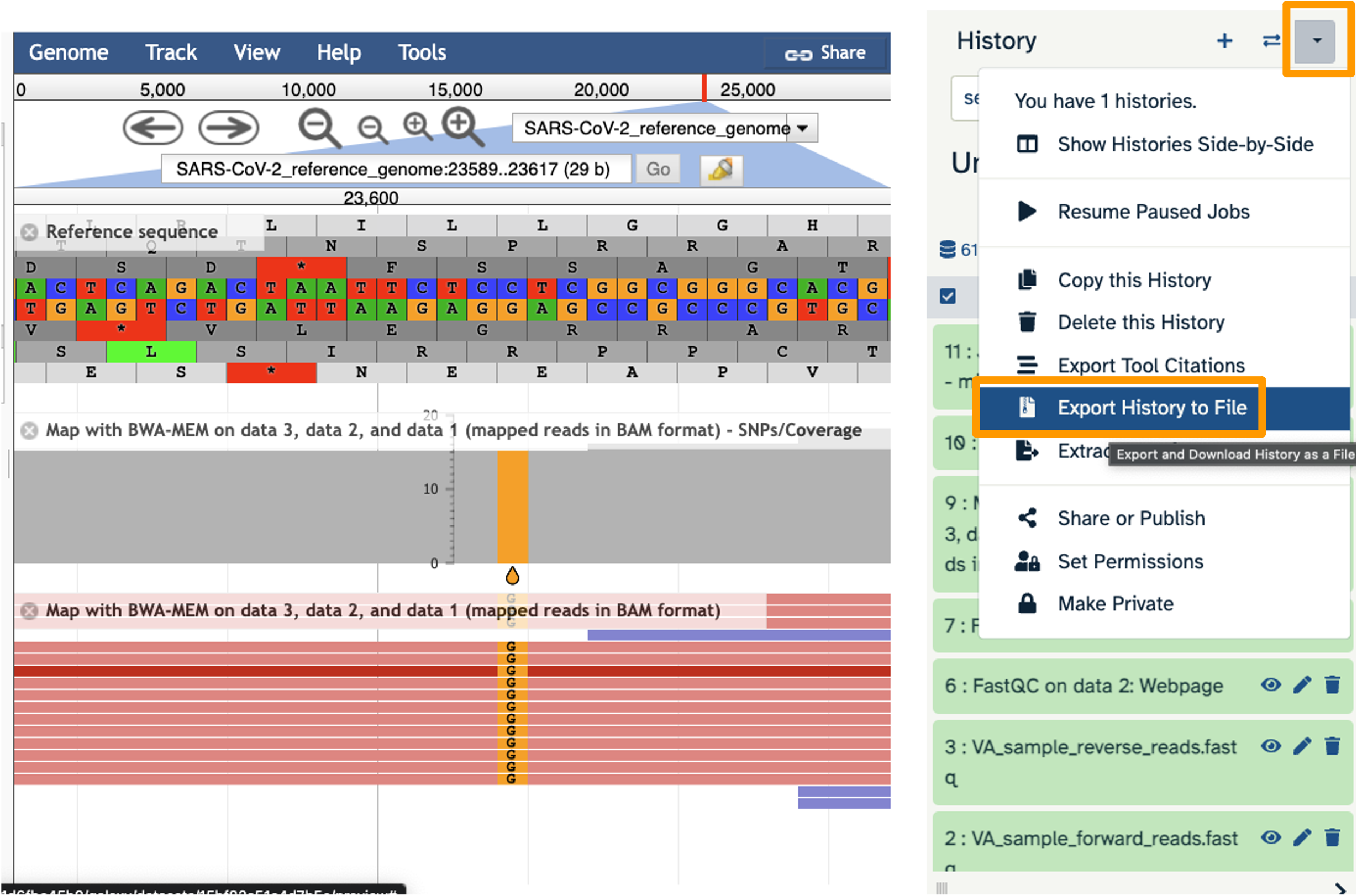
Hands On: Export History to Workspace
- Click on the History Menu galaxy-history-options and click on “Export History to File”.
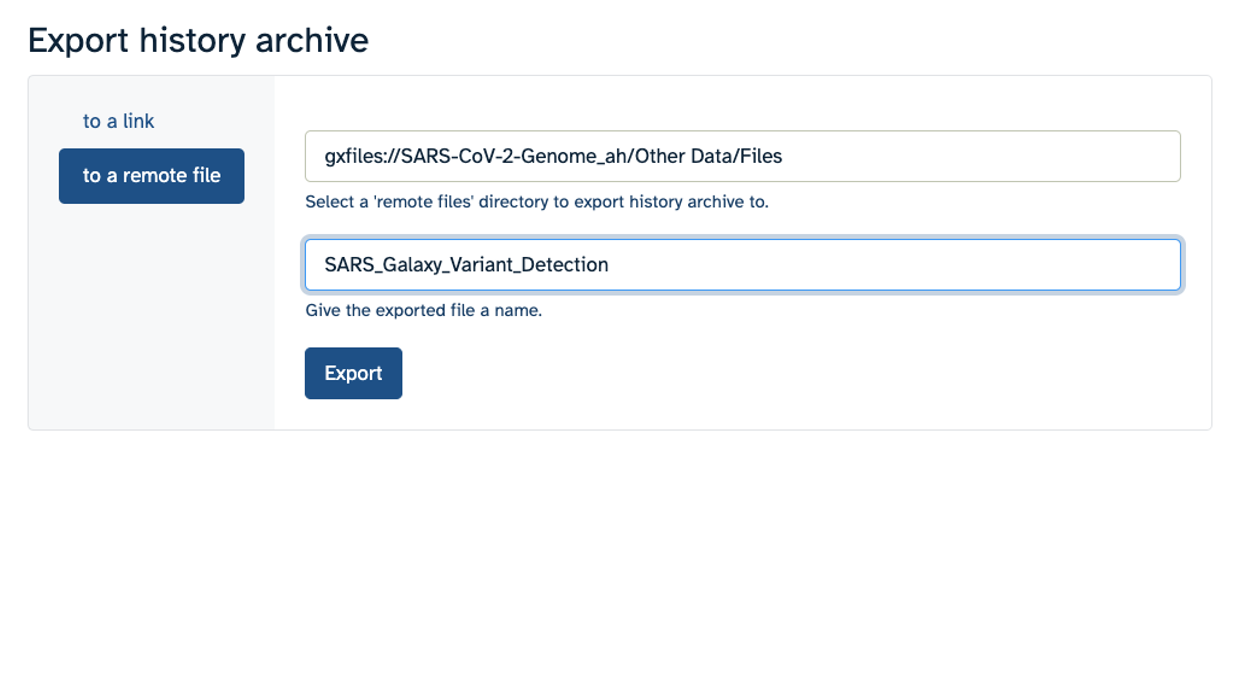
- Make sure you select “to a remote file”. Then, click to select where to export your History. On the popup menu, select your Workspace name, then select “Other Data”. Finally, select “Files”. Then click “Select this folder”. Make sure the export directory looks correct.
- Next, name your history “SARS Galaxy Variant Detection” and click “Export”.
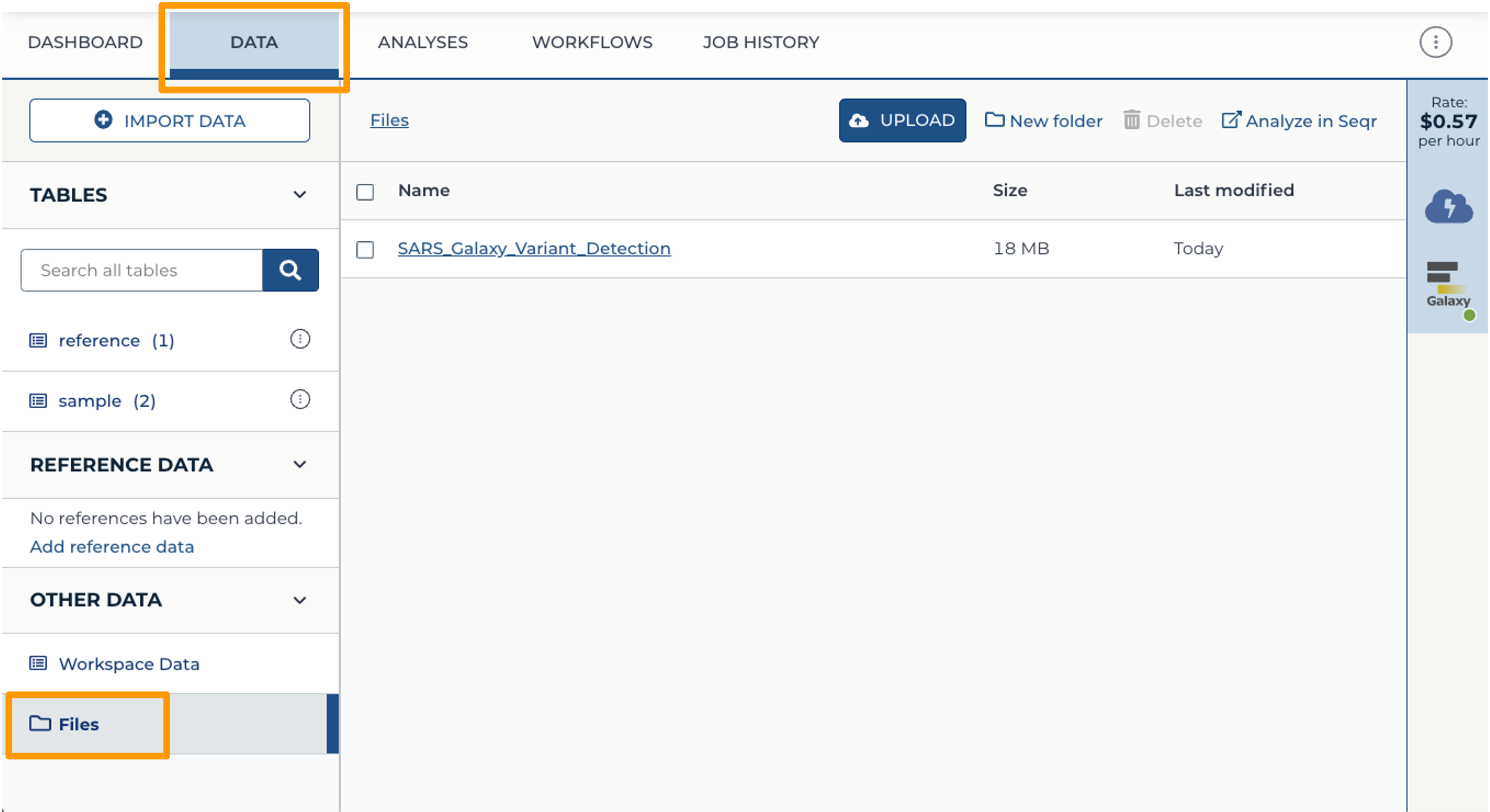
- Back at your Workspace, click on the “Data” tab, and the Files folder. You should now see the History export in your files. If you click on the file, you can download it or view it in Google Cloud Storage Browser.
Wrap-up
Once you are done with the activity, you’ll need to shut down your Galaxy cloud environment. This frees up the cloud resources for others and minimizes computing cost. The following steps will delete your work, so make sure you are completely finished at this point. Otherwise, you will have to repeat your work from the previous steps.
Hands On: Shut Down Galaxy in AnVIL
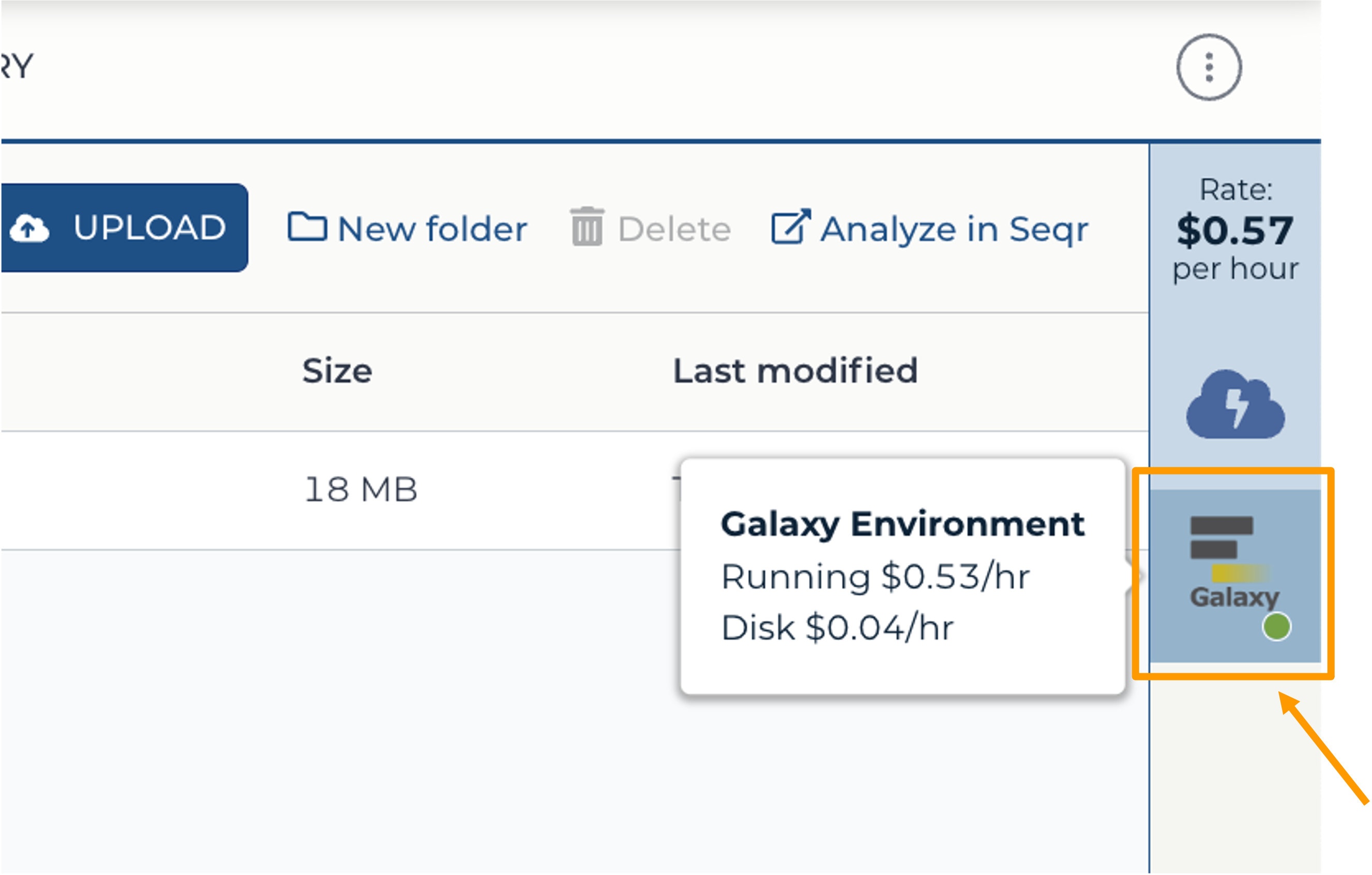
- Return to AnVIL, and find the Galaxy logo that shows your cloud environment is running. Click on the Galaxy logo.
- Click “Settings”.
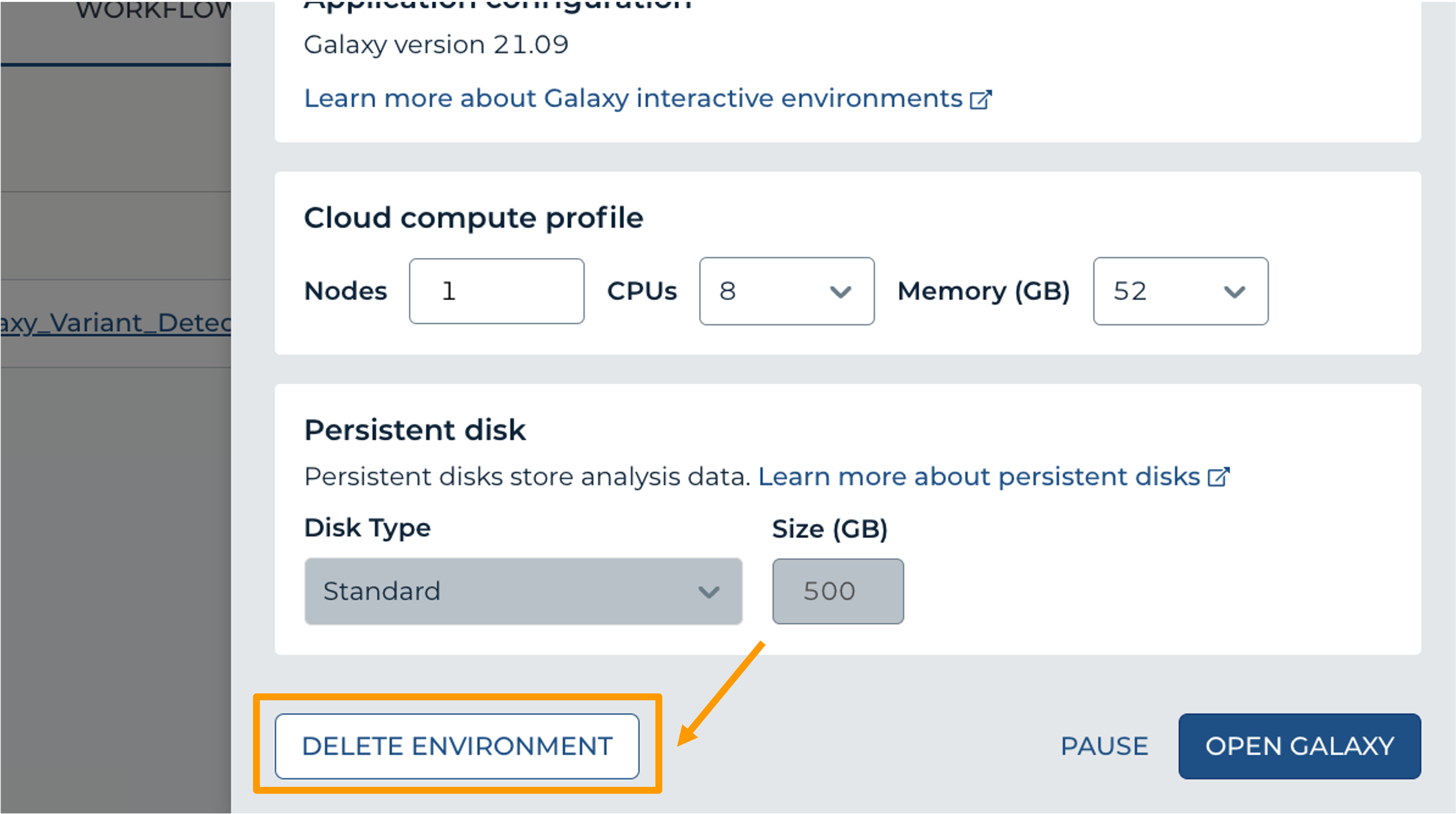
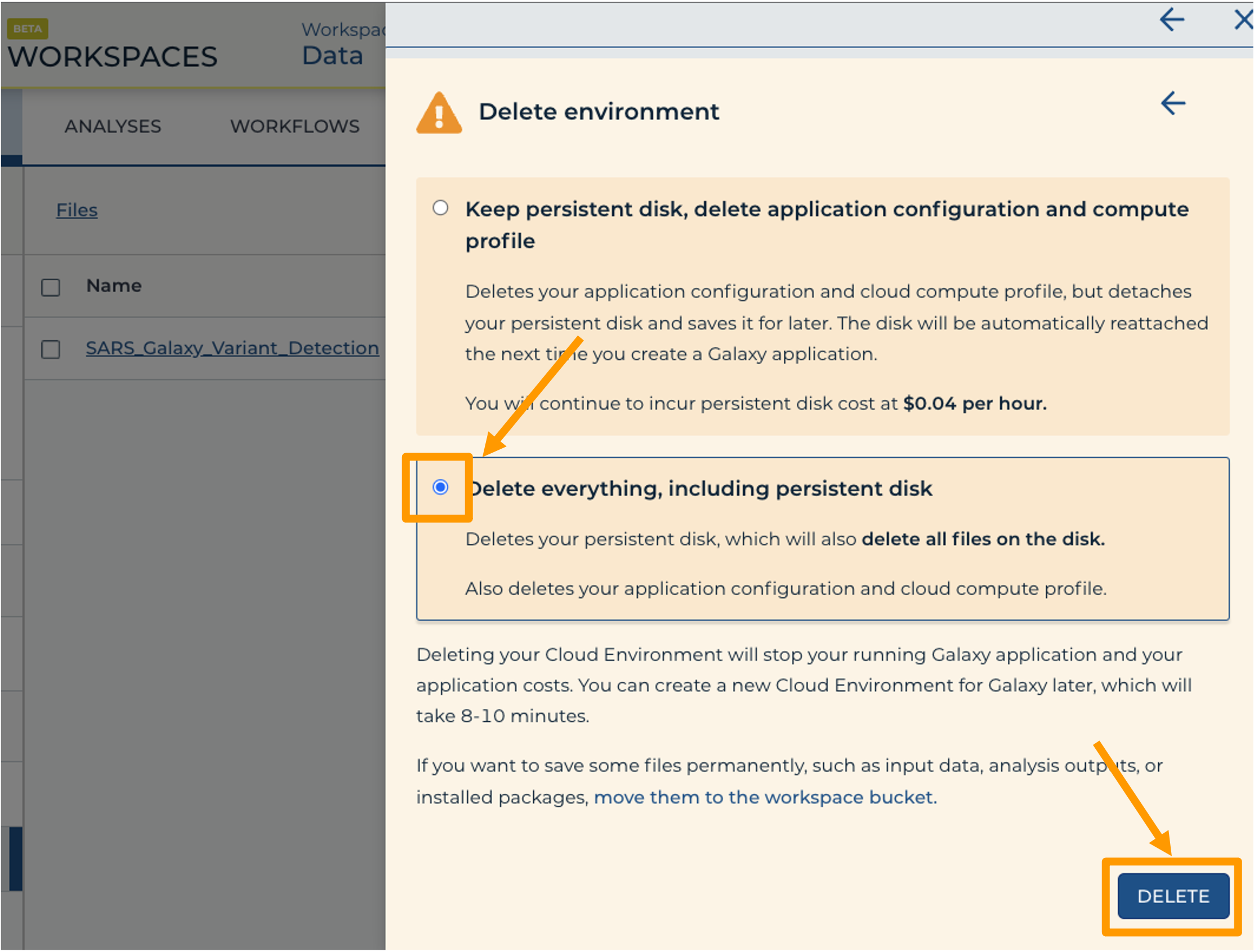
- Next, scroll down and click on “DELETE ENVIRONMENT”:
- Finally, select “Delete everything, including persistent disk”. Make sure you are done with the activity and then click “DELETE”.

Conclusion
Congratulations! You have run your first analysis using Galaxy in the AnVIL platform!
You've Finished the Tutorial
Key points
Use Galaxy on the AnVIL cloud computing resource to check data, perform an alignment, and visualize the results.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Natalie Kucher, Ava Hoffman, Robert Meller, SARS-CoV-2 Viral Sample Alignment and Variant Visualization (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/sequence-analysis/tutorials/sars-with-galaxy-on-anvil/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{sequence-analysis-sars-with-galaxy-on-anvil, author = "Natalie Kucher and Ava Hoffman and Robert Meller", title = "SARS-CoV-2 Viral Sample Alignment and Variant Visualization (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/sequence-analysis/tutorials/sars-with-galaxy-on-anvil/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Funding
These individuals or organisations provided funding support for the development of this resource
Congratulations on successfully completing this tutorial!You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/sequence-analysis/tutorials/sars-with-galaxy-on-anvil/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: bwa owner: devteam revisions: e188dc7a68e6 tool_panel_section_label: Mapping tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: fastqc owner: devteam revisions: 3d0c7bdf12f5 tool_panel_section_label: FASTA/FASTQ tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: jbrowse owner: iuc revisions: 17359b808b01 tool_panel_section_label: Graph/Display Data tool_shed_url: https://toolshed.g2.bx.psu.edu/