Learning about one gene across biological resources and formats
Under Development!
This tutorial is not in its final state. The content may change a lot in the next months. Because of this status, it is also not listed in the topic pages.
| Author(s) |
|
| Reviewer(s) |
|
OverviewQuestions:
Objectives:
How to employ bioinformatics resources to investigate a specific protein family (opsins)?
How to navigate the Genome Data Viewer to find opsins in the human genome?
How to identify genes associated with opsins and analyze their chromosome locations?
How to explore literature and clinical contexts for the OPN1LW gene?
How to use protein sequences files to perform similarity searches using BLAST?
Starting from a text search, navigate multiple web resources to examine multiple types of information about a gene, conveyed through multiple file formats.
Time estimation: 1 hourLevel: Introductory IntroductorySupporting Materials:Published: Sep 7, 2023Last modification: Mar 30, 2026License: Tutorial content is licensed under Creative Commons Attribution 4.0 International License. The GTN framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00359version Revision: 4
When we do a bioinformatics analysis, e.g. RNA-seq, we might end up with a list of gene names. We then need to explore these genes. But how can we do that? What are the resources available for that? And how to navigate through them?
The aim of this tutorial is to familiarize ourselves with that, using Human opsins as an example.
Human opsins are found in the cells of your retina. Opsins catch light and begin the sequence of signals that result in vision. We will proceed by asking questions about opsins and opsin genes, and then using different bioinformatics databases and resources to answer them.
CommentThis tutorial is a bit atypical: we will not work in Galaxy but mostly outside of it, navigating databases and tools through their own web interfaces. The scope of this tutorial is to illustrate several sources of biological data in different file formats, and representing different information.
AgendaIn this tutorial we will deal with:
Searching Human Opsins
To seach Human Opsins, we will start by checking the NCBI Genome Data Viewer. The NCBI Genome Data Viewer (GDV) (Rangwala et al. 2021) is a genome browser supporting the exploration and analysis of annotated eukaryotic genome assemblies. The GDV browser displays biological information mapped to a genome, including gene annotation, variation data, BLAST alignments, and experimental study data from the NCBI GEO and dbGaP databases. GDV release notes describe new features relating to this browser.
Hands On: Open NCBI Genome Data Viewer
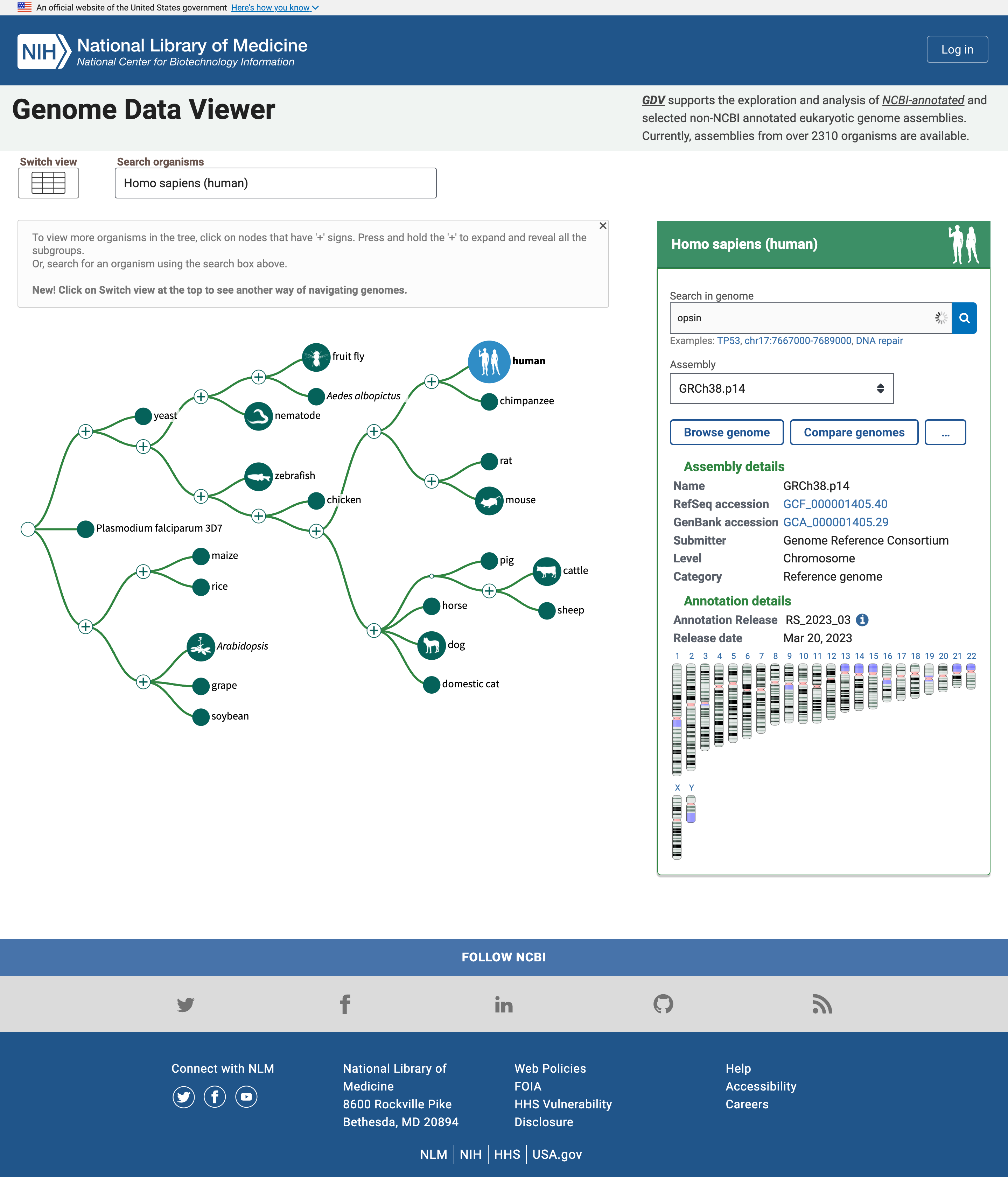
- Open the NCBI Genome Data Viewer at www.ncbi.nlm.nih.gov/genome/gdv
The homepage includes a simple “tree of life” where the human node is highlighted because it is the default organism to search. We can change that in the Search organisms box but we will leave for now as we are interested in Human Opsins.
 Open image in new tab
Open image in new tabThe panel on the right reports multiple assemblies of the genome of interest, and a map of the chromosomes in that genome. We can search for Opsins there.
Hands On: Search for OpsinsOpen NCBI Genome Data Viewer
- Type
opsinin the Search in genome box- Click on the magnifier icon or press Enter
Below the box is now displayed a table with genes related to opsin together with their names and location, i.e. the chromosome number, as well ass the start and end position
In the list of genes related to the search term opsin, there are the rhodopsin gene (RHO), and three cone pigments, short-, medium-, and long-wavelength sensitive opsins (for blue, green, and red light detection). There are other entities, e.g. a -LCR (Locus Control region), putative genes and receptors.
Multiple hits are on the X chromosome, one of the sex-determining chromosomes.
Question
- How many genes have been found in Chromosome X?
- How many are protein coding genes?
- The hits in ChrX are:
- OPSIN-LCR
- OPN1LW
- OP1MW
- OPN1MW2
- OPN1MW3
- By hovering over each gene, a box open and we can click on Details to learn more about each gene. Then we learn that the first (OPSIN-LCR) is not protein coding but a gene regulatory region and the other are protein coding genes. So there are 4 protein coding genes related to opsins in Chromosome X. In particular, Chromosome X includes one red pigment gene (OPN1LW) and three green pigment genes (OPN1MW, OPN1MW2 and OPN1MW3 in the reference genome assembly).
Let’s now focus on one specific opsin, the gene OPN1LW.
Hands On: Open Genome Browser for gene OPN1LW
- Click on the blue arrow that appears in the results table when you hover your mouse on the OPN1LW row
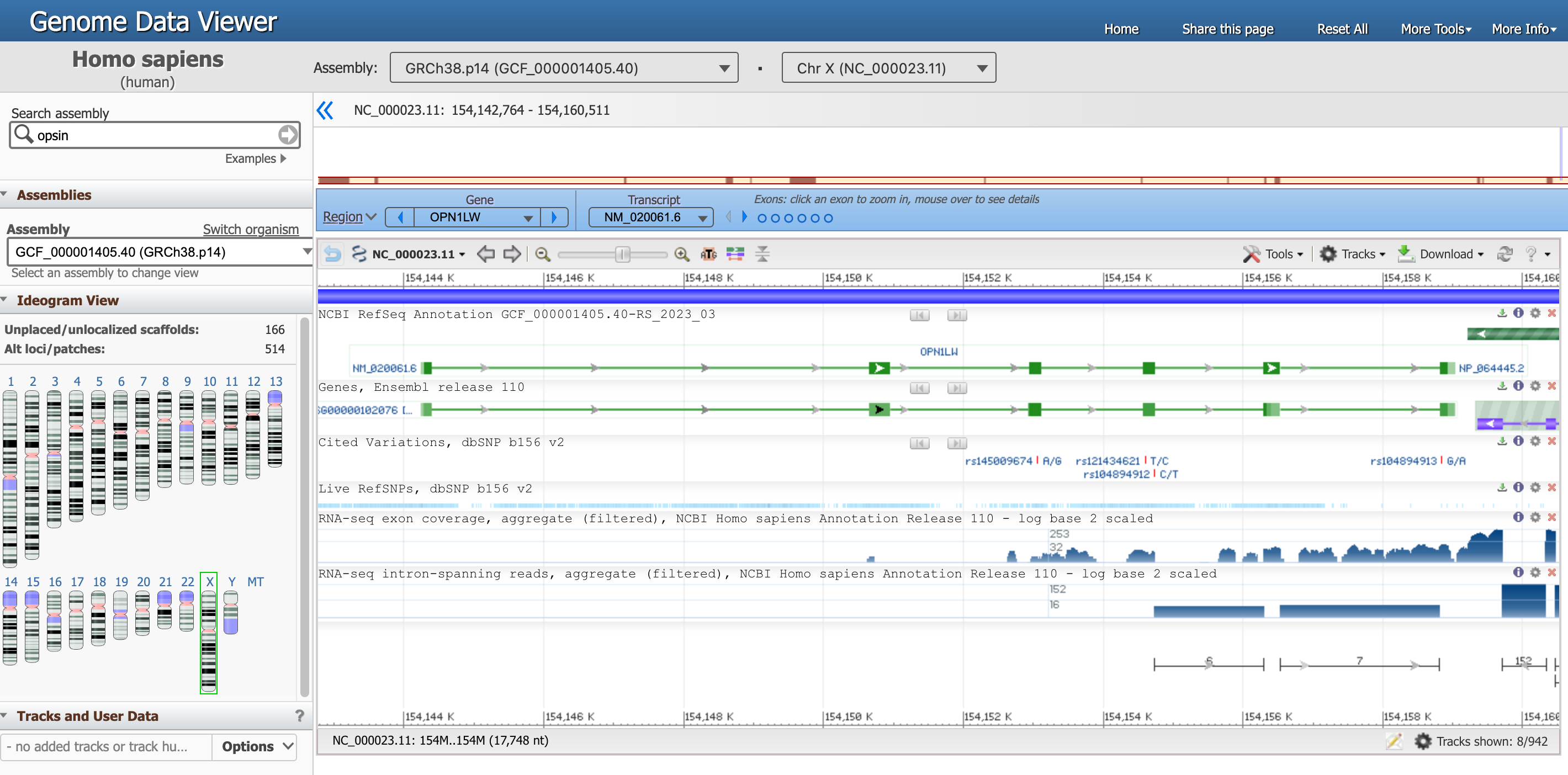
You should have landed in this page, that is the genome view of gene OPN1LW.
 Open image in new tab
Open image in new tabThere is a lot of information in this page, let’s focus on one section at the time.
- The Genome Data Viewer, on the top, tells us that we are looking at the data from the organism
Homo sapiens, assemblyGRCh38.p14and in particular atChr X(Chromosome X). Each of these information has a unique ID. - The entire Chromosome is represented directly below, and the positions along the short (
p) and long (q) arms are highlihgted. -
Below, a blue box highlights that we are now focusing on the Region corresponding to the Gene
OPN1LW.There are multiple ways to interact with the viewer below. Try for example to hover with the mouse on the dots representing exons in the blue box.
-
In the graph below, the gene requence is a green line with the exons (protein coding fragments) represented by green rectangles.
Hover with the mouse on the green line corresponding to
NM_020061.6(our gene of interest) to get more detailed information.Question- What is the location of the OPN1LW segment?
- What is the length of the OPN1LW segment?
- What are introns and exons?
- How many exons and introns are in the OPN1LW gene?
- What is the total length of the coding region?
- What is the distribution between coding and non coding regions? What does that mean in term of biology?
- What is the lenght of the protein in number of amino acids?
- From 154,144,243 to 154,159,032
- 1,4790 nucleotides, found at Span on 14790 nt, nucleotides)
- Eukaryotic genes are often interrupted by non-coding regions called intervening sequences or introns. The coding regions are called exons.
- From this diagram, you can see that the OPN1LW gene consists of 6 exons and 5 introns, and that the introns are far larger than the exons.
- The CDS length is 1,095 nucleotides.
- Of the 14790 nt in the gene, only 1095 nt code for protein, which means that less than 8% of the base pairs contain the code. When this gene is expressed in cells in the human retina, an RNA copy of the entire gene is synthesized. Then the intron regions are cut out, and the exon regions joined together to produce the mature mRNA (a process called splicing). which will be translated by ribosomes as they make the red opsin protein. In this case, 92% of the initial RNA transcript is tossed out, leaving the pure protein code.
- The length of the resulting protein is 364 aa, amino acids.
But what is the sequence of this gene? There are multiple ways to retrieve this information, we will go through what we think is one of the most intituitive.
Hands On: Open Genome Browser for gene OPN1LW
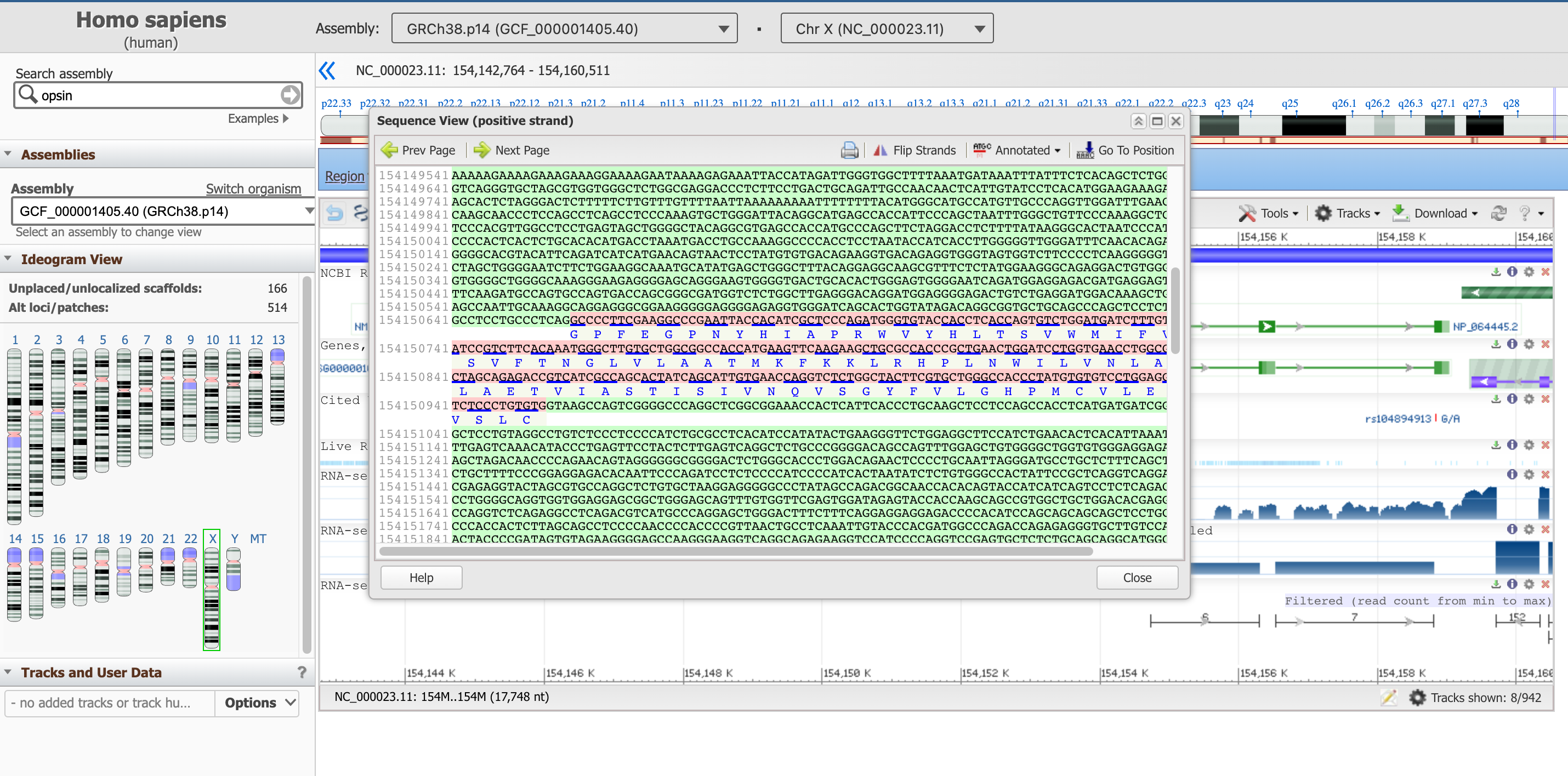
- Click on the tool Tools section on the top right of the box showing the gene
- Click on Sequence Text View
This panel reports the DNA sequence of the introns (in green), as well as the one of the exons (in pink, including the translated protein sequence below).
 Open image in new tab
Open image in new tabThis sequence box is not showing the entire gene at the moment, but a subsequence of it. You can move upstream and downstream the genetic code with the arrows Prev Page and Next Page, or start from a specific position with the Go To Position button. We suggest to start with the start of the coding part of the gene, which as we learned earlier is at position 154,144,243.
Hands On: Go to a specific position in Sequence View
- Click on Go To Position
Type on
154144243We have to remove the commas to validate the value
The sequence highlighted in purple here signals a regulatory region.
Question
- What is the first amino acid of the resulting protein product?
- What is the last one?
- Can you keep a note of the first three and last three AAs of this protein?
- The correspondent protein starts with Methionine, M (they all do).
- The last AA of the last exon (found in the 2nd page) is Alanine (A). After that, the stop codon TGA comes, which is not translated into an AA.
- The first three AAs are: M,A,Q; the last three: S,P,A.
We can now close the Sequence View.
From this resource, we can also get files, in different format, describing the gene. They are available from the Download section.
- Download FASTA will allow us to download the simplest file format to represent the nucleotide sequence of all the visible range of the genome (longer than the gene only).
- Download GenBank flat file will allow us to access the annotation avaible on this page (and beyond) in a flat text format.
- Download Track Data allows us to inpect two of the file formats we presented in the slides: the GFF (GFF3) and BED formats. If you change the tracks, each one may or may not be available.
Finding more information about our gene
Let’s now get an overview of the information we have (in the literature) about our gene, using the NCBI resources
Hands On: Go to a specific position in Sequence View
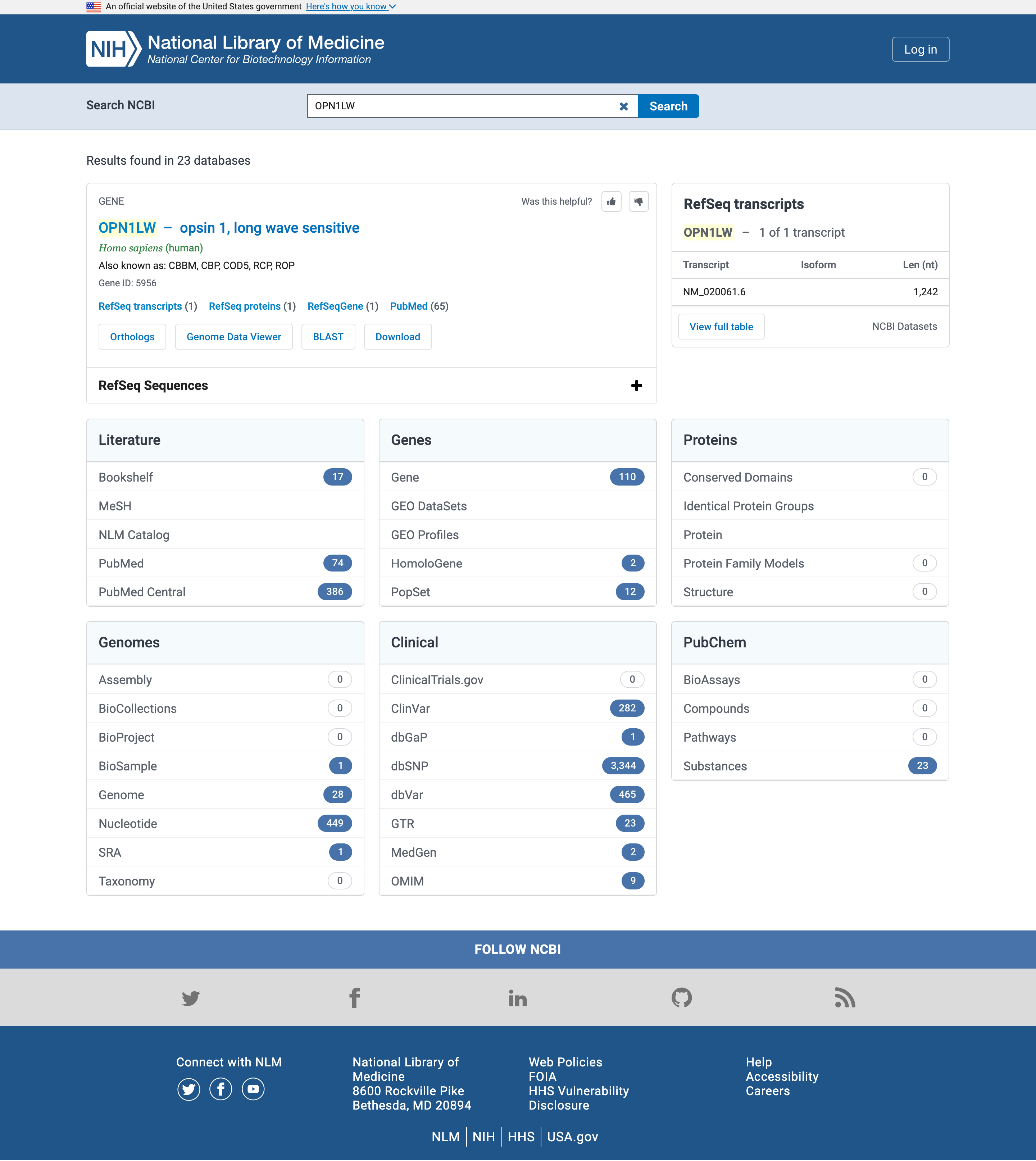
- Open the NCBI search at www.ncbi.nlm.nih.gov/search
- Type
OPN1LWin the Search NCBI search box
 Open image in new tab
Open image in new tab.
Literature
Let’s start with the literature and in particular PubMed or PubMed Central results
PubMed is a biomedical literature database which contains the abstracts of publications in the database.
PubMed Central is a full text repository, which contains the full text of publications in the database.
While the exact number of hits may vary in time from the screenshot above, any gene name should have more hits in PubMed Central (searched in the full texts of publications) than in PubMed (searched only in the abstracts).
Hands On: Open PubMed
- Click on PubMed in the Literature box
You have entered PubMed, a free database of scientific literature, to the results of a complete search for articles directly associated with this gene locus.
By clicking on the title of each article, you can see abstracts of the article. If you are on a university campus where there is online access to specific journals, you might also see links to full articles. PubMed is your entry point to a wide variety of scientific literature in the life sciences. On the left side of any PubMed page, you will find links to a description of the database, help, and tutorials on searching.
Question
- Can you guess which type of conditions are associated to this gene?
- We will answer this question later
Hands On: Back to NCBI Search page
- Go back the NCBI Search page
Clinical
Let’s now focus on the Clinical box, and specially on OMIM. OMIM, the Online Mendeliam Inheritance in Man (and woman!), is a catalog of human genes and genetic disorders.
Hands On: Open OMIM
- Click on OMIM in the Clinical box
Each OMIM entry is a genetic disorder (here mostly types of colorblindness) associated with mutations in this gene.
Hands On: Read as much as your interest dictates
- Follow links to get more information about each entry
Comment: Read as much as your interest dictatesFor more information about OMIM itself, click the OMIM logo at the top of the page. Through OMIM, a wealth of information is available for countless genes in the human genome, and all information is backed up by references to the latest research articles.
How do variations in the gene affect the protein product, and its functions? Let’s go back to the NIH page and investigate access the list of Single Nucleotide Polymorphisms (SNPs) that were detected by genetics studies in the gene.
Hands On: Open dbSNP
- Go back the NCBI Search page
- Click on dbSNP in the Clinical box
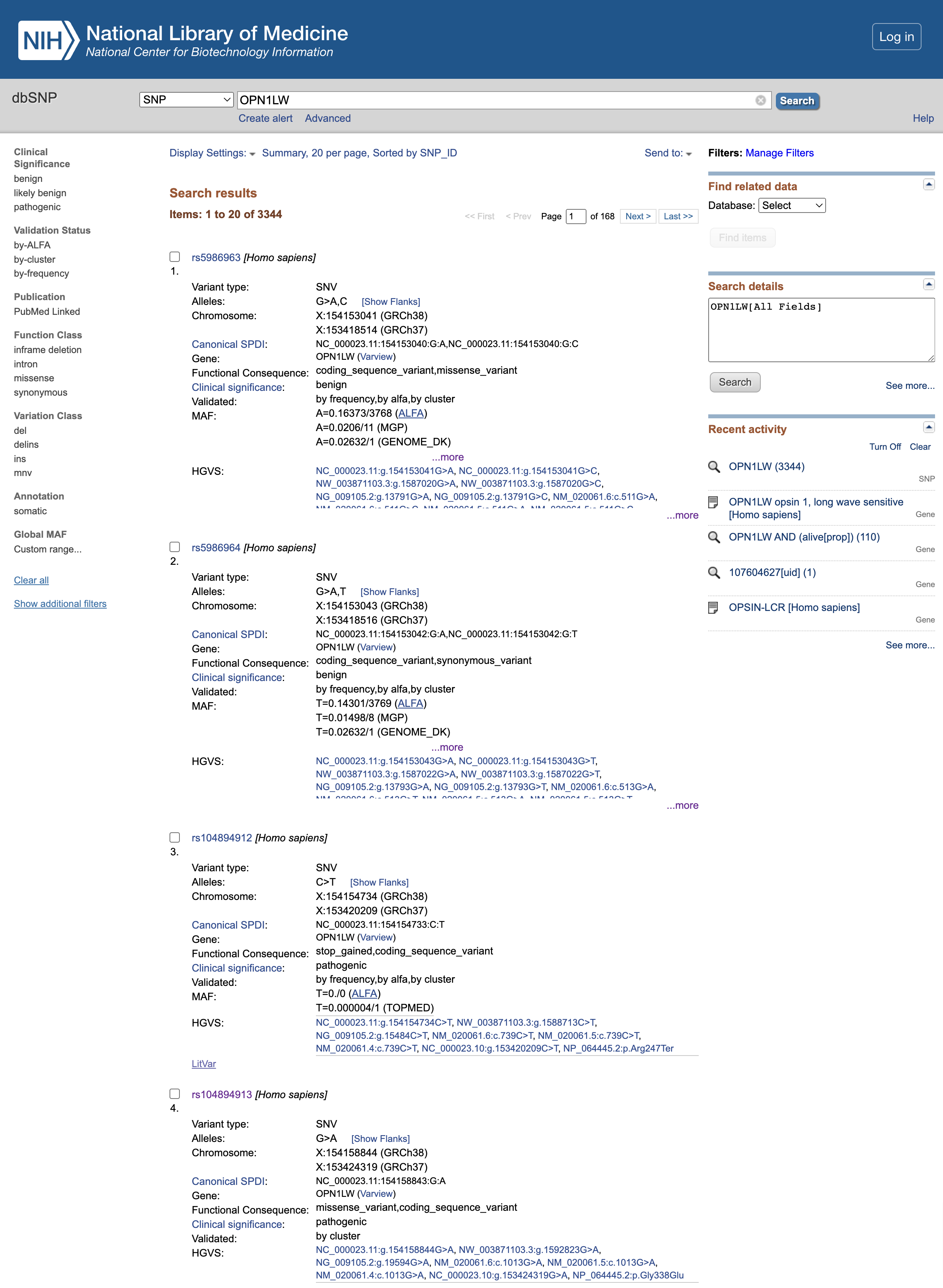 Open image in new tab
Open image in new tabQuestion
- What is the clinical significance of the rs5986963 and rs5986964 (first 2 variants listed at the time of creation of this tutorial)?
- What is the functional consequence of rs104894912?
- What is the functional consequence of rs104894913?
- The Clinical significance is
benignso it seems that they have no effect on the final protein product- rs104894912 mutation leads to a
stop_gainedvariant, which truncates the resulting protein too early and is thereforepathogenic- rs104894913 mutation leads to a
missense_variant, alsopathogenic.
Let’s investigate about more on the rs104894913 variant
Hands On: Learn more about a variant dbSNP
- Click on
rs104894913to open its dedicated pageClick on Clinical Significance
QuestionWhat type of condition is associated with the rs104894913 variant?
The name of the associated disease is “Protan defect”. A quick internet search with your search engine will clarify that this is a type of color blindness.
Click on the Variant details
Question
- Which substitution is associated with this variant?
- What is impact of this subtitution in term of codon and amino acid?
- At which position of the protein is this substitution?
- The substitution
NC_000023.10:g.153424319G>Acorresponds to change from a Guanine (G) to an Adenine (A)- This substitution change the codon
GGG, a Glycine, intoGAG, a Glutathionep.Gly338Glumeans that the substitution is at position 338 of the protein.
What does this mean this substitution for the protein? Let’s have a deeper look at this protein.
Protein
Hands On: Open Protein
- Go back the NCBI Search page
- Click on Protein in the Proteins box
- Click on
OPN1LW – opsin 1, long wave sensitivein the box on top
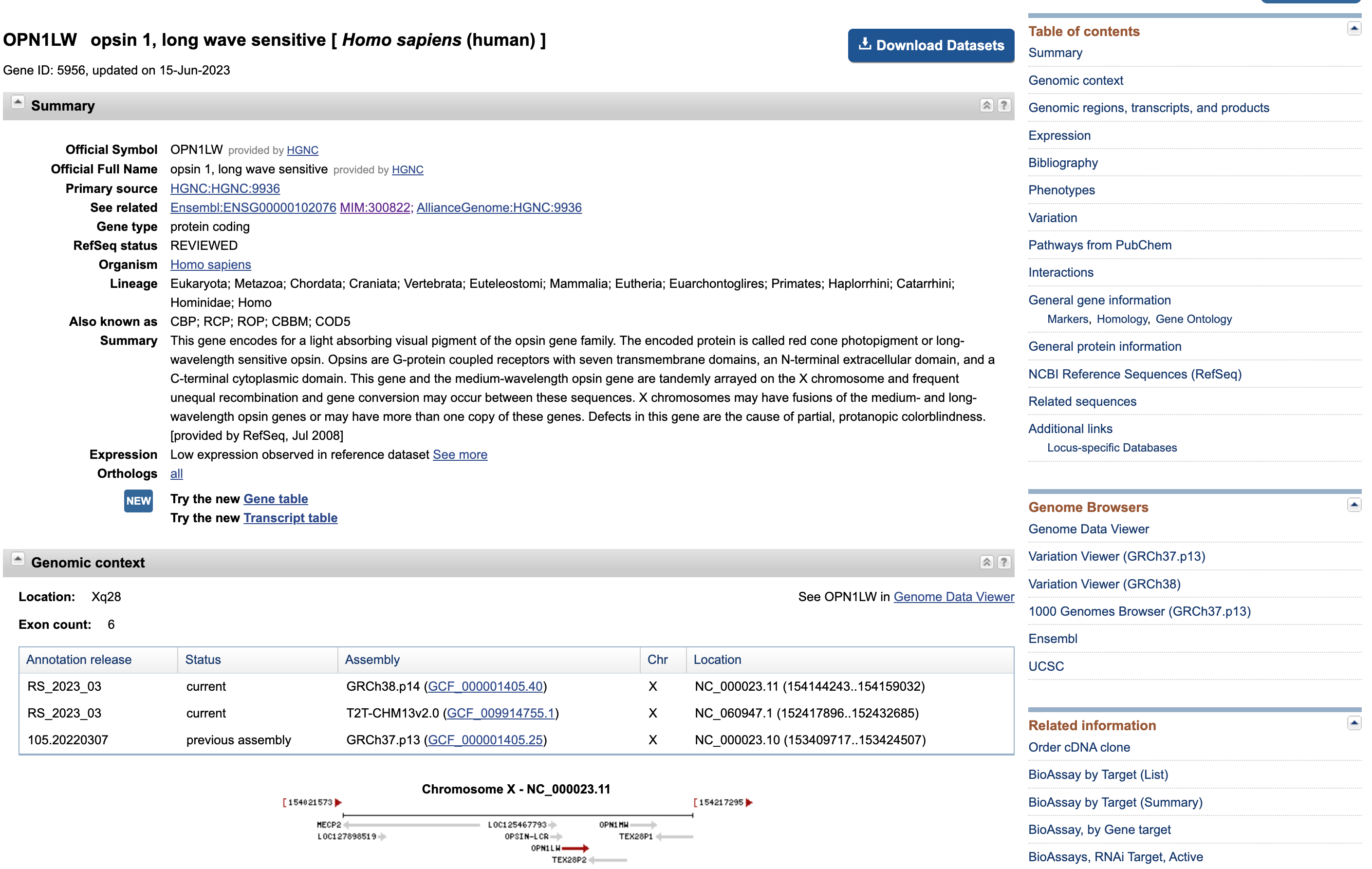 Open image in new tab
Open image in new tabThis page presents once again some data that we are familiar with (e.g. distribution of the exons along the gene sequence).
Hands On: Download the protein sequences
- Click on Download Datasets
- Select
Gene Sequences (FASTA)Transcript sequences (FASTA)Protein sequences (FASTA)- Click on Download button
- Open the downloaded ZIP file
Question
- What does the folder contain?
- Do you think they implemented good data practices?
- The folder includes
- a folder
ncbi_datasetswith different subfolders in it leadig some data files (multiple formats),- a
README.md(a Markdown file), which is designed to “travel” together with the data and explain how was the data retreived, what is the structure of the data containing subfolder, and where to find extensive documentation.- It is definitely a good data management practice to guide users (not only your collaborators, but also yourself in the not-so-far future, when you will forget where does that file in your Downloads folder come from) to the data source and the data structure.
Searching by sequence
What could we do with these sequences that we just downloaded? Let’s assume that we just sequenced the transcripts that we isolated through an experiment - so we know the sequence of our entity of interest, but don’t know what it is. What we need to do in this case is to search the entire database of sequences known to science and match our unknown entity with an entry that has some annotation. Let’s do it.
Hands On: Search the protein sequence against all protein sequences
- Open (with the simplest text editor you have installed) the
protein.faafile that you just downloaded.- Copy its contents
- Open BLAST blast.ncbi.nlm.nih.gov
Click on the
Protein BLAST, protein > proteinWe will indeed use a protein sequence to search against a database of proteins
- Paste the protein sequence into the big text box
- Check the rest of parameters
- Click the blue button
BLAST
This phase will take some time, there is afterall some server somewhere that is comparing the entirety of known sequences to your target. When the search is complete, the result should look similar to the one below:
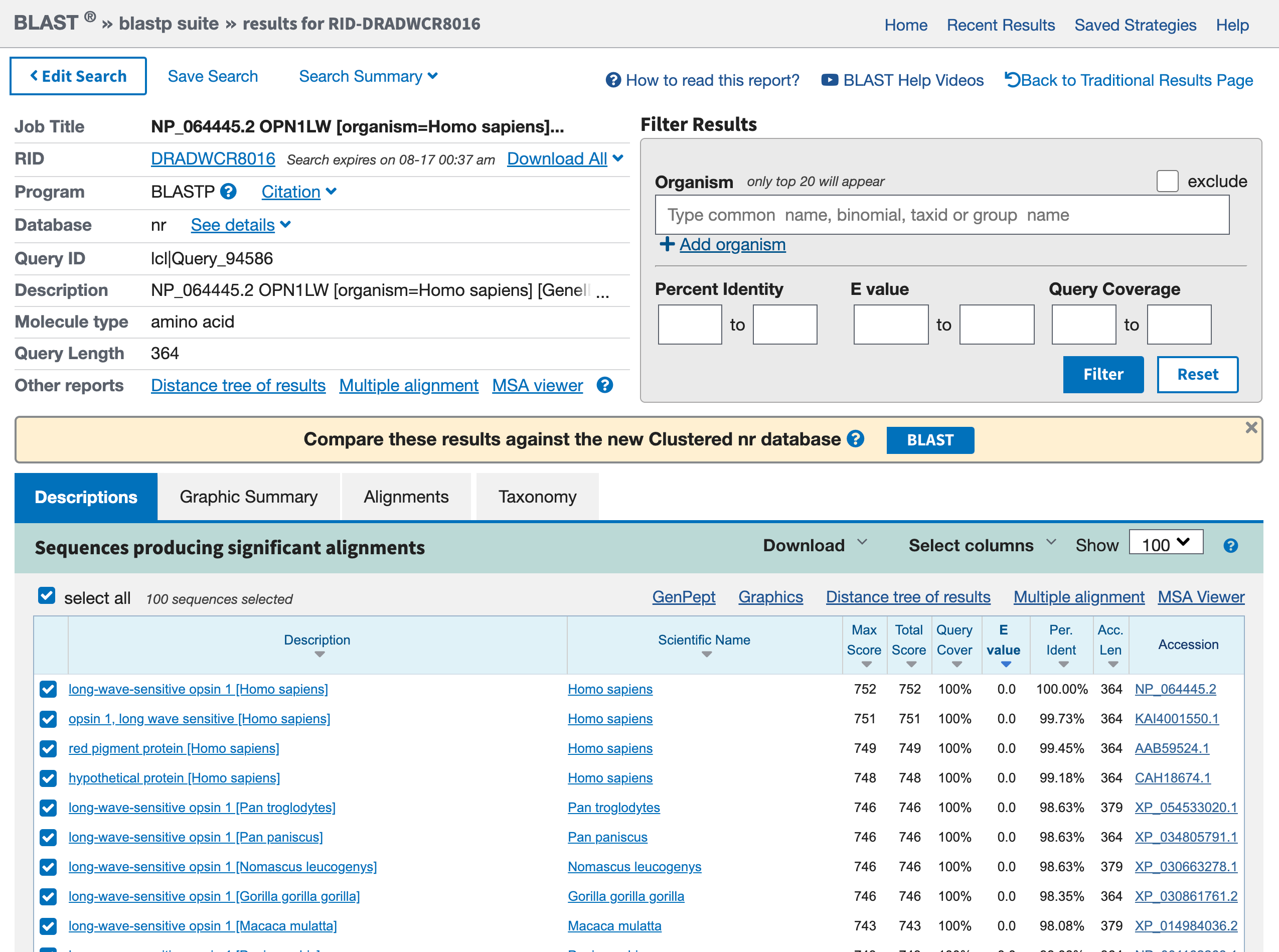 Open image in new tab
Open image in new tabHands On: Graphic Summary of the protein sequences
- Click on the tab Graphic Summary
We access a box containing lots of colored lines. Each line represents a hit from your blast search. If you click on a red line, the narrow box just above the box gives a brief description of the hit.
Hands On: Descriptions of the protein sequences
- Click on the tab Descriptions
Question
- What is the first hit? Is it expected?
- What are the other hits? For which organisms?
- The first hit is our red opsin. That’s encouraging, because the best match should be to the query sequence itself, and you got this sequence from that gene entry.
- Other hits are other opsins. They include entries from other primates (e.g.
Pan troglogytes).
The hits are for our red opsin in human but also other opsins in other primates. We could want that, for example if we wanted to use this data to build a phylogenetic tree. If we instead are pretty sure that our sequence of interest is human, we could also have filtered the search only in human sequences.
Hands On: Filter a BLAST Search
- Click on Edit Search
- Type
Homo sapiensin Organism field- Click the blue button
BLAST
With this new search, we find the other opsins (green, blue, rod-cell pigment) in the list. Other hits have lower numbers of matching residues. If you click on any of the colored lines in the Graphic Summary, you’ll open more information about that hit, and you can see how much similarity each one has to the red opsin, our original query sequence. As you go down the list, each succeeding sequence has less in common with red opsin. Each sequence is shown in comparison with red opsin in what is called a pairwise sequence alignment. Later, you’ll make multiple sequence alignments from which you can discern relationships among genes.
The displays contain two prominent measures of the significance of the hit:
the BLAST Score - lableled Score (bits)
The BLAST Score indicates the quality of the best alignment between the query sequence and the found sequence (hit). The higher the score, the better the alignment. Scores are reduced by mismatches and gaps in the best alignment. Calculation of the score is complex, involving a substitution matrix, which is a table that assigns a score to each pair of residues aligned. The most widely used matrix for protein alignment is known as BLOSUM62.
the Expectation Value (labeled Expect or E)
The expectation value E of a hit tells whether the hit is likely be result from chance likeness between hit and query, or from common ancestry of hit and query. ()
Comment: Filter a BLAST SearchIf E is smaller than \(10\mathrm{e}{-100}\), it is sometimes given as 0.0.
The expectation value is the number of hits you would expect to occur purely by chance if you searched for your sequence in a random genome the size of the human genome.
\(E = 25\) means that you could expect to find 25 matches in a genome of this size, purely by chance. So a hit with \(E = 25\) is probably a chance match, and does not imply that the hit sequence shares common ancestry with your search sequence.
Expectation values of around 0.1 may or may not be biologically significant (other tests would be needed to decide).
But very small values of E mean that the hit is biologically significant. The correspondence between your search sequence and this hit must arise from common ancestry of the sequences, because the odds are are simply too low that the match could arise by chance. For example, \(E = 10\mathrm{e}{-18}\) for a hit in the human genome means that you would expect only one chance match in one billion billion different genomes the same size of the human genome.
The reason we believe that we all come from common ancestors is that massive sequence similarity in all organisms is simply too unlikely to be a chance occurrence. Any family of similar sequences across many organisms must have evolved from a common sequence in a remote ancestor.
Hands On: Dowloading
- Click on Descriptions tab
- Click at any sequence hit
- Click on Download
- Select
FASTA (aligned sequences)
It will download a new, slightly different, type of file: an aligned FASTA. If you want, explore it before the next section.
While in the previous sections of this tutorial we extensively used the web interfaces of the tools (genomic viewers, quick literature scanning, reading annotations, etc.), this BLAST search is an example of a step that you could fully automate with Galaxy.
Hands On: Similarity search with BLAST in Galaxy
Create a new history for this analysis
To create a new history simply click the new-history icon at the top of the history panel:
Rename the history
- Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
- Type the new name
- Click on Save
- To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
- Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
- Type the new name
- Press Enter
Import the protein sequence via link from Zenodo or Galaxy shared data libraries:
https://zenodo.org/record/8304465/files/protein.faa
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
As an alternative to uploading the data from a URL or your computer, the files may also have been made available from a shared data library:
- Go into Libraries (left panel)
- Navigate to the correct folder as indicated by your instructor.
- On most Galaxies tutorial data will be provided in a folder named GTN - Material –> Topic Name -> Tutorial Name.
- Select the desired files
- Click on Add to History galaxy-dropdown near the top and select as Datasets from the dropdown menu
In the pop-up window, choose
- “Select history”: the history you want to import the data to (or create a new one)
- Click on Import
NCBI BLAST+ blastp ( Galaxy version 2.10.1+galaxy2) with the following parameters:
- “Protein query sequence(s)”:
protein.faa- “Subject database/sequences”:
Locally installed BLAST database“Protein BLAST database”:
SwissProtTo search against only annotated sequences in UniProt, we need select the latest release of
SwissProt- “Set expectation value cutoff”:
0.001- “Output format”:
Tabular (extended 25 columns)


QuestionDo you think we are looking at exactly the same results as our original search for
opsinin www.ncbi.nlm.nih.gov/genome/gdv? Why?The results might be similar, but there are definitely some differences. Indeed, not only a text search is different than a sequence search in terms of method, but also this second round we started from the sequence of one specific opsin, so one branch of the entire protein family tree. Some of the family members are more similar between each other, so this type of search looks at the whole family from a quite biased perspective.
More information about our protein
So far, we explored this information about opsins:
- how to know which proteins of a certain type exist in a genome,
- how to know where they are along the genome,
- how to get more information about a gene of interest,
- how to download their sequences in different formats,
- how to use these files to perform a similarity search.
You might be curious about how to know more about the proteins they code for, now. We have already collected some information (e.g. diseases associated), but in the next steps we will cross it with data about the protein structure, localisation, interactors, functions, etc.
The portal to visit to obtain all information about a protein is UniProt. We can search it using a text search, or the gene or protein name. Let’s go for our usual OPN1LW keyword.
Hands On: Searching on UniProt
- Open UniProt
- Type
OPN1LWin the search bar- Select the card view
The first hit should be P04000 · OPSR_HUMAN. Before opening the page, two things to notice:
- The name of the protein
OPSR_HUMANis different than the gene name, as well as their IDs are. - This entry has a golden star, which means that was manually annotated and curated.
Hands On: Open a result on UniProt
- Click on
P04000 · OPSR_HUMAN
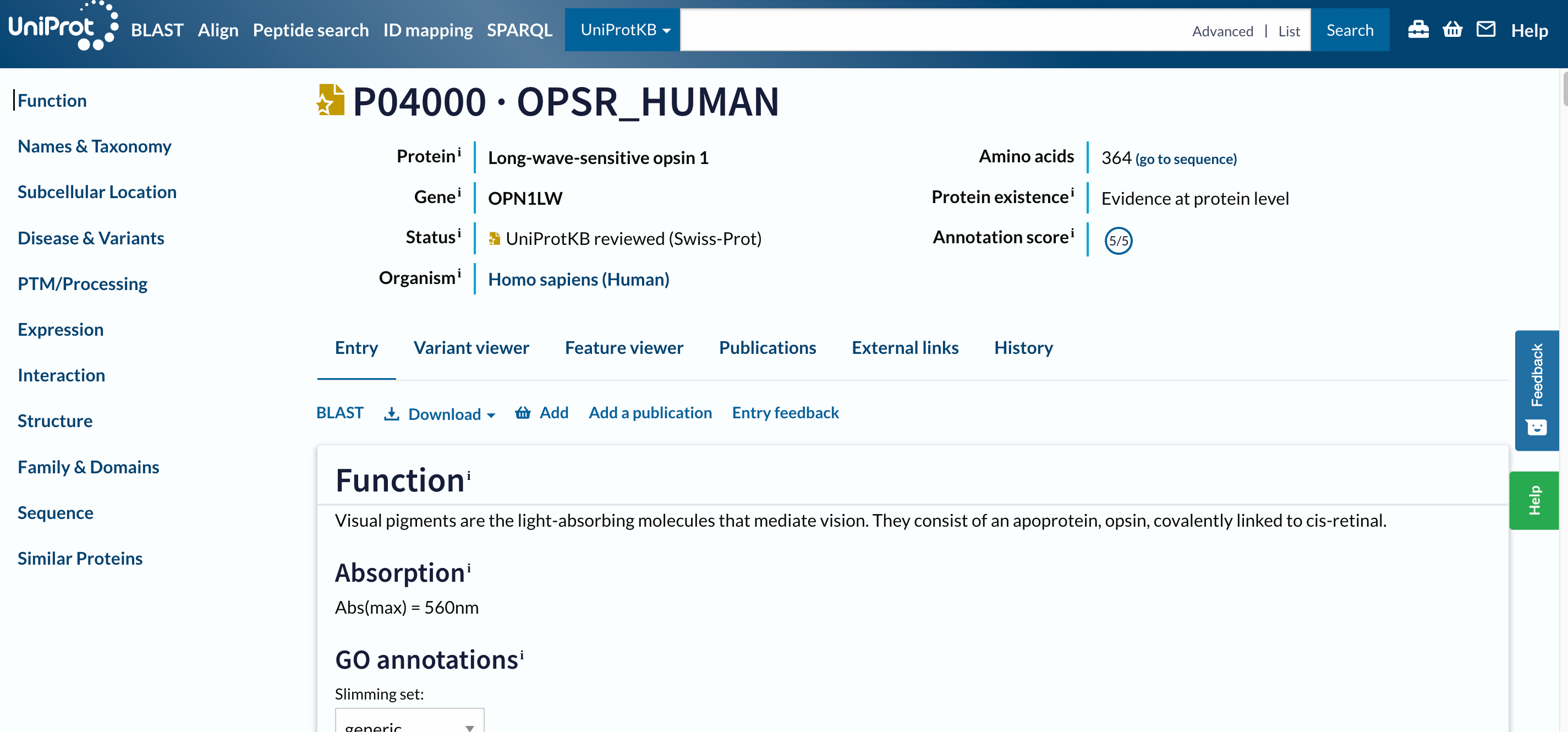 Open image in new tab
Open image in new tabThis is a long page with a lot of information, we designed an entire tutorial to go through it.
You've finished the tutorial
Key points
You can search for genes and proteins using specific text on the NCBI genome.
Once you find a relevant gene or protein, you can obtain its sequence and annotation in various formats from NCBI.
You can also learn about the chromosome location and the exon-intron composition of the gene of interest.
NCBI offers a BLAST tool to perform similarity searches with sequences.
You can further explore the resources included in this tutorial to learn more about the gene-associated conditions and the variants.
You can input a FASTA file containing a sequence of interest for BLAST searches.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsReferences
- Rangwala, S. H., A. Kuznetsov, V. Ananiev, A. Asztalos, E. Borodin et al., 2021 Accessing NCBI data using the NCBI sequence viewer and genome data viewer (GDV). Genome research 31: 159–169. 10.1101/gr.266932.120
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Lisanna Paladin, Bérénice Batut, Teresa Müller, Learning about one gene across biological resources and formats (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-gene/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{data-science-online-resources-gene, author = "Lisanna Paladin and Bérénice Batut and Teresa Müller", title = "Learning about one gene across biological resources and formats (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-gene/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
References
These individuals or organisations provided funding support for the development of this resource
Congratulations on successfully completing this tutorial!You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/data-science/tutorials/online-resources-gene/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: ncbi_blast_plus owner: devteam revisions: 0e3cf9594bb7 tool_panel_section_label: NCBI Blast tool_shed_url: https://toolshed.g2.bx.psu.edu/