Biomarker candidate identification
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to mine public databases to retrieve info?
How to build a selection strategy by applying successive biochemical/cellular criteria to a list of gene/protein?
How to select biomarkers candidates using experimental information (transcriptomics & proteomics) and annotation from public databases?
Requirements:
Build a workflow implementing a strategy for the selection of tissue-leakage biomarkers using ProteoRE
Time estimation: 3 hoursSupporting Materials:Published: Jun 13, 2019Last modification: Nov 9, 2023License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00213rating Rating: 5.0 (0 recent ratings, 2 all time)version Revision: 9
A biomarker is a measurable biological component that can be routinely detected in clinical practice and reflects a disease state, response to therapeutic treatment, or other relevant biological state.
ProteoRE Galaxy instance provides necessary tools to execute a complete biomarkers selection pipeline. In this tutorial we introduce successively the tools of this pipeline, and guide you to execute them in order to complete the entire pipeline on a concrete example. This strategy is described by Nguyen et al. 2019.
AgendaIn this tutorial, we will cover:
Global view of the strategy
For this tutorial, no input data are required as the first steps will be to select data from public databases with ProteoRE tools.
The strategy consists in selecting, one step after another, the most interesting candidates biomarkers. Our use-case here is to identify candidate biomarkers for myocardial infarction tissue-leakage.
Criteria candidate biomarkers have to fulfill through this pipeline are:
- heart-specificity
- cytoplasmic localization
- detection in LC-MS/MS experiments already done
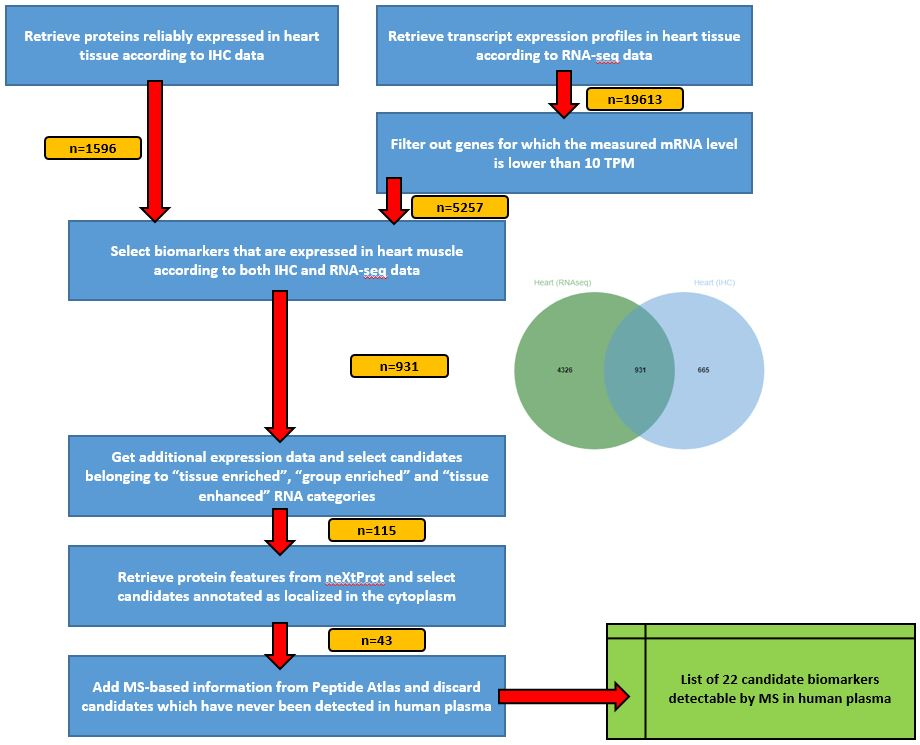 Open image in new tab
Open image in new tabComment: Results may varyYour results may be slightly different from the ones presented in this tutorial due to differing versions of tools, reference data, external databases, or because of stochastic processes in the algorithms.
Selection of tissue-specific proteins
We will start by selecting proteins associated with heart muscle tissue based on experimental data available from The Human Protein Atlas (HPA) (Publication: Uhlén et al. 2005)
Hands On: Build tissue-specific expression dataset based on ImmunoHistoChemistry
Create a new history and give it a name.
To create a new history simply click the new-history icon at the top of the history panel:
Build tissue-specific expression dataset tool with the following parameters:
- “Experimental data source (antibody- or RNAseq-based)”:
Expression profiles based on immunohistochemistry- “Select tissue”:
Heart muscle- “Expression level”:
HighandMedium- “Reliability score”:
EnhancedandSupportedOutput
- Tissue-specific expression from IHC (1596 lines): List of the selected proteins. 6 columns: ‘Gene’, ‘Gene name’ and the retrieved info from HPA.

We will now rerun the same tool but to select transcripts according to their expression profile.
Hands On: Build tissue-specific expression dataset based on RNAseq
- Build tissue-specific expression dataset tool with the following parameters:
- “Experimental data source (antibody- or RNAseq-based)”:
RNA levels based on RNA-seq experiments- “Select tissue”:
Heart muscleOutput
- Tissue-specific expression from RNAseq (19613 lines): List of the selected transcripts. 4 columns: ‘Gene’, ‘Gene name’ and the retrieved info from HPA.
This second list must be reduced by removing transcripts that are not highly enriched in heart muscle. To do so, a filter is applied on the expression value provided by HPA and measured in TPM (last column of the output file). In ProteoRE we’ll use the “Filter by keywords and/or numerical value” tool.
Hands On: Filter on expression value criterion
- Filter by keywords and/or numerical value tool with the following parameters:
- “Input File”:
Tissue-specific expression from RNASeqfrom the previous step- “Operation”:
Discard- In “Filter by numerical value”:
- param-repeat “Insert Filter by numerical value”
- “Column number on which to apply the filter”:
c4- “Select operator”:
<=- “Value”:
10.0- “Sort by column ?”:
Yes
- “Sort result files by”:
c4QuestionHow many lines are there in the file of heart transcripts with a TPM value >10 ?
5257 lines.
We have now 2 datasets of heart-muscle proteins/transcripts, based on IHC (Immonohistochemistry) data or TPM (Expression level expressed in Transcripts Per Million) value.
We want now to select candidate biomarkers that are expressed in the heart muscle according to both IHC and RNA-seq data, using the Jvenn tool.
Hands On: Venn diagram
- Venn diagram tool with the following parameters:
- In “List to compare”:
- param-repeat “Insert List to compare”
- “Enter your list”:
Input file containing your list
- “Select your file”:
Tissue-specific expression from IHC- “Enter the name of this list”:
heart IHC- param-repeat “Insert List to compare”
- “Enter your list”:
Input file containing your list
- “Select your file”:
Filtered tissue-specific expression from RNAseq- “Enter the name of this list”:
heart RNAseqExamine galaxy-eye the Venn diagram output:
QuestionHow many IDs are common to both IHC and RNA-seq data?
931 candidate biomarkers are detected by both IHC and RNA-seq data.
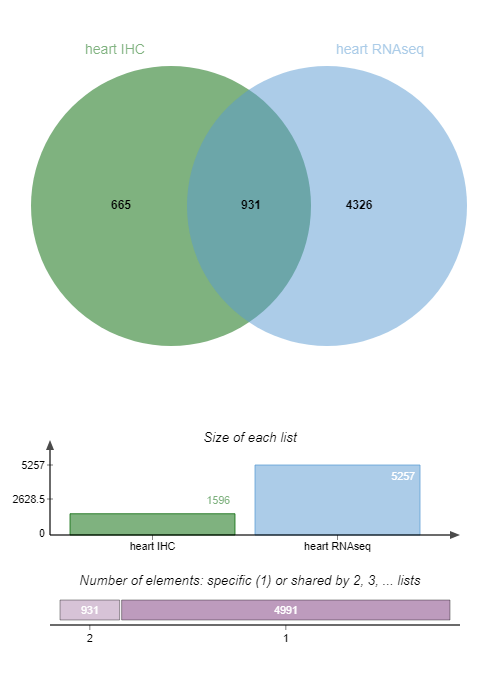
For greater clarity we’ll keep only the column with those 931 candidate biomarkers detected in both IHC and RNA-seq data in the rest of our pipeline.
Hands On: Obtain list of candidate biomarkers
- Cut tool with the following parameters:
- “File to cut”:
Venn diagram text output- “Cut by”:
fields
- “List of Fields”:
Column: 3Now we’ll filter this dataset not to keep the ‘NA’ lines.
- Filter by keywords and/or numerical value tool with the following parameters:
- “Input file”: output from Cut tool
- “Operation”:
Discard- In “Filter by keywords”:
- param-repeat “Insert Filter by keywords”
- “Search for exact match?”:
Yes- “Enter keywords”:
copy/paste
- “Copy/paste keywords to find (keep or discard)”:
NA- “Sort by column ?”:
Yes
- “Sort result files by”:
c1Let’s rename the 931 IDs dataset in “heart931” for simplification.
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button
The pipeline will then continue based on these 931 candidates, from which we have to select biomarkers that are highly specific to the heart using additional expression data (still from HPA).
Hands On: Add expression data
- Add expression data tool with the following parameters:
- “Enter your IDs (Ensembl gene IDs only, e.g. ENSG00000064787)”:
Input file containing your IDs
- “Select your file”:
Heart931output we created in the previous step- In “RNAseq/Ab-based expression data”:
- “Select information to add to your list”:
- param-check
Gene name- param-check
Gene description- param-check
RNA tissue category- param-check
RNA tissue specificity abundance in Transcript Per Million
We wish to focus on transcripts that have been classed as (according to the HPA definition):
- Tissue enriched (expression in one tissue at least fivefold higher than all other tissues),
- Group enriched (fivefold higher average TPM in a group of two to to seven tissues compared to all other tissues) and
- Tissue enhanced (fivefold higher average TPM in one or more tissues/cell lines compared to the mean TPM for all tissues)
This information is listed in the column 4 : “RNA tissue category” of the result dataset.
Let’s use Filter by keywords and/or numerical value tool to select the candidate biomarkers based on this “RNA tissue category” criterion.
Hands On: Filter by keywords and/or numerical value
- Filter by keywords and/or numerical value tool with the following parameters:
- “Input file”: output from Add expression data tool
- In “Filter by keywords”:
- param-repeat “Insert Filter by keywords”
- “Column number on which to apply the filter”:
c4- “Enter keywords”:
copy/paste
- “Copy/paste keywords to find (keep or discard)”:
enriched enhanced- “Sort by column ?”:
Yes
- “Sort result files by”:
c1Output
Filtered Add_expression_data: output list of the heart biomarkers with RNA tissue category containing “enriched” or “enhanced” (115 lines = what we are interested in)
Filtered Add_expression_data - discarded lines: output list of the heart biomarkers with RNA tissue category NOT containing “enriched” or “enhanced” (not what we are interested in)
Let’s rename the filtered dataset heart115
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button
We now have identified 115 candidates considered to have significantly higher expression in heart muscle according to HPA criteria.
Annotation with biochemical and cellular features
Candidate biomarkers we want to identify have to be cytoplasmic and without transmembrane domains (TMD). Thus we will retrieve protein features from neXtProt to retrieve those informations.
Since HPA only considers Ensemble ENSG identifiers (related to the gene), although neXtProt uses UniProt identifiers (related to proteins), first thing to do is to map the Ensembl identifiers contained our list of (115)
candidates to their corresponding UniProt accession number. The tool ID Converter is what we need to do so.
Hands On: ID Converter
- ID Converter tool with the following parameters:
- “Enter IDs”:
Input file containing IDs- “Select your file”:
heart115- “Species”:
Human (Homo sapiens)
- “Type/source of IDs”:
Ensembl gene ID (e.g. ENSG00000166913)- In “Target type”:
- “Target type of IDs you would like to map to”:
- param-check
Uniprot accession number- param-check
Uniprot IDOutput
ID converter: In this dataset, 2 columns (columns 6 and 7, at the end) which contain UniProt accession number and ID are added. Note: We used here the release “Homo sapiens 08/05/2019”; results can be slightly different according to the version number of Uniprot.
We have now UniProt IDs for the 115 candidate biomarkers: we are able to collect protein features from neXtProt. For this purpose, we use the Add protein features tool ProteoRE tool.
Hands On: Add protein features
- Add protein features tool with the following parameters:
- “Enter your IDs (neXtProt or UniProt)”:
Input file containing your IDs
- “Select your file”: the output from ID Converter tool
- “Column IDs (e.g : Enter c1 for column n°1)”:
c6- In “Select features”:
- “Physico-Chemical Features”:
- param-check
Number of transmembrane domains- “Localization”:
- param-check
Subcellular Location- “Disease information”:
YesOutput
Add information from NextProt: In this file (115 lines), 3 columns (columns 8, 9 and 10) were added (at the end). These columns present TMDomains, Subcell Location and Diseases info.
With this dataset, we can select proteins reported as localized in the cytoplasm and having no transmembrane domains by running the Filter by keywords and/or numerical value tool.
Hands On: Filter by keywords and/or numerical value
- Filter by keywords and/or numerical value tool with the following parameters:
- “Input file”: the output from Add protein features tool
- “Select an operator to combine your filters (if more than one)”:
AND- In “Filter by keywords”:
- param-repeat “Insert Filter by keywords”
- “Column number on which to apply the filter”:
c9- “Enter keywords”:
copy/paste
- “Copy/paste keywords to find (keep or discard)”:
cytoplasm cytosol- In “Filter by numerical value”:
- param-repeat “Insert Filter by numerical value”
- “Column number on which to apply the filter”:
c8- “Value”:
0- “Sort by column ?”:
Yes
- “Sort result files by:”:
c5- “Sort in descending order ?”:
YesOutput
- Filtered Add_information_from_neXtProt: output list of the proteins having a cytoplasmic location and no TMD (48 proteins)
- Filtered Add_information_from_neXtProt - discarded lines: output list of the proteins NOT cytoplasmic and having at least 1 TMD.
We have now 45 proteins. The next step is to identify those proteins already previously observed in LS MS/MS experiments.
Check for previous detection by LC-MS/MS experiments
Hands On: Get MS/MS observations in tissue/fluid
- Get MS/MS observations in tissue/fluid tool with the following parameters:
- “Enter your IDs (UniProt Accession number only)”:
Input file containing your IDs
- “Select your file”: the filtered output from the previous step
- “Column of IDs”:
c6- “Proteomics dataset (biological sample)”:
- param-check
Human Heart- param-check
Human Plasma non glycoOutput
Get MS/MS observations in tissue/fluid: In this file, 2 columns (11 and 12, at the end) were added with the info of number of times peptides were seen by MS/MS.
Let’s now keep only proteins that have already been seen by MS/MS in the plasma (last column of the file).
Hands On: Filter for proteins seen in the plasma
- Filter by keywords and/or numerical value tool with the following parameters:
- “Input file”: the MA/MS observations output from the previous step
- “Operation”:
Discard- In “Filter by keywords”:
- param-repeat “Insert Filter by keywords”
- “Column number on which to apply the filter”:
c12- “Search for exact match?”:
Yes- “Enter keywords”:
copy/paste
- “Copy/paste keywords to find (keep or discard)”:
NA- “Sort by column ?”:
Yes
- “Sort results file by”:
c1Output
- Filtered Get MS/MS observations in tissue/fluid: output list of the proteins whose some peptides have been seen in plasma (21 proteins)
- Filtered Get MS/MS observations in tissue/fluid - discarded lines: output list of proteins with no peptides seen in the plasma
Conclusion
At the end of the process we end up with a list of 22 biomarkers that are highly enriched in heart muscle, localized in the cytosol and detectable by MS in the plasma. NB: Please be aware that, due to databases update, number of biomarkers you end up with can be different from 21 that we obtain here.
Briefly and from a biological point of view, 3 of these proteins exhibit a relative low detection level in the plasma compared to heart muscle tissue, and are reported with a very high heart-muscle-specific RNA abundance. These potential mechanistic biomarkers of myocardial infarction include (i) cardiac Troponin I type 3 (TNNI3 (P19429)) that is routinely used as the most specific marker of myocardial injury and (ii) the heart-type fatty acid-binding protein (FABP3 (P05413)) that has been proposed as a diagnostic and prognostic marker for acute and chronic cardiac injury.
Extraction of a workflow from your history is valuable for analyses reproducibility and traceability. Moreover, a workflow can also be made reusable with modifiable parameters, and as a result this strategy can be applied to other types of tissue injury (e.g. brain, liver, kidney).
You've Finished the Tutorial
Key points
Public proteomics databases are useful resources for annotation of biomarker candidates
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
References
- Uhlén, M., E. Björling, C. Agaton, C. A.-K. Szigyarto, B. Amini et al., 2005 A Human Protein Atlas for Normal and Cancer Tissues Based on Antibody Proteomics. Molecular & Cellular Proteomics 4: 1920–1932. 10.1074/mcp.m500279-mcp200
- Nguyen, L., V. Brun, F. Combes, V. Loux, and Y. Vandenbrouck, 2019 Designing an In Silico Strategy to Select Tissue-Leakage Biomarkers Using the Galaxy Framework, pp. 275–289 in Methods in Molecular Biology, Springer New York. 10.1007/978-1-4939-9164-8_18
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Florence Combes, David Christiany, Valentin Loux, Yves Vandenbrouck, Biomarker candidate identification (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/biomarker_selection/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{proteomics-biomarker_selection, author = "Florence Combes and David Christiany and Valentin Loux and Yves Vandenbrouck", title = "Biomarker candidate identification (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/biomarker_selection/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/proteomics/tutorials/biomarker_selection/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: text_processing owner: bgruening revisions: 288462ec2630 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: proteore_expression_rnaseq_abbased owner: proteore revisions: dbeabf9bf091 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: proteore_filter_keywords_values owner: proteore revisions: 33ca9ba2495a tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: proteore_id_converter owner: proteore revisions: b6607b7e683f tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: proteore_ms_observation_pepatlas owner: proteore revisions: 299eb4a62e0c tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: proteore_prot_features owner: proteore revisions: 8df559ad14a7 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: proteore_tissue_specific_expression_data owner: proteore revisions: 3e65e0249976 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: proteore_venn_diagram owner: proteore revisions: d1fd04dcb13a tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/