Una proteina lungo la pagina UniProt
| Autore/i |
|
| Traduzione |
|
| Revisore/i |
|
PanoramicaDomande:
Obiettivi:
Come si possono cercare proteine utilizzando testo, geni o nomi di proteine?
Come si interpretano le informazioni in cima alla pagina di UniProt?
Che tipo di informazioni ci si può aspettare da diversi formati di download, come FASTA e JSON?
Come viene descritta la funzione di una proteina come le opsine nella sezione “Funzione”?
Quali informazioni strutturate si trovano nelle sezioni “Nomi e tassonomia”, “Localizzazione subcellulare”, “Malattia e varianti”, “PTM/Elaborazione”?
Come si possono conoscere l’espressione proteica, le interazioni, la struttura, la famiglia, la sequenza e le proteine simili?
In che modo le schede “Visualizzatore varianti” e “Visualizzatore caratteristiche” aiutano a mappare le informazioni proteiche lungo la sequenza?
Cosa elenca la scheda “Pubblicazioni” e come si possono filtrare le pubblicazioni?
Qual è l’importanza di monitorare le modifiche delle annotazioni delle voci nel tempo?
Requisiti:
Esplorando le voci proteiche in UniProtKB, è possibile interpretare la funzione, la tassonomia, la struttura, le interazioni, le varianti e altro ancora delle proteine.
Utilizzare identificatori univoci per collegare database, scaricare dati su geni e proteine, visualizzare e confrontare le caratteristiche delle sequenze.
- slides Slides: Learning about one gene across biological resources and formats
- tutorial Hands-on: Learning about one gene across biological resources and formats
Stima del tempo: 1 oraLivello: Introduttivo IntroductoryMateriali di supporto:Pubblicato: Mar 30, 2026Ultima modifica: Mar 30, 2026Licenza: Il contenuto del tutorial è concesso in licenza Creative Commons Attribution 4.0 International License. Il framework GTN è concesso in licenza MITversion Revisione: 1
Quando si esegue un’analisi di dati biologici, è possibile che ci si ritrovi con alcune proteine interessanti e che sia necessario esplorare questi geni. Ma come possiamo farlo? Quali sono le risorse disponibili per questo? E come navigare al loro interno?
Lo scopo di questo tutorial è di familiarizzare con questo aspetto, utilizzando come esempio le opsine umane.
CommentoQuesto tutorial è un po’ atipico: non lavoreremo in Galaxy ma soprattutto al di fuori di esso, nelle pagine del database UniProt.
CommentoQuesto tutorial è stato progettato per essere la continuazione del tutorial “Un gene attraverso i formati di file”, ma può essere consultato anche come modulo autonomo.
Le opsine si trovano nelle cellule della retina. Catturano la luce e iniziano la sequenza di segnali che porta alla visione, ed è per questo che, quando sono compromesse, sono associate al daltonismo e ad altri disturbi visivi.
Commento: Fonti di informazione di questo tutorialIl tutorial che state consultando è stato sviluppato principalmente consultando le risorse UniProtKB, in particolare il tutorial Explore UniProtKB entry. Alcune frasi sono riportate da lì senza modifiche.
Inoltre, l’argomento è stato scelto sulla base del [Tutorial di bioinformatica] di Gale Rhodes (https://spdbv.unil.ch/TheMolecularLevel/Matics/index.html). Sebbene il tutorial non possa più essere seguito passo dopo passo a causa del modo in cui le risorse citate sono cambiate nel tempo, potrebbe fornire ulteriori spunti di riflessione sulle opsine e in particolare su come si possano costruire modelli strutturali di proteine basati su informazioni evolutive.
AgendaIn questo tutorial ci occuperemo di:
La pagina di inserimento di UniProtKB
Il portale da visitare per ottenere tutte le informazioni su una proteina è UniProtKB. Possiamo effettuare la ricerca utilizzando una ricerca testuale o il nome del gene o della proteina. Proviamo prima con una serie di parole chiave generiche, come Human opsin.
Pratica: Ricerca opsina umana su UniProtKB
- Aprire il file UniProtKB
- Digitare
Human opsinnella barra di ricerca- Avviare la ricerca
DomandaQuanti risultati abbiamo ottenuto?
410 risultati (al momento della preparazione di questo tutorial)
Questi 410 risultati ci danno la sensazione di dover essere più specifici (anche se - spoiler - il nostro obiettivo effettivo è tra i primi risultati).
Per essere sufficientemente specifici, suggeriamo di usare un identificatore unico. Dal tutorial precedente conosciamo il nome del gene della proteina che stiamo cercando, OPN1LW.
Pratica: Ricerca di OPN1LW su UniProtKB
- Digitare
OPN1LWnella barra di ricerca in alto- lanciare la ricerca
Domanda
- Quanti risultati abbiamo ottenuto?
- Cosa dovremmo fare per ridurre questo numero?
- 200+ risultati (al momento della preparazione di questo tutorial)
- Dobbiamo chiarire cosa stiamo cercando: OPN1LW umano
Dobbiamo aggiungere Human per chiarire cosa stiamo cercando.
Pratica: Ricerca di OPN1LW umana su UniProtKB
- Digitare
Human OPN1LWnella barra di ricerca in alto- Avviare la ricerca
Domanda
- Quanti risultati abbiamo ottenuto?
- Abbiamo un risultato che includa OPN1LW come nome del gene?
- 7 risultati (al momento della preparazione di questo tutorial)
- Il primo risultato è etichettato con
Gene: OPN1LW (RCP)
Il primo risultato, etichettato con Gene: OPN1LW (RCP), è il nostro obiettivo, P04000 · OPSR_HUMAN. Prima di aprire la pagina, occorre notare due cose:
- Il nome della proteina
OPSR_HUMANè diverso dal nome del gene, così come i loro ID sono. - Questa voce ha una stella dorata, il che significa che è stata annotata e curata manualmente.
Ispezione di una voce UniProt
Pratica: Aprire un risultato in UniProt
- Clicca su
P04000 · OPSR_HUMAN
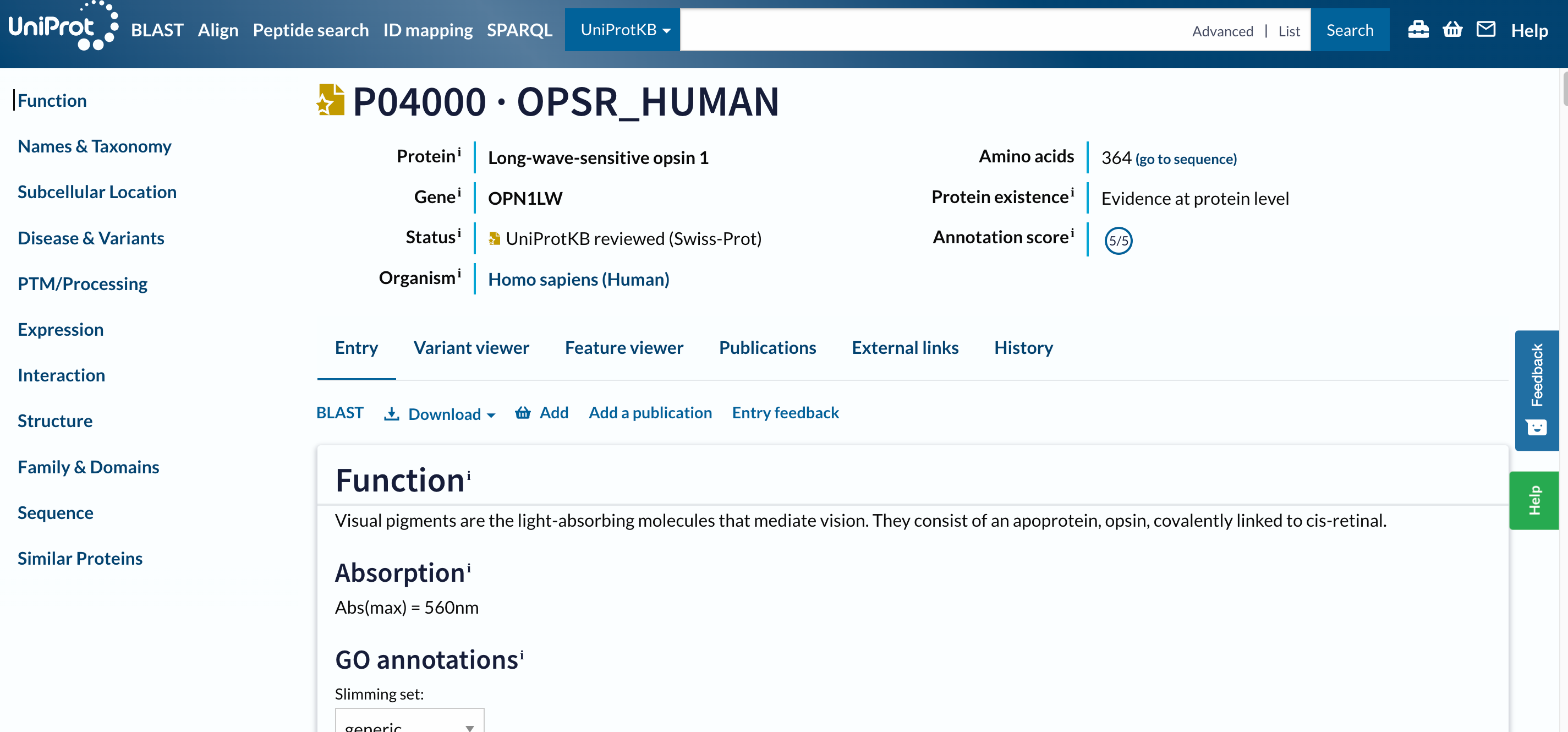 Open image in new tab
Open image in new tabPer navigare in questa lunga pagina, il menu (barra di navigazione) a sinistra sarà estremamente utile. Solo da esso si capisce che questo database contiene informazioni sulla voce su:
- le funzioni note,
- la tassonomia,
- la posizione,
- varianti e malattie associate,
- Modifica post-traduzionale (PTM),
- l’espressione,
- le interazioni,
- la struttura,
- i domini e la loro classificazione,
- le sequenze
- proteine simili.
La barra di navigazione rimane nella stessa posizione sullo schermo mentre si sale e si scende in una voce, in modo da poter navigare rapidamente verso le sezioni di interesse. Consulteremo separatamente tutte le sezioni citate, ma prima concentriamoci sulle intestazioni a sinistra.
Nella parte superiore della pagina, è possibile vedere l’identificativo e il nome della voce UniProt, il nome della proteina e del gene, l’organismo, se la voce della proteina è stata rivista manualmente da un curatore UniProt, il suo punteggio di annotazione e il livello di evidenza della sua esistenza.
Sotto l’intestazione principale si trova una serie di schede (Ingresso, Variant viewer, Feature viewer, Pubblicazioni, Link esterni, Storia). Le schede consentono di passare dalla voce, alla visualizzazione grafica delle caratteristiche della sequenza (Feature viewer), alle pubblicazioni e ai collegamenti esterni, ma per il momento le ignorano e non si spostano dalla scheda Entry.
Entrata
Il menu successivo fa già parte della scheda Entry. Permette di eseguire una ricerca di similarità di sequenza BLAST sulla voce, di allinearla con tutte le sue isoforme, di scaricare la voce in vari formati o di aggiungerla al carrello per salvarla in seguito.
Domanda
- Quali sono i formati disponibili nel menu a discesa Download?
- Che tipo di informazioni scaricheremmo attraverso questi formati di file?
- I formati sono:
Text,FASTA (canonical),FASTA (canonical & isoform,JSON,XML,RDF/XML,GFF- I formati
FASTAdovrebbero suonare familiari (dopo il tutorial preliminare), e includono la sequenza della proteina, eventualmente con le sue isoforme (nel qual caso si tratterà di un multi-FASTA). Oltre a questi, tutti gli altri formati non sono specifici per le proteine o per la biologia. Si tratta di formati di file generali ampiamente utilizzati dai siti web per includere le informazioni contenute nella pagina. Quindi, scaricando il filetext(o meglio ancora il filejson), si scaricherebbe la stessa annotazione a cui si accede in questa pagina, ma in un formato più facile da analizzare programmaticamente.
Scorriamo ora la pagina di ingresso, sezione per sezione.
Funzione
Questa sezione riassume le funzioni di questa proteina come segue:
I pigmenti visivi sono le molecole che assorbono la luce e che sono alla base della visione. Sono costituiti da un’apoproteina, l’opsina, legata covalentemente alla cis-retina.
Indipendentemente dal livello di dettaglio che si comprende (a seconda del proprio background), questo è impressionantemente breve e specifico, considerando l’enorme quantità di letteratura e di studi che esistono al di là della determinazione della funzione di una proteina. Comunque, qualcuno ha fatto il lavoro per noi e questa proteina è già completamente classificata nella Gene Ontology (GO), che descrive la funzione molecolare, il processo biologico e il componente cellulare di ogni proteina classificata.
GO è un perfetto esempio di database/risorsa che si basa su un universo di conoscenze molto complesso e lo traduce in un grafico più semplice, con il rischio di perdere i dettagli. Questo ha il grande vantaggio di organizzare le informazioni, renderle conteggiabili, analizzabili e programmaticamente accessibili, permettendoci di ottenere queste lunghe pagine riassuntive e le KnowledgeBase.
Domanda
- A quali funzioni molecolari è associata questa proteina?
- A quali componenti cellulari è associata questa proteina?
- A quali processi biologici si riferisce questa proteina?
- Proteina del fotorecettore, recettore accoppiato a proteine G
- Membrana del disco dei fotorecettori
- Trasduzione sensoriale, Visione
Nomi e tassonomia
Altri esempi di informazioni strutturate sono disponibili nella sezione successiva, ad esempio nella tassonomia. Questa sezione riporta anche altri identificatori univoci che si riferiscono alla stessa entità biologica o a entità collegate (ad esempio, le malattie associate nel menu MIM).
Domanda
- Qual è l’identificatore tassonomico associato a questa proteina?
- Qual è l’identificatore del proteoma associato a questa proteina?
- 9606, cioè Homo sapiens
- UP000005640, componente del cromosoma Xs
Posizione subcellulare
Sappiamo già dove si trova la nostra proteina nel corpo umano (nella retina, come specificato dal sommario della funzione), ma dove si trova nella cellula?
Domanda
- Dove si trova la nostra proteina nella cellula?
- È coerente con l’annotazione GO osservata in precedenza?
- La sezione spiega che si tratta di una “proteina di membrana a più passaggi”, il che significa che è una proteina inserita nella membrana cellulare e che la attraversa più volte.
- L’annotazione GO in alto indica che ci stiamo riferendo in particolare alla membrana dei fotorecettori (cellule).
La sezione della localizzazione subcellulare comprende un’area Caratteristiche che specifica quali sezioni, lungo la sequenza della proteina, sono inserite nella membrana (Transmembrana) e quali no (Dominio topologico).
DomandaQuanti domini transmembrana e domini topologici esistono?
8 domini transmembrana e 7 domini topologici
Malattia e Varianti
Come sappiamo dal tutorial precedente, questo gene/proteina è associato a diverse malattie. Questa sezione illustra in dettaglio questa associazione, elencando anche le varianti specifiche che sono state individuate come correlate alla malattia.
DomandaQuali tipi di studi scientifici permettono di valutare l’associazione di una variante genetica alle malattie?
Tre metodi comunemente usati per valutare l’associazione di una variante genetica con una malattia sono:
Studi di associazione a livello di genoma (GWAS)
I GWAS sono ampiamente utilizzati per identificare le varianti genetiche comuni associate alle malattie. Comportano la scansione dell’intero genoma di un gran numero di individui per identificare le variazioni legate a una particolare malattia o tratto.
Studi caso-controllo
Gli studi caso-controllo sono spesso utilizzati per confrontare gli individui affetti da una malattia con quelli che non ne sono affetti, concentrandosi sulla presenza o sulla frequenza di specifiche varianti genetiche in entrambi i gruppi.
Studi sulla famiglia
Gli studi basati sulla famiglia prevedono l’analisi delle varianti genetiche all’interno delle famiglie in cui più membri sono affetti da una malattia. Studiando i modelli di ereditarietà delle varianti genetiche e la loro associazione con la malattia all’interno delle famiglie, i ricercatori possono identificare potenziali geni associati alla malattia.
Questo tipo di studi implica un uso estensivo dei tipi di file per la gestione dei dati genomici, come: SAM (Sequence Alignment Map), BAM (Binary Alignment Map), VCF (Variant Calling Format) ecc.
Questa sezione comprende anche un’area Caratteristiche, dove sono mappate le varianti naturali lungo la sequenza. Di seguito, si evidenzia anche che una vista più dettagliata delle caratteristiche lungo la sequenza è fornita nella scheda Malattie e varianti, ma non apriamola per ora.
PTM/elaborazione
Una modifica post-traduzionale (PTM) è un evento di elaborazione covalente risultante da una scissione proteolitica o dall’aggiunta di un gruppo modificante a un amminoacido.
DomandaQuali sono le modifiche post-traduzionali della nostra proteina?
Catena, glicosilazione, legame disolfuro, residuo modificato
Espressione
Sappiamo già dove si trova la proteina nella cellula, ma per le proteine umane abbiamo spesso informazioni su dove si trova nel corpo umano, cioè in quali tessuti. Queste informazioni possono provenire dallo Human ExpressionAtlas o da altre risorse simili.
DomandaIn quale tessuto si trova la proteina?
I tre pigmenti colorati si trovano nelle cellule dei fotorecettori del cono.
Interazione
Le proteine svolgono la loro funzione attraverso l’interazione con l’ambiente circostante, in particolare con altre proteine. Questa sezione riporta gli interagenti della nostra proteina di interesse, in una tabella che possiamo anche filtrare per localizzazione subcellulare, malattie e tipo di interazione.
La fonte di queste informazioni sono i database come STRING, e la pagina di ingresso della nostra proteina è direttamente collegata a questa sezione.
Pratica: Ricerca di OPN1LW umana su UniProtKB
- Fare clic sul link STRINGA in un’altra scheda
Domanda
- Quanti formati di file diversi si possono scaricare da lì?
- Che tipo di informazioni saranno trasmesse in ogni file?
STRING fornisce dati in formati di file scaricabili per supportare ulteriori analisi. Il formato di file principale utilizzato da STRING è il formato TSV (Tab-Separated Values), che presenta i dati di interazione proteica in un layout strutturato e tabellare. Questo formato è adatto a una facile integrazione in vari strumenti e software di analisi dei dati. Inoltre, STRING offre dati in formato XML PSI-MI (Proteomics Standards Initiative Molecular Interactions), uno standard per la rappresentazione dei dati di interazione proteica che consente la compatibilità con altri database di interazione e piattaforme di analisi. Questi formati di file consentono ai ricercatori di sfruttare la ricchezza di informazioni sulle interazioni proteiche di STRING per i propri studi e analisi. I ricercatori possono anche scaricare rappresentazioni visive delle reti proteiche in formati immagine come PNG e SVG, adatti per presentazioni e pubblicazioni. Per le analisi avanzate, STRING offre “file piatti” contenenti informazioni dettagliate sulle interazioni e file “MFA” (Multiple Alignment Format), utili per confrontare più sequenze di proteine. Questi diversi formati di file scaricabili consentono ai ricercatori di sfruttare la ricchezza di informazioni sulle interazioni proteiche di STRING per i propri studi e analisi.
Struttura
Siete curiosi di conoscere le intricate strutture tridimensionali delle proteine? La sezione Struttura della pagina di ingresso di UniProtKB è la porta d’accesso per esplorare l’affascinante mondo dell’architettura delle proteine.
In questa sezione troverete informazioni sulle strutture proteiche determinate sperimentalmente. Queste strutture forniscono informazioni cruciali sul funzionamento delle proteine e sulla loro interazione con altre molecole. Si possono scoprire visualizzazioni interattive della struttura della proteina che possono essere esplorate direttamente all’interno della voce UniProtKB. Questa funzione offre un modo accattivante per navigare tra i domini, i siti di legame e altre regioni funzionali della proteina. Approfondendo la sezione Struttura, si potrà comprendere meglio la base fisica della funzione delle proteine e scoprire la ricchezza di informazioni che i dati strutturali possono svelare.
Domanda
- Qual è la variante associata al daltonismo?
- Riesci a trovare quello specifico amminoacido nella struttura?
- Puoi formulare un’ipotesi sul motivo per cui questa mutazione è dirompente?
- Nella sezione Malattie e varianti, scopriamo che il cambiamento da glicina (G) ad acido glutammico (E) nella posizione 338 della sequenza proteica è associato al daltonismo.
- nel visualizzatore di strutture, possiamo muovere la molecola e passare il mouse sulla struttura per trovare l’AA in posizione 338. Potrebbe essere necessario un po’ di tempo per seguire le molteplici disposizioni elicoidali di queste strutture. La glicina in posizione 338 non si trova in un’elica, ma in quella che sembra un’ansa appena prima di un’area a bassa confidenza nella struttura.
- Sulla base delle informazioni raccolte finora, potremmo formulare un’ipotesi sul motivo per cui questo è distruptivo. Non è in un’elica (di solito, nelle proteine transmembrana, le eliche sono inserite nella membrana), quindi è in uno dei domini più grandi che sporgono dalla membrana, dentro o fuori la cellula. Questa mutazione probabilmente non interrompe la struttura nei suoi segmenti intra-membrana, ma piuttosto uno dei domini funzionali. Se si desidera approfondire, è possibile verificare se si tratta del segmento extra- o intra-cellulare nel Feature viewer.
Da dove provengono le informazioni nel visualizzatore di strutture?
Pratica: Ricerca di OPN1LW umano su UniProtKB
- Fare clic sull’icona di download sotto la struttura
- Controllare il file che è stato scaricato
Questo è un file PDB (Protein Data Bank) che consente di visualizzare e analizzare la disposizione degli atomi e degli amminoacidi della proteina.
Tuttavia, non c’è alcun riferimento al database PDB nei collegamenti tra i database delle strutture 3D. Invece, il primo link fa riferimento all’AlphaFoldDB. Il database AlphaFold è una risorsa completa che fornisce strutture 3D previste per un’ampia gamma di proteine. Utilizzando tecniche di deep learning e informazioni evolutive, AlphaFold predice la disposizione spaziale degli atomi all’interno di una proteina, contribuendo alla comprensione della funzione e delle interazioni proteiche.
Si tratta quindi di una predizione della struttura, non di una struttura convalidata sperimentalmente. Questo è il motivo per cui è colorato in base alla confidenza: le sezioni in blu sono quelle con un alto valore di confidenza, quindi quelle per cui la predizione è molto affidabile, mentre quelle in arancione sono meno affidabili o hanno una struttura disordinata (più flessibile e mobile). Tuttavia, queste informazioni sono rappresentate attraverso un file PDB, perché sono comunque strutturali.
Famiglia e domini
La sezione Famiglia e domini nella pagina della voce UniProtKB fornisce una visione completa delle relazioni evolutive e dei domini funzionali di una proteina. Questa sezione offre informazioni sull’appartenenza della proteina a famiglie, superfamiglie e domini, facendo luce sulle sue caratteristiche strutturali e funzionali.
L’area Caratteristiche conferma effettivamente che almeno uno dei due domini che sporgono dalla membrana (quello N-terminale) è disordinato. Quest’area di solito include informazioni su regioni conservate, motivi e caratteristiche di sequenza importanti che contribuiscono al ruolo della proteina in vari processi biologici. La sezione conferma ancora una volta che siamo di fronte a una proteina transmembrana e rimanda a diverse risorse di dati filogenetici, famiglie di proteine o domini, che ci guidano nella comprensione di come le proteine condividano un’ascendenza comune, si evolvano e acquisiscano funzioni specializzate.
Sequenza
Tutte queste informazioni sull’evoluzione, la funzione e la struttura della proteina sono codificate nella sua sequenza. Ancora una volta, in questa sezione abbiamo la possibilità di scaricare il file FASTA che la trascrive, nonché di accedere alla fonte di questi dati: gli esperimenti di sequenziamento genomico che li hanno valutati. Questa sezione riporta anche i casi in cui sono state rilevate isoforme.
DomandaQuante potenziali isoforme sono mappate su questa voce?
1: H0Y622
Proteine simili
L’ultima sezione della pagina UniProt Entry riporta le proteine simili (si tratta sostanzialmente del risultato di un clustering, con soglie di identità del 100%, 90% e 50%).
Domanda
- Quante proteine simili hanno un’identità del 100%?
- Quante proteine simili hanno un’identità del 90%?
- Quante sono le proteine simili al 50% di identità?
- 0
- 83
- 397
Come avrete intuito consultando questa pagina, gran parte dell’elaborazione dei dati biologici su una proteina consiste nel mappare diversi tipi di informazioni lungo la sequenza e capire come si influenzano a vicenda. Una mappatura visiva (e una tabella con le stesse informazioni) è fornita dalle due schede alternative per visualizzare questa voce, cioè il Variant viewer e il Feature viewer.
Visualizzazione delle varianti
Pratica: Visualizzazione delle varianti
- Cliccare sulla scheda Variant viewer
Il Variant viewer mappa tutte le versioni alternative note di questa sequenza. Per alcune di esse l’effetto (patogeno o benigno) è noto, per altre no.
DomandaQuante varianti sono probabilmente patogene?
ingrandendo la vista delle varianti, vediamo che abbiamo 5 punti rossi, quindi 5 varianti probabilmente patogene.
L’elevato numero di varianti che si trovano in questa sezione suggerisce che le “sequenze proteiche” (così come le sequenze geniche, le strutture proteiche ecc.) sono in realtà entità meno fisse di quanto si possa pensare.
Visualizzazione delle caratteristiche
Pratica: Visualizzazione delle caratteristiche
- Fare clic sulla scheda Feature viewer
Il Feature viewer è fondamentalmente una versione fusa di tutte le aree Features che abbiamo trovato nella pagina Entry, tra cui Domains & sites, Molecule processing, PTMs, Topology, Proteomics, Variants. Se nel visualizzatore si fa clic su una qualsiasi caratteristica, la regione corrispondente nella struttura verrà messa a fuoco, come variante di interesse
Pratica: Variante visualizzatore
- espandere la parte Varianti
- Zoom out
- Fare clic sulla variante di interesse (il punto rosso in posizione 338)
DomandaQual è la topologia in questa posizione?
Un dominio topologico citoplasmatico
Infine, diamo una rapida occhiata alle altre schede.
Pubblicazioni
Pratica: Pubblicazione
- Fare clic sulla scheda Pubblicazione
La sezione Pubblicazioni elenca le pubblicazioni scientifiche relative alla proteina. Queste sono raccolte unendo un elenco completamente curato in UniProtKB/Swiss-Prot e un elenco importato automaticamente. In questa scheda è possibile filtrare l’elenco delle pubblicazioni in base alla fonte e alle categorie che si basano sul tipo di dati contenuti in una pubblicazione sulla proteina (come funzione, interazione, sequenza, ecc.) o sul numero di proteine nello studio corrispondente che descrive (“small scale” vs “large scale”).
Domanda
- Quante pubblicazioni sono associate a questa proteina?
- quante pubblicazioni contengono informazioni sulla sua funzione?
- 57
- 23
Collegamenti esterni
Pratica: Collegamenti esterni
- Fare clic sulla scheda Collegamenti esterni
La scheda Collegamenti esterni riunisce tutti i riferimenti a banche dati e risorse di informazione esterne che abbiamo trovato in ogni sezione della pagina di entrata. Il testo dei link riporta spesso gli identificatori unici che rappresentano la stessa entità biologica in altri database. Per avere un’idea di questa complessità, si veda l’immagine seguente (che è già parzialmente obsoleta).
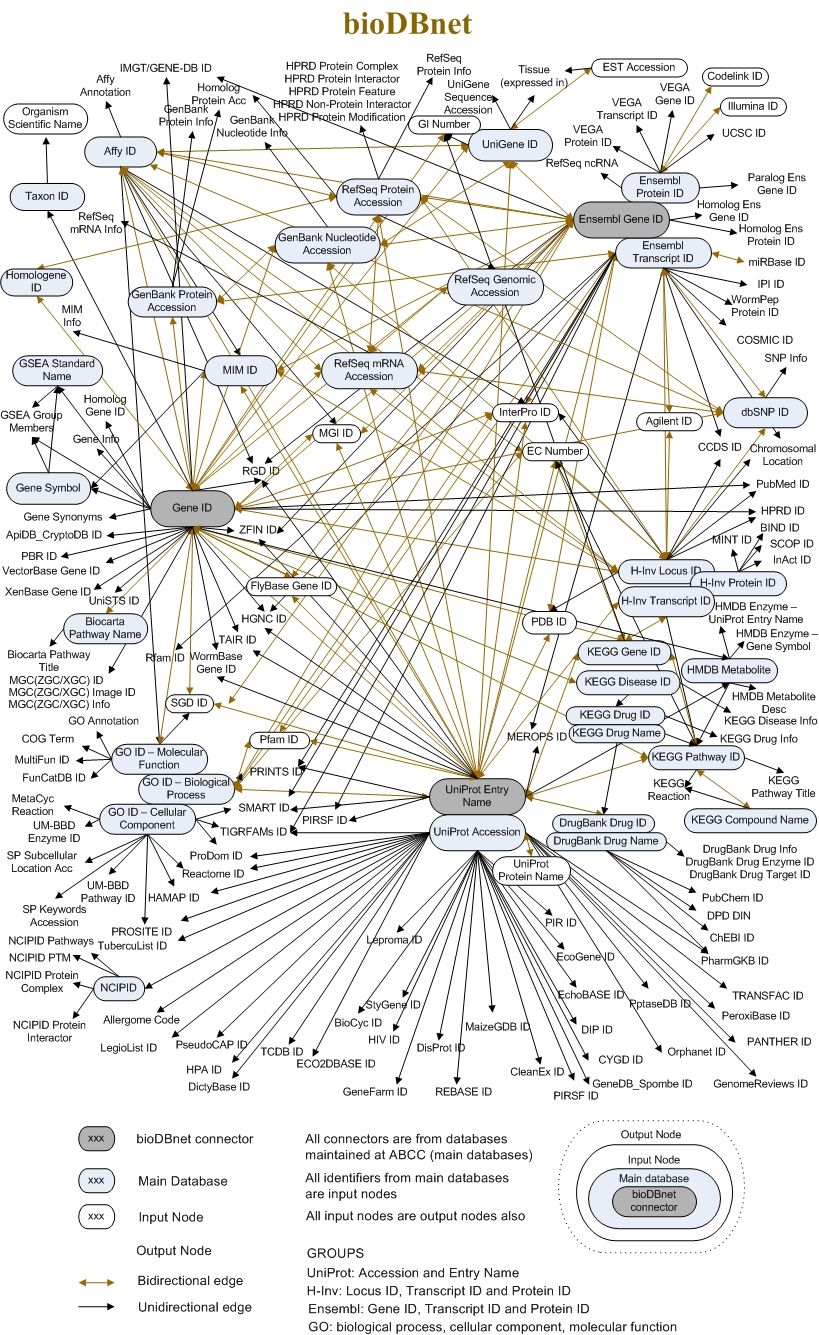 Open image in new tab
Open image in new tabStoria
Infine, anche la scheda Storia è interessante. Riporta e rende disponibili per il download tutte le versioni precedenti delle annotazioni di questa voce, cioè tutta l’“evoluzione” della sua annotazione, in questo caso risalente al 1988.
DomandaQuesta voce non è mai stata annotata automaticament?
Per rispondere a questa domanda si può scorrere indietro nel tempo nella tabella e controllare la colonna
Database. Questa voce è mai stata inserita in TrEMBL invece che in SwissProt? No, quindi questa voce è stata annotata manualmente fin dall’inizio.
Hai completato il tutorial
Punti chiave
Come navigare tra le voci di UniProtKB, accedendo a dettagli completi sulle proteine, come funzioni, tassonomia e interazioni.
Il visualizzatore di varianti e caratteristiche è uno strumento utile per esplorare visivamente varianti proteiche, domini, modifiche e altre caratteristiche chiave della sequenza.
Amplia le tue conoscenze utilizzando link esterni per incrociare i dati e scoprire relazioni complesse.
Esplora la scheda Cronologia per accedere alle versioni precedenti delle annotazioni delle voci.
Domande frequenti
Hai domande su questo tutorial? Dai un'occhiata alle FAQ disponibili e ai canali di supportoFeedback
Hai usato questo materiale come istruttore? Sentiti libero di lasciarci un feedback. Com'è andata.
Hai usato questo materiale come studente? Clicca sul modulo qui sotto per lasciare un feedback.

Citare questo tutorial
- Lisanna Paladin, Bérénice Batut, Una proteina lungo la pagina UniProt (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-protein/tutorial_IT.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{data-science-online-resources-protein, author = "Lisanna Paladin and Bérénice Batut", title = "Una proteina lungo la pagina UniProt (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-protein/tutorial_IT.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Riferimenti
Queste persone o organizzazioni hanno fornito supporto finanziario per lo sviluppo di questa risorsa
Congratulazioni per aver completato con successo questo tutorial!