Note: We recommend running this tutorial on either the Galaxy Europe or Galaxy Australia servers. Other servers (such as Galaxy main) have not yet been configured fully for all the tools in this analysis.
What is genome assembly?
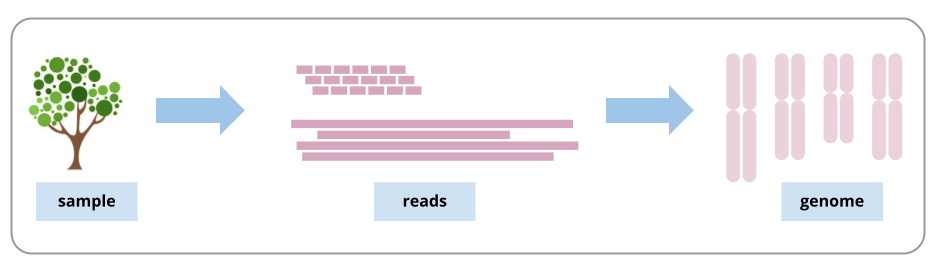
A genome is a representation of the set of DNA in an organism, such as the set of chromosomes. When the DNA is extracted from the sample, it is broken up into fragments much smaller than the lengths of DNA in the chromosomes. After being sequenced, these fragments (and their copies) are called sequencing reads. To assemble the genome, we need to join the reads back into, ideally, chromosome-sized lengths.
Assembly challenges
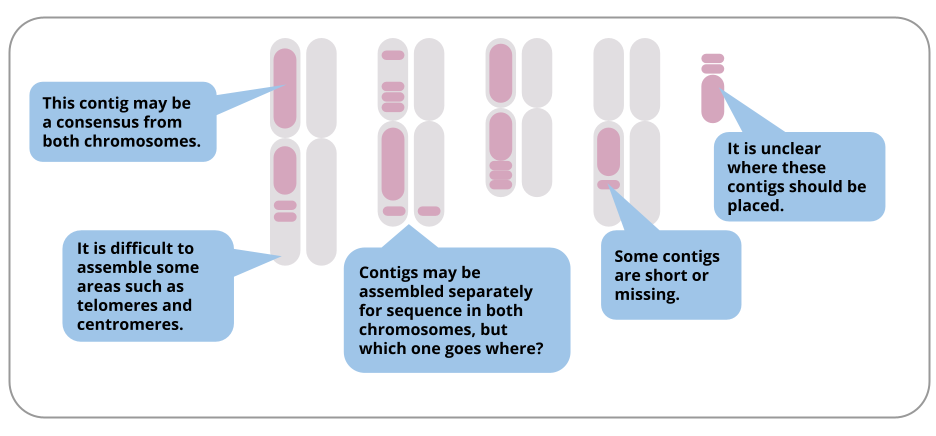
In reality, we rarely get chromosome-length assemblies, due to many challenges. Here are some examples of particular challenges in a diploid genome assembly:
Even though most assemblies are not chromosome-length, the assembly in contigs is still valuable for many research questions. Lengths of assembled contigs are increasing as sequencing technology and assembly tools improve.
Can I use my own data with these workflows?
This tutorial has been tested on real-sized data sets and should work with your own data. However, there will most likely be some modifications required to tools and settings. Furthermore, as most species have never had their genome sequenced, it is not possible to guarantee existing workflows are optimal for new data.
It is most likely that any new genome assembly will have its own set of required workflow and analysis customisations to account for things such as ploidy and repeats. Usually, an assembly workflow will need testing and customising, in concert with reading the biological domain literature.
Before using these workflows on real datasets, we recommend completing all the relevant GTN tutorials about Data QC and Asssembly to give extra familiarity with the concepts. Then, we suggest creating subsampled data sets from your full-sized data, for testing. For best results, it is recommended to test each tool separately, and consider the parameters and their relevance and suitability for your own research questions.
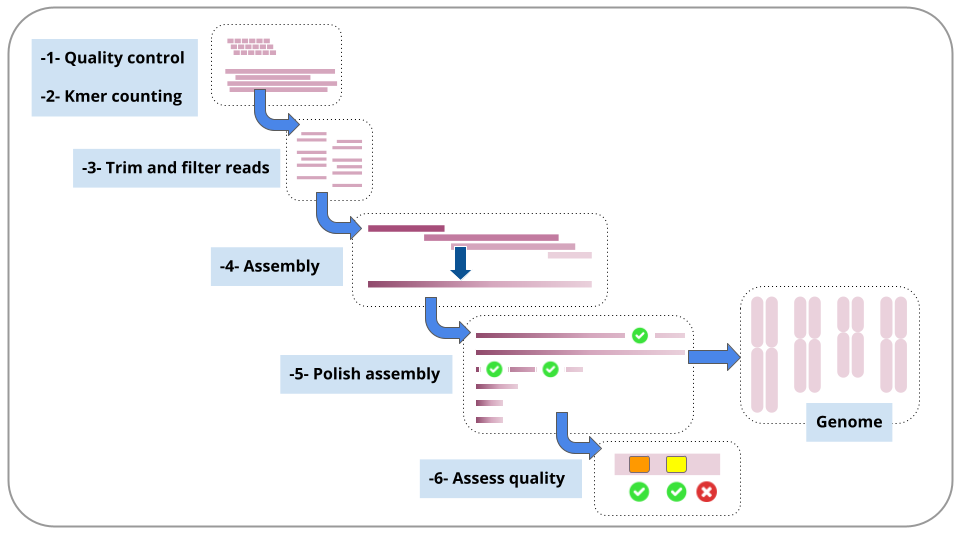
Each of these steps is described in a section in this tutorial.
For each step, we will run a workflow.
We will stay in the same Galaxy history throughout.
How to run a workflow in Galaxy
All of these workflows have been uploaded to workflowhub.eu and have been tagged with “Large-genome-assembly”. There, each workflow is accompanied by an image of the workflow canvas and the tool connections.
The workflows are also linked to this tutorial - see above and import them into your own Galaxy Account.
If you are using Galaxy Australia, the workflows are published with the tag “lg-wf”.
A note: as of September 2022, these workflows have been tested on Galaxy Australia and we are now in the process of testing them on Galaxy Europe and Galaxy Main.
Here is a list of the workflows:
Tutorial section
Workflow name
Quality Control
Data QC
Kmer counting
kmer counting - meryl
Trim and filter reads
Trim and filter reads - fastp
Assembly
Assembly with Flye
Polish assembly
Assembly polishing
Assess quality
Assess genome quality
WorkflowHub is a workflow management system which allows workflows to be FAIR (Findable, Accessible, Interoperable, and Reusable), citable, have managed metadata profiles, and be openly available for review and analytics.
Click on galaxy-workflows-activityWorkflows in the Galaxy activity bar (on the left side of the screen, or in the top menu bar of older Galaxy instances). You will see a list of all your workflows
Click on galaxy-uploadImport at the top-right of the screen
On the new page, select the GA4GH servers tab, and configure the GA4GH Tool Registry Server (TRS) Workflow Search interface as follows:
“TRS Server”: workflowhub.eu
“search query”: "large genome assembly"
Expand the correct workflow by clicking on it
Select the version you would like to galaxy-upload import
The workflow will be imported to your list of workflows. Note that it will also carry a little blue-white shield icon next to its name, which indicates that this is an original workflow version imported from a TRS server. If you ever modify the workflow with Galaxy’s workflow editor, it will lose this indicator.
Below is a short video showing the entire uncomplicated procedure:
Video: Importing via search from WorkflowHub
After importing the workflows into your account:
Look at your of Workflows. (Galaxy top panel: Workflow)
For the workflow you want to run, go to the right hand side and see the arrow button (a triangle), click
This brings up the workflow in the centre Galaxy panel
Click “Expand to full workflow form”
For “Send results to a new history”, leave it as “No”.
Each time you run a workflow, you need to specify the input data set (or sets). Galaxy will try to guess which file this is, but change if required using the drop-down arrow.
At the top right, click “Run Workflow”.
The result files will appear at the top of your current history
Each workflow will be discussed in a separate section.
Upload data
Let’s start with uploading the data.
What sequence data are we using in the tutorial?
The data sets for genome projects can be very large and tools can take some time to run. It is a good idea to test that your planned tools and workflows will work on smaller-sized test data sets, as it is much quicker to find out about any problems.
In this tutorial we will use a subset of real sequencing data from a plant genome, the snow gum, Eucalyptus pauciflora, from a genome project described in this paper: Wang et al. 2020. Data is hosted at NCBI BioProject number: PRJNA450887.
How has this data subset been prepared?
From NCBI, three read files were imported into Galaxy for this tutorial: nanopore reads (SRR7153076), and paired Illumina reads (SRR7153045).
These were randomly subsampled to 10% of the original file size.
Plant genomes may contain an excess of reads from the chloroplast genome (of which there are many copies per cell). To ensure our test data sets are not swamped from excessive chloroplast-genome reads, reads that mapped to a set of known chloroplast gene sequences were discarded.
We are also using a reference genome Arabidopsis thaliana for a later comparison step - file TAIR10_chr_all.fas downloaded from The Arabidopsis Information Resource.
Import the data
Hands On: Import the data
Create a new history for this tutorial and give it a proper name
To create a new history simply click the new-history icon at the top of the history panel:
Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
Type the new name
Click on Save
To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
Type the new name
Press Enter
Import from Zenodo or a data library (ask your instructor):
2 FASTQ files with illumina reads: these files have a R1 or R2 in the name
1 FASTQ file with nanopore reads: this file has nano in the name
Click galaxy-uploadUpload at the top of the activity panel
Select galaxy-wf-editPaste/Fetch Data
Paste the link(s) into the text field
Press Start
Close the window
As an alternative to uploading the data from a URL or your computer, the files may also have been made available from a shared data library:
Go into Libraries (left panel)
Navigate to the correct folder as indicated by your instructor.
On most Galaxies tutorial data will be provided in a folder named GTN - Material –> Topic Name -> Tutorial Name.
Select the desired files
Click on Add to Historygalaxy-dropdown near the top and select as Datasets from the dropdown menu
In the pop-up window, choose
“Select history”: the history you want to import the data to (or create a new one)
Click on Import
Check that the datatypes for the three files of sequencing reads are fastq.gz, not fastqsanger.gz and change datatype if needed.
Click on the galaxy-pencilpencil icon for the dataset to edit its attributes
In the central panel, click galaxy-chart-select-dataDatatypes tab on the top
In the galaxy-chart-select-dataAssign Datatype, select datatypes from “New Type” dropdown
Tip: you can start typing the datatype into the field to filter the dropdown menu
Click the Save button
This tutorial uses these input files and gives some examples from the results.
It is likely that your results will differ slightly (e.g. number of bases in the genome assembly). This is common, because many tools start from different random seeds.
Also, tool versions are being constantly updated. Newer versions may be available since this tutorial was written and could give slightly different results.
Check read quality
Let’s look at how many reads we have and their quality scores using the Data QC workflow.
Data QC workflow
What it does: Reports statistics from sequencing reads
Inputs:
long reads (fastq.gz format)
short reads (R1 and R2) (fastq.gz format)
Outputs:
For long reads: a nanoplot report (the HTML report summarizes all the information).
For short reads: a MultiQC report
Tools used:
Nanoplot
FastQC
MultiQC
Workflow steps:
Long reads are analysed by Nanoplot.
Short reads (R1 and R2) are analysed by FastQC
the resulting reports are processed by MultiQC
Options:
See the tool settings options at runtime and change as required.
Click on galaxy-workflows-activityWorkflows in the Galaxy activity bar (on the left side of the screen, or in the top menu bar of older Galaxy instances). You will see a list of all your workflows
Click on galaxy-uploadImport at the top-right of the screen
Paste the following URL into the box labelled “Archived Workflow URL”: https://training.galaxyproject.org/training-material/topics/assembly/tutorials/largegenome/workflows/Galaxy-Workflow-Data_QC.ga
Click the Import workflow button
Below is a short video demonstrating how to import a workflow from GitHub using this procedure:
Video: Importing a workflow from URL
Click “Expand to full workflow form”
Run Data QCworkflow using the following parameters:
“Send results to a new history”: No
param-file“1: Input file: long reads”: the nanopore fastq.gz file
Click on Workflows on the Activity Bar on the left.
At the top of the resulting page you will have the option to switch between the My workflows, Workflows shared with me and Public workflows tabs.
Select the tab you want to see all workflows in that category
Search for your desired workflow.
Click on the workflow name: a pop-up window opens with a preview of the workflow.
To run it directly: click Run (top-right).
Recommended: click Import (left of Run) to make your own local copy under Workflows / My Workflows.
Data QC results
Question
What are the results from the two output files? Are the reads long enough and of high enough quality for our downstream analyses? Will reads need any trimming or filtering?
Common things to check are average read length, average quality, and whether quality varies by position in the reads.
Look at the plot for MultiQC for the Sequence Quality Histograms. This shows how the read quality of Illumina reads (y axis) varies according to base position (x axis).You may see for Illumina reads that there is some drop-off in quality towards the end of the reads, which may benefit from trimming.
Look at the plot from Nanoplot for “Read lengths vs Average read quality”. The nanopore reads have a mean read quality of 9.0. Depending on the size of our input read sets and the research question, we may filter out reads below a certain average quality. If we had a lot of reads, we may be able to set a higher threshold for filtering according to read quality.
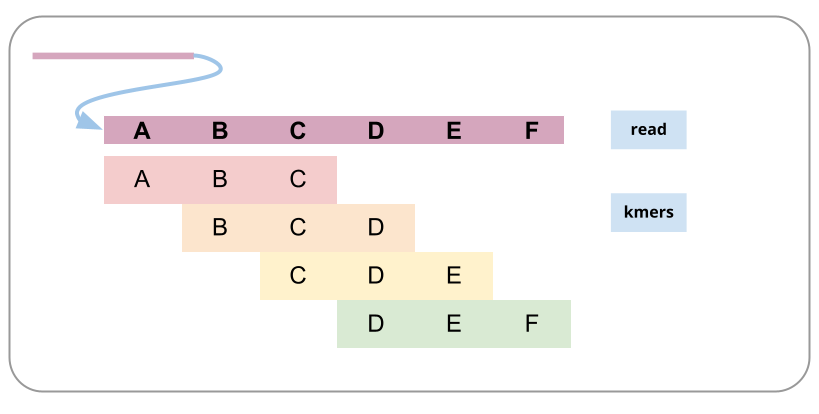
To prepare for genome assembly you might want to know things about your genome such as size, ploidy level (how many sets of chromosomes) and heterozygosity (how variable the sequence is between homologous chromosomes). A relatively fast way to estimate these things is to count small fragments of the sequencing reads (called kmers).
A read broken into kmers:
Comment: What is kmer counting?
Kmer counting is usually done with high-accuracy short reads, not long reads which may have high error rates. After counting how many times each kmer is seen in the reads, we can see what sorts of counts are common. For example, lots of kmers may have been found 24 or 25 times. A graph shows the number of different kmers (y axis) found at different counts, or depths (x axis).
Many different kmers will be found the same number of times; e.g. X25. If kmer length approaches read length, this means the average depth of your sequencing is also ~X25, and there would be a peak in the graph at this position (smaller kmers = higher kmer depth). There may be smaller peaks of kmer counts at higher depths, e.g. X50 or X100, indicating repeats in the genome. There may be other smaller peaks of kmers found at half the average depth, indicating a diploid genome with a certain amount of difference between the homologous chromosomes - this is known as heterozygosity. Thus, the plot of how many different kmers are found at all the depths will help inform estimates of sequencing depth, ploidy level, heterozygosity, and genome size.
Kmer counting workflow
What it does: Estimates genome size and heterozygosity based on counts of kmers
Inputs: One set of short reads: e.g. R1.fq.gz
Outputs: GenomeScope graphs
Tools used:
Meryl
GenomeScope
Workflow steps:
The tool meryl counts kmers in the input reads (k=21), then converts this into a histogram.
GenomeScope: runs a model on the histogram; reports estimates. k-mer size set to 21.
Options:
Use a different kmer counting tool. e.g. khmer. If so, for the settings, advanced parameters:
Click on galaxy-workflows-activityWorkflows in the Galaxy activity bar (on the left side of the screen, or in the top menu bar of older Galaxy instances). You will see a list of all your workflows
Click on galaxy-uploadImport at the top-right of the screen
Paste the following URL into the box labelled “Archived Workflow URL”: https://training.galaxyproject.org/training-material/topics/assembly/tutorials/largegenome/workflows/Galaxy-Workflow-kmer_counting.ga
Click the Import workflow button
Below is a short video demonstrating how to import a workflow from GitHub using this procedure:
Video: Importing a workflow from URL
Click “Expand to full workflow form”
Run Kmer countingworkflow using the following parameters:
Click on Workflows on the Activity Bar on the left.
At the top of the resulting page you will have the option to switch between the My workflows, Workflows shared with me and Public workflows tabs.
Select the tab you want to see all workflows in that category
Search for your desired workflow.
Click on the workflow name: a pop-up window opens with a preview of the workflow.
To run it directly: click Run (top-right).
Recommended: click Import (left of Run) to make your own local copy under Workflows / My Workflows.
Kmer counting results
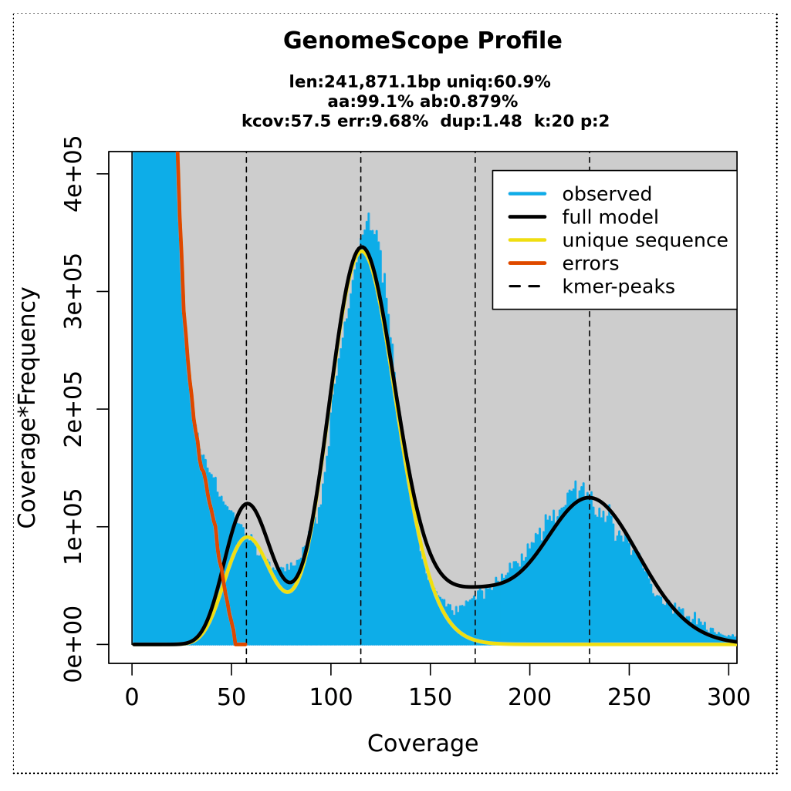
GenomeScope transformed linear plot:
Here we can see a central peak - showing that most of the different kmers were found at counts of ~ 120. These are kmers from single-copy homozygous alleles. To the left, a smaller peak at around half the coverage, showing kmers from heterozygous alleles (note that this peak gets higher than the main peak when heterozygosity is only ~ 1.2%). To the right, another smaller peak showing kmers at higher coverage, from repeat regions. Information from these three peaks provide a haploid genome length estimate of ~240,000 bp (note this is test data so smaller than whole plant genome size).
The output Summary file shows more detail:
Genome unique length: from single copy homozygous and heterozygous alleles (under the main and left peak).
Genome repeat length: from repeat copies (under the graph to the right of the main peak).
For more about Genomescope see Vurture et al. 2017(Note: the supplementary information is very informative).
Trim and filter reads
Using information from Data QC and kmer counting, we may want to trim and/or filter reads. The settings for trimming and filtering depend on many things, including:
your aim (accuracy; contiguity)
your data: type, error rate, read depth, lengths, quality (average, variation by position)
the ploidy and heterozygosity of your sample
choice of assembly tool (e.g. it may automatically deal with adapters, low qualities, etc.)
Because of all these factors, few specific recommendations are made here, but the workflow is provided and can be customised. If you are unsure how to start, use your test data to try different settings and see the effect on the resulting size and quality of the reads, and the downstream assembly contigs. Newer assemblers are often configured to work well with long-read data and in some cases, read trimming/filtering for long reads may be unnecessary.
Trimming and filtering reads:
Trimming and filtering workflow
What it does: Trims and filters raw sequence reads according to specified settings.
Inputs:
Long reads (format fastq)
Short reads R1 and R2 (format fastq)
Outputs: Trimmed and filtered reads:
fastp_filtered_long_reads.fastq.gz (But note: no trimming or filtering is on by default)
fastp_filtered_R1.fastq.gz
fastp_filtered_R2.fastq.gz
Tools used: fastp (Note. The latest version (0.20.1) of fastp has an issue displaying plot results. Using version 0.19.5 here instead until this is rectified).
Input parameters: None required, but recommend removing the long reads from the workflow if not using any trimming/filtering settings.
Workflow parameter settings:
Long reads: fastp settings:
These settings have been changed from the defaults (so that all filtering and trimming settings are now disabled).
adapter trimming (default setting: adapters are auto-detected)
quality filtering (default: phred quality 15), unqualified bases limit (default = 40%), number of Ns allowed in a read (default = 5)
length filtering (default length = min 15)
polyG tail trimming (default = on for NextSeq/NovaSeq data which is auto detected)
Output options: output JSON report: yes
Options:
Change any settings in fastp for any of the input reads.
Adapter trimming: input the actual adapter sequences. (Alternative tool for long read adapter trimming: Porechop.)
Trimming n bases from ends of reads if quality less than value x (Alternative tool for trimming long reads: NanoFilt.)
Discard post-trimmed reads if length is < x (e.g. for long reads, 1000 bp)
Example filtering/trimming that you might do on long reads: remove adapters (can also be done with Porechop), trim bases from ends of the reads with low quality (can also be done with NanoFilt), after this can keep only reads of length x (e.g. 1000 bp)
If not running any trimming/filtering on nanopore reads, could delete this step from the workflow entirely.
Click on galaxy-workflows-activityWorkflows in the Galaxy activity bar (on the left side of the screen, or in the top menu bar of older Galaxy instances). You will see a list of all your workflows
Click on galaxy-uploadImport at the top-right of the screen
Paste the following URL into the box labelled “Archived Workflow URL”: https://training.galaxyproject.org/training-material/topics/assembly/tutorials/largegenome/workflows/Galaxy-Workflow-Trim_and_filter_reads.ga
Click the Import workflow button
Below is a short video demonstrating how to import a workflow from GitHub using this procedure:
Video: Importing a workflow from URL
Click “Expand to full workflow form”
Run Trim and Filter Readsworkflow using the following parameters:
“Send results to a new history”: No
param-file“1: Input file: long reads”: the nanopore fastq.gz file
Note: the workflow parameter settings described above are already set, and don’t need to be changed when running the workflow, unless you wish to.
Click on Workflows on the Activity Bar on the left.
At the top of the resulting page you will have the option to switch between the My workflows, Workflows shared with me and Public workflows tabs.
Select the tab you want to see all workflows in that category
Search for your desired workflow.
Click on the workflow name: a pop-up window opens with a preview of the workflow.
To run it directly: click Run (top-right).
Recommended: click Import (left of Run) to make your own local copy under Workflows / My Workflows.
Trim and filter reads: results
There are two fastp reports - one for the illumina reads and one for the nanopore reads. We have only processed illumina reads in this example. Look at the fastp illumina report. (Note: the title in the report refers to only one of the input read sets but the report is for both read sets. This is a known issue under investigation.)
Filtering results from fastp on short reads:
Here we can see that less than 0.5 % of the reads were discarded based on quality. If our read set had high enough coverage for downstream analyses, we might choose to apply a stricter quality filter.
Summary of read data for genome assembly
Question
How many reads do we have now for our genome assembly? Is the read coverage high enough?
Genome size: From kmer counting, the estimated genome size is ~ 240,000 bp (this is only subsampled data; full data would likely suggest a size of 0.5 - 1 Gbp for a typical plant genome)
Genome coverage (or depth): total base pairs in the reads / base pairs in genome
Short reads: From the fastp report after trimming and filtering short reads, there are 3.2 million reads, comprising 482 million base pairs
Short read coverage: = X2008
Long reads: From the fastp report of the long reads (although no filtering and trimming performed) there are 85 thousand reads, comprising 761 million base pairs. From the nanoplot tool we ran in the Data QC section , we know that the mean read length is almost 9,000 base pairs, and the longest read is > 140,000 base pairs.
Long read coverage: = X3170
These coverages are very high but are ok to use with tutorial data. With a typical full data set, coverage would be more in the order of X40 to X200.
Genome Assembly
Genome assembly means joining the reads up to make contiguous sections of the genome. A simplified way to imagine this is overlapping all the different sequencing reads to make a single length or contig, ideally one for each original chromosome. The output is a set of contigs and a graph showing how contigs are connected.
Extreme simplification of genome assembly:
Genome assembly algorithms use different approaches to work with the complexities of large sequencing read data sets, large genomes, different sequencing error rates, and computational resources. Many use graph-based algorithms. For more about genome assembly algorithms see these tutorials by Ben Langmead.
Which assembly tool and approach to use?
Here, we will use the assembly tool called Flye to assemble the long reads. This is fast and deals well with the high error rate. Then, we will polish (correct) the assembly using information from the long reads (in their unassembled state), as well as the more accurate short Illumina reads.
There are many other approaches and combinations of using short and long reads, and the polishing steps. For example, the long reads can be polished before assembly (with themselves, or with short reads). This may increase accuracy of the assembly, but it may also introduce errors if similar sequences are “corrected” into an artificial consensus. Long reads are usually used in the assembly, but it is possible to assemble short reads and then scaffold these into longer contigs using information from long reads.
What it does: Assembles long reads with the tool Flye
Inputs: long reads (may be raw, or filtered, and/or corrected); fastq.gz format
Outputs:
Flye assembly fasta.
Fasta stats on assembly.fasta
Assembly graph image from Bandage
Bar chart of contig sizes
Quast reports of genome assembly
Tools used:
Flye
Fasta statistics
Bandage
Bar chart
Quast
Input parameters: None required, but recommend setting assembly mode to match input sequence type
Workflow steps:
Long reads are assembled with Flye, using default tool settings. Note: the default setting for read type (“mode”) is nanopore raw. Change this at runtime if required.
Statistics are computed from the assembly.fasta file output, using Fasta Statistics and Quast (is genome large: Yes; distinguish contigs with more that 50% unaligned bases: no)
The graphical fragment assembly file is visualized with the tool Bandage.
Assembly information sent to bar chart to visualize contig sizes
Options
See other Flye options.
Use a different assembler (in a different workflow).
Bandage image options - change size (max size is 32767), labels - add (e.g. node lengths). You can also install Bandage on your own computer and download the “graphical fragment assembly” file to view in greater detail.
Click on galaxy-workflows-activityWorkflows in the Galaxy activity bar (on the left side of the screen, or in the top menu bar of older Galaxy instances). You will see a list of all your workflows
Click on galaxy-uploadImport at the top-right of the screen
Paste the following URL into the box labelled “Archived Workflow URL”: https://training.galaxyproject.org/training-material/topics/assembly/tutorials/largegenome/workflows/Galaxy-Workflow-Assembly_with_Flye.ga
Click the Import workflow button
Below is a short video demonstrating how to import a workflow from GitHub using this procedure:
Video: Importing a workflow from URL
Click “Expand to full workflow form”
Run Assembly with Flyeworkflow using the following parameters:
“Send results to a new history”: No
param-file“1: Input file: long reads”: the fastp filtered long reads fastq.gz file
Click on Workflows on the Activity Bar on the left.
At the top of the resulting page you will have the option to switch between the My workflows, Workflows shared with me and Public workflows tabs.
Select the tab you want to see all workflows in that category
Search for your desired workflow.
Click on the workflow name: a pop-up window opens with a preview of the workflow.
To run it directly: click Run (top-right).
Recommended: click Import (left of Run) to make your own local copy under Workflows / My Workflows.
Assembly results
The assembled contigs are in the “Flye assembly on data X (consensus)” (X is a number that will vary depending on where it sits in your history).
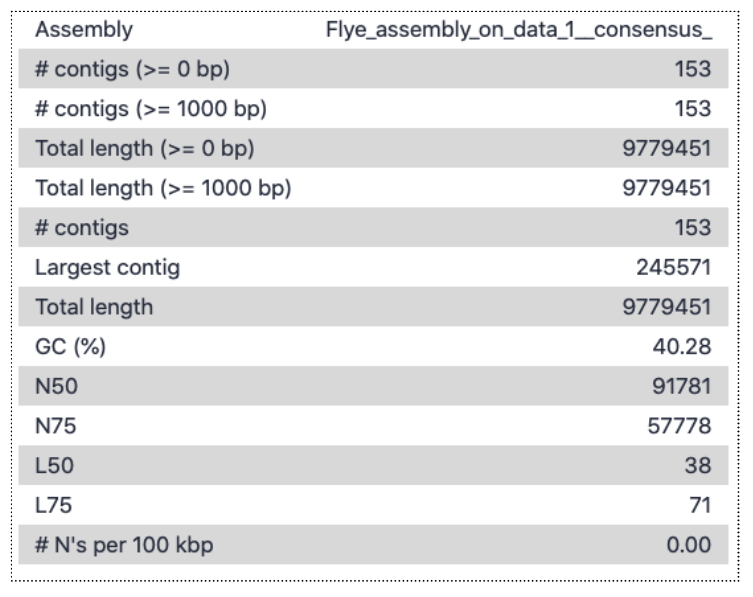
Open the Quast tabular report to see the assembly statistics:
There are 153 contigs, largest is ~246,000 bp, and total length almost 10 million bp. This is a fair bit longer than the estimated genome size from kmer counting (which was ~240,000 bp), but the difference is likely mainly due to idiosyncrasies of using a subsampled data set. The read coverage was likely <1, causing many kmers to have frequency of <1 and be classed as errors, rather than contributing to the genome size estimate.
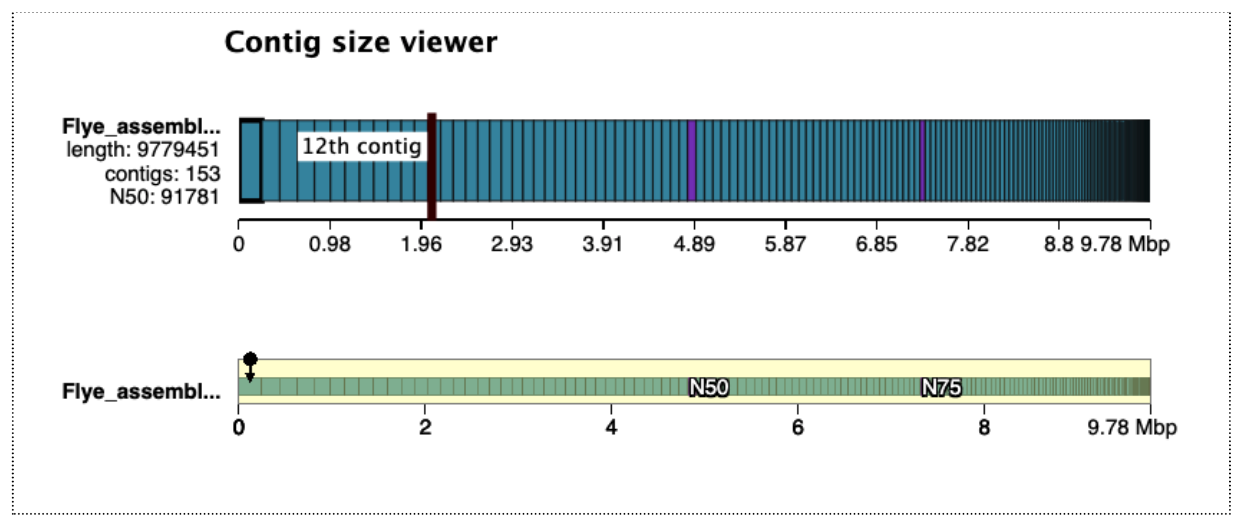
Open the Quast HTML report, then click on “View in Icarus contig browser”. This is a way to visualize the contigs and their sizes:
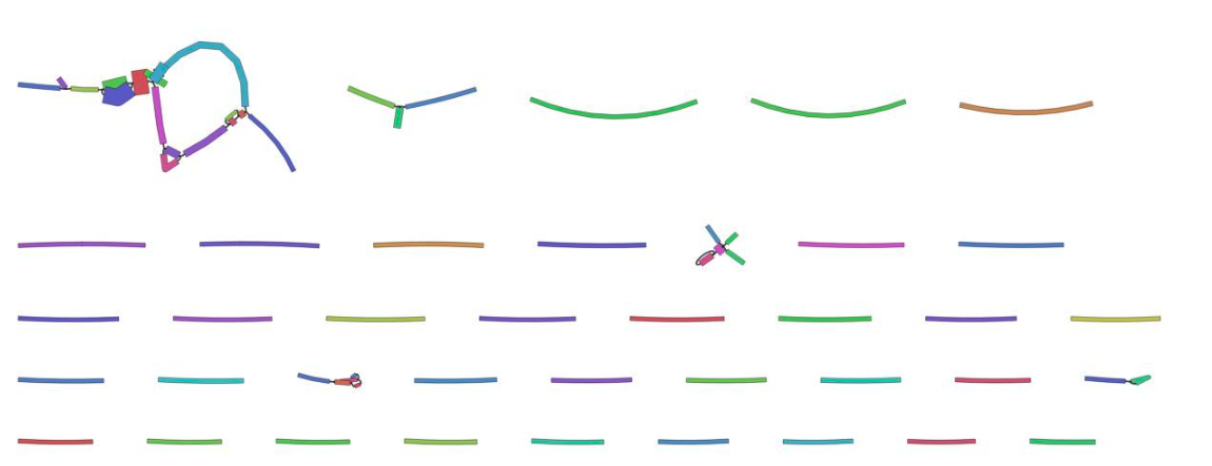
View the Bandage image of the assembly graph:
As this is a subsampled data set, it is not surprising that most of the contigs are unjoined. The joined contigs at the top left are likely to be part of the mitochondrial genome as these reads were probably over-represented in our subsampled data set.
What about centromeres and telomeres?
Some genomic areas such as centromeres, telomeres, and ribosomal DNA arrays, are much harder to assemble. These are long stretches of very similar repeats. With improved sequencing accuracy, length, and technologies (particularly long-range scaffolding), these may soon be much easier to assemble. The latest human genome assembly has a good demonstration of the techniques used for this. See Nurk et al. 2021, and in particular, Figure 2: Bandage graphs of the human genome chromosomes, with the grey shading showing centromeric regions.
What about haplotigs?
Although our sample may be diploid, with pairs of chromosomes, the resulting assembly is often a haploid (or “collapsed”) assembly. This is not the sequence of one of the chromosomes, but a mix of the two.
Some assemblers will produce extra contigs called haplotigs. These are parts of the assembly from heterozygous regions (that is, the sequence is relatively different between the chromosome pair). There are tools to remove haplotigs from the assembly if that is preferred.
For more on differences between collapsed, primary/alternate and partially-phased assemblies, with a great visual representation: see Heng Li’s Github page
For more on the phased assemblies, particularly for diploids or polyploids, see Garg 2021.
Assembly polishing
We will polish the assembly using both the long reads and short reads. This process aligns the reads to the assembly contigs, and makes corrections to the contigs where warranted. For more, see Aury and Istace 2021, particularly for a discussion about polishing diploid genomes.
Assembly polishing:
Polishing workflow
Workflow structure: The workflow includes two subworkflows:
Racon polish with long reads, x 4
Racon polish with illumina reads, x2
What it does: Polishes (corrects) an assembly, using long reads (with the tools Racon and Medaka) and short reads (with the tool Racon). (Note: medaka is only for nanopore reads, not PacBio reads).
Inputs:
assembly to be polished: assembly.fasta
long reads - the same set used in the assembly (e.g. may be raw or filtered) fastq.gz format
short reads, R1 only, in fastq.gz format
Outputs:
Racon+Medaka+Racon polished_assembly. fasta
Fasta statistics after each polishing tool
Tools used:
Minimap2
Racon
Fasta statistics
Medaka
Input parameters: None required, but recommended to set the Medaka model correctly (default = r941_min_high_g360). See drop down list for options.
Workflow steps for Part 1, Polish with long reads: using Racon
Long reads and assembly contigs => Racon polishing (subworkflow):
minimap2 : long reads are mapped to assembly => overlaps.paf.
overaps, long reads, assembly => Racon => polished assembly 1
using polished assembly 1 as input; repeat minimap2 + racon => polished assembly 2
using polished assembly 2 as input, repeat minimap2 + racon => polished assembly 3
using polished assembly 3 as input, repeat minimap2 + racon => polished assembly 4
Racon long-read polished assembly => Fasta statistics
Note: The Racon tool panel can be a bit confusing and is under review for improvement. Presently it requires sequences (= long reads), overlaps (= the paf file created by minimap2), and target sequences (= the contigs to be polished) as per “usage” described at this link https://github.com/isovic/racon/blob/master/README.md
Note: Racon: the default setting for “output unpolished target sequences?” is No. This has been changed to Yes for all Racon steps in these polishing workflows. This means that even if no polishes are made in some contigs, they will be part of the output fasta file.
Note: the contigs output by Racon have new tags in their headers. For more on this see this issue.
Workflow steps for Part 2, Polish with long reads: using Medaka
using polished assembly 1 as input; repeat minimap2 + racon => polished assembly 2
Racon short-read polished assembly => Fasta statistics
Options:
Change settings for Racon long read polishing if using PacBio reads: The default profile setting for Racon long read polishing: minimap2 read mapping is “Oxford Nanopore read to reference mapping”, which is specified as an input parameter to the whole Assembly polishing workflow, as text: map-ont. If you are not using nanopore reads and/or need a different setting, change this input. To see the other available settings, open the minimap2 tool, find “Select a profile of preset options”, and click on the drop down menu. For each described option, there is a short text in brackets at the end (e.g. map-pb). This is the text to enter into the assembly polishing workflow at runtime instead of the default (map-ont).
Other options: change the number of polishes (in Racon and/or Medaka). There are ways to assess how much improvement in assembly quality has occurred per polishing round (for example, the number of corrections made; the change in Busco score - see section “Genome quality assessment” for more on Busco).
Option: change polishing settings for any of these tools. Note: for Racon - these will have to be changed within those subworkflows first. Then, in the main workflow, update the
Click on galaxy-workflows-activityWorkflows in the Galaxy activity bar (on the left side of the screen, or in the top menu bar of older Galaxy instances). You will see a list of all your workflows
Click on galaxy-uploadImport at the top-right of the screen
Paste the following URL into the box labelled “Archived Workflow URL”: https://training.galaxyproject.org/training-material/topics/assembly/tutorials/largegenome/workflows/Galaxy-Workflow-Assembly_polishing.ga
Click the Import workflow button
Below is a short video demonstrating how to import a workflow from GitHub using this procedure:
Video: Importing a workflow from URL
Click “Expand to full workflow form”
Run Assembly polishingworkflow using the following parameters:
“Send results to a new history”: No
param-file“1: Assembly to be polished”: the assembly fasta file
param-file“2: long reads”: the nanopore reads, the same set that was used for the assembly
param-file“3: Illumina reads R1”: the illumina R1 fastq.gz file
No other settings need to be changed, as they are set as described above, but recommended to set the Medaka model correctly (default = r941_min_high_g360). See drop down list for options.
Click on Workflows on the Activity Bar on the left.
At the top of the resulting page you will have the option to switch between the My workflows, Workflows shared with me and Public workflows tabs.
Select the tab you want to see all workflows in that category
Search for your desired workflow.
Click on the workflow name: a pop-up window opens with a preview of the workflow.
To run it directly: click Run (top-right).
Recommended: click Import (left of Run) to make your own local copy under Workflows / My Workflows.
Polishing results
The polished assembly is the final Racon file.
Look at the Fasta Statistics output files for the status of the assemblies after each polishing tool. From these, we can see that some polishes decrease or increase the size of the assembly. The final size is approximately 300,000 bp shorter than the original Flye assembly. (These numbers may vary slightly even if the same input data is used).
Genome quality assessment
The polished genome is in 145 contigs with a total length of ~ 9.6 million base pairs. We have some idea of how these contigs may be joined (or not) from the Bandage assembly graph.
Question
How good is the assembly?
One measure is the N50, a number that indicates how large the contigs are (although, have the contigs been joined correctly)? Another measure is to see if expected gene sequences are found in the assembly, using a tool called BUSCO. For a discussion on these and other methods, see Wang et al. 2020.
Here, we will use the BUSCO tool to annotate the genome and then assess whether expected genes are found. Note: this is a brief annotation only, not the full genome annotation that would typically be done following genome assembly.
Assesses the quality of the genome assembly: generate some statistics and determine if expected genes are present
Align contigs to a reference genome.
Inputs:
polished assembly
reference_genome.fasta (e.g. of a closely-related species, if available).
Outputs
Busco table of genes found
Quast HTML report, and link to Icarus contigs browser, showing contigs aligned to a reference genome
Tools used:
Busco
Quast
Input parameters: None required
Workflow steps:
Polished assembly => Busco:
First: predict genes in the assembly: using Metaeuk
Second: compare the set of predicted genes to the set of expected genes in a particular lineage. Default setting for lineage: Eukaryota
Polished assembly and a reference genome => Quast:
For the tutorial we will use the Arabidopsis genome. This is not closely related to our Eucalyptus species but will give an idea of how to use Quast.
Contigs/scaffolds file: polished assembly
Type of assembly: Genome
Use a reference genome: Yes
Reference genome: Arabidopsis genome
Is the genome large (> 100Mbp)? Yes. (Our test data set won’t be, but this will still give us some results).
All other settings as defaults, except second last setting: Distinguish contigs with more than 50% unaligned bases as a separate group of contigs?: change to No
Options:
Gene prediction:
Change tool used by Busco to predict genes in the assembly: instead of Metaeuk, use Augustus (Metaeuk is meant to be faster; unsure which is better).
select: Use Augustus; Use another predefined species model; then choose from the drop down list.
Note: if using Augustus: it may fail if the input assembly is too small (e.g. a test-size data assembly). It can’t do the training part properly.
Compare genes found to other lineage:
Busco has databases of lineages and their expected genes. Option to change lineage. Not all lineages are available - there is a mix of broader and narrower lineages.
Click on galaxy-workflows-activityWorkflows in the Galaxy activity bar (on the left side of the screen, or in the top menu bar of older Galaxy instances). You will see a list of all your workflows
Click on galaxy-uploadImport at the top-right of the screen
Paste the following URL into the box labelled “Archived Workflow URL”: https://training.galaxyproject.org/training-material/topics/assembly/tutorials/largegenome/workflows/Galaxy-Workflow-Assess_genome_quality.ga
Click the Import workflow button
Below is a short video demonstrating how to import a workflow from GitHub using this procedure:
Video: Importing a workflow from URL
Click “Expand to full workflow form”
Run Assess Genome Qualityworkflow using the following parameters:
“Send results to a new history”: No
param-file“1: Input file: Polished assembly”: the polished assembly fasta file from the previous polishing workflow
Click on Workflows on the Activity Bar on the left.
At the top of the resulting page you will have the option to switch between the My workflows, Workflows shared with me and Public workflows tabs.
Select the tab you want to see all workflows in that category
Search for your desired workflow.
Click on the workflow name: a pop-up window opens with a preview of the workflow.
To run it directly: click Run (top-right).
Recommended: click Import (left of Run) to make your own local copy under Workflows / My Workflows.
Assessment results
The output is a set of Quast and Busco reports.
Busco: As this is a test dataset, the assembly is small (~ 10 million base pairs, rather than ~ 1 billion base pairs), and likely missing most of the real genome (and genes). Thus, for this test case, we would expect most of the genes not to be found, but we can view the Busco results to see an example of how it works. Open the Busco short summary file: only 1 complete BUSCO has been found, out of 255 expected. You can re-run the workflow and change the lineage to “Embryophyta” to see that more BUSCOs are found (8 out of 1614).
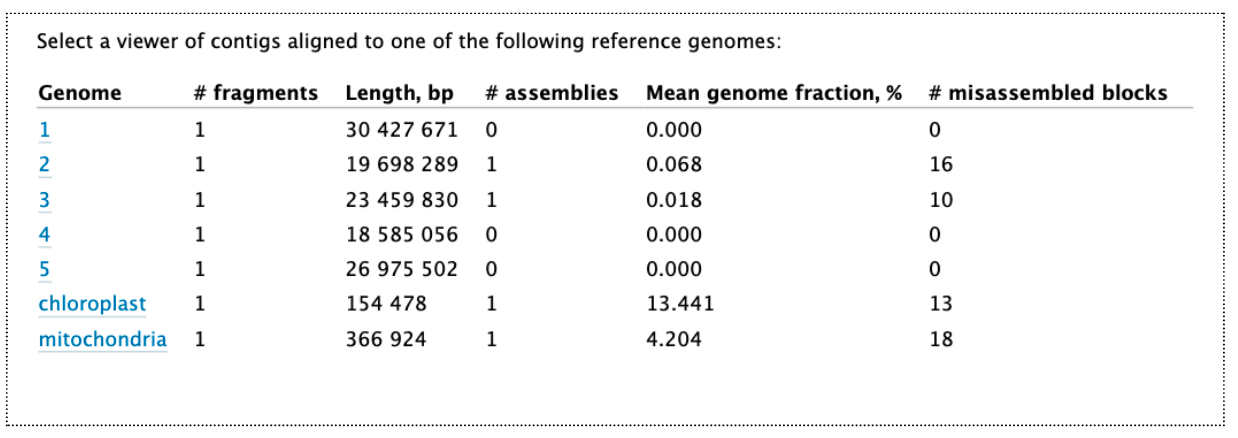
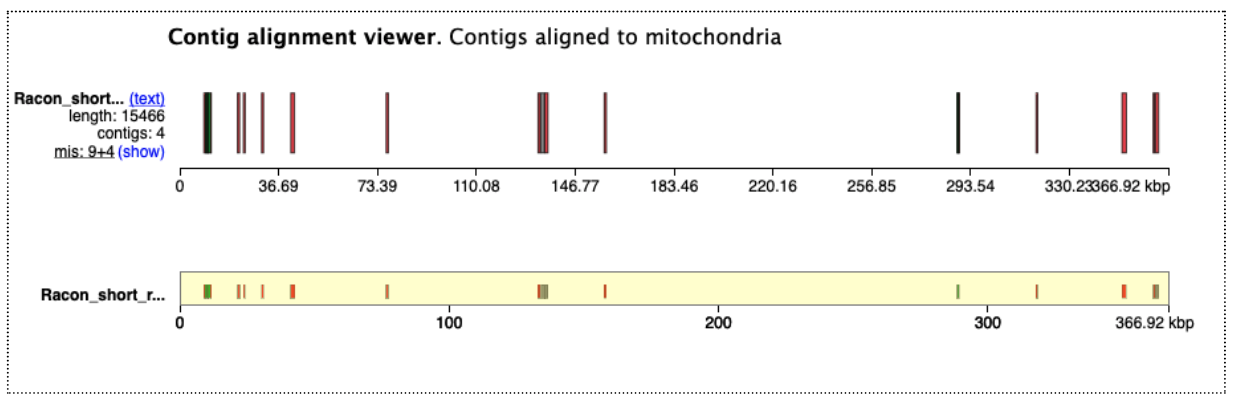
Open the Quast HTML report, and at the top of this, click on “View in Icarus contig browser”. This shows how our assembly contigs have mapped to the reference genome. For this reference genome there are 5 chromosomes and two organelles. As this reference genome species is not closely related, not many contigs have mapped well. But we can see that some of them match the organelles (which is expected, as these reads are likely to be overrepresented in the test data). For the nuclear genome, there are some matches to parts of chromosome 2 and 3.
Click on the “mitochondria” to see how the assembly contigs align to the reference mitochondrial genome. Click the -5x button to zoom out to the full length.
Combining workflows
We can combine these galaxy workflows into a single workflow. (See this GTN tutorial for more information.)
Combined assembly and polishing workflow
Hands On: Run the Combined Assembly and Polishing workflow
Find this workflow, enter the correct input files, and run.
What it does: A workflow for genome assembly, containing subworkflows:
Data QC
Kmer counting
Trim and filter reads
Assembly with Flye
Assembly polishing
Assess genome quality
Inputs
long reads and short reads in fastq format
reference genome for Quast
Outputs
Data information - QC, kmers
Filtered, trimmed reads
Genome assembly, assembly graph, stats
Polished assembly, stats
Quality metrics - Busco, Quast
Tools used: Sum of tools in each of the subworkflows
Input parameters: None required
Workflow steps: For detail see each subworkflow
Options:
Omit some steps - e.g. Data QC and kmer counting
Replace a module with one using a different tool - e.g. change assembly tool
Summary
In this tutorial we have assembled sequencing reads into contigs, using tools and workflows in Galaxy. Although we have used test data, these tools and workflows should work on real-sized eukaryotic data sets although please see our recommendations in the Introduction section.
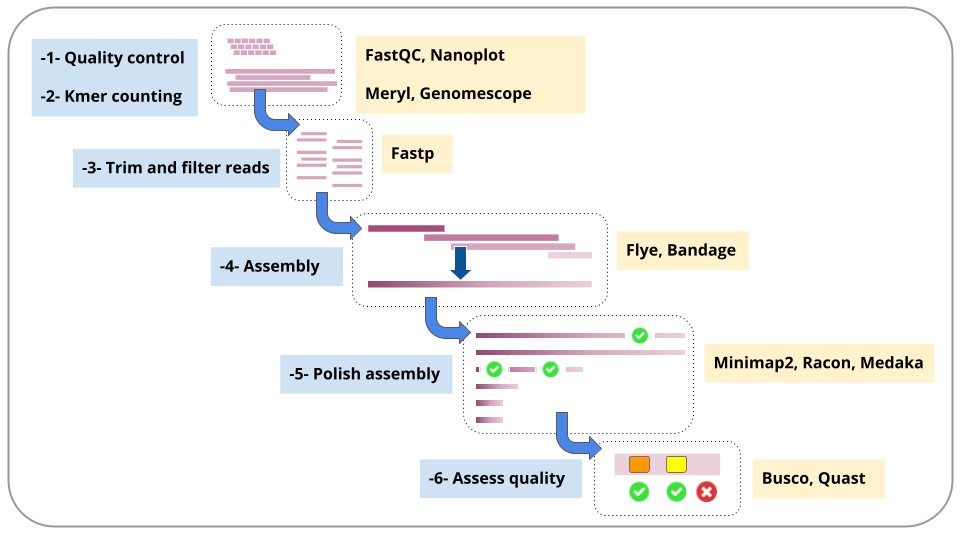
A summary of the workflow steps and the main tools used:
We hope this has been useful for both learning about genome assembly concepts and as a customisable example for your own assembly data.
You've Finished the Tutorial
Please also consider filling out the Feedback Form as well!
Key points
We can assemble long reads from plant or animal species into large contigs
These contigs can be polished with both long and short reads
We can assess the quality of this assembly with various tools
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channels
Simão, F. A., R. M. Waterhouse, P. Ioannidis, E. V. Kriventseva, and E. M. Zdobnov, 2015 BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics 31: 3210–3212. 10.1093/bioinformatics/btv351
Mikheenko, A., G. Valin, A. Prjibelski, V. Saveliev, and A. Gurevich, 2016 Icarus: visualizer for de novo assembly evaluation. Bioinformatics 32: 3321–3323. 10.1093/bioinformatics/btw379
Vurture, G. W., F. J. Sedlazeck, M. Nattestad, C. J. Underwood, H. Fang et al., 2017 GenomeScope: fast reference-free genome profiling from short reads (B. Berger, Ed.). Bioinformatics 33: 2202–2204. 10.1093/bioinformatics/btx153
Rhie, A., B. P. Walenz, S. Koren, and A. M. Phillippy, 2020 Merqury: reference-free quality, completeness, and phasing assessment for genome assemblies. Genome Biology 21: 10.1186/s13059-020-02134-9
Wang, W., A. Das, D. Kainer, M. Schalamun, A. Morales-Suarez et al., 2020 The draft nuclear genome assembly of Eucalyptus pauciflora: a pipeline for comparing de novo assemblies. GigaScience 9: 10.1093/gigascience/giz160
Aury, J.-M., and B. Istace, 2021 Hapo-G, haplotype-aware polishing of genome assemblies with accurate reads. NAR Genomics and Bioinformatics 3: 10.1093/nargab/lqab034
Chen, Y., F. Nie, S.-Q. Xie, Y.-F. Zheng, Q. Dai et al., 2021 Efficient assembly of nanopore reads via highly accurate and intact error correction. Nature Communications 12: 10.1038/s41467-020-20236-7
McCartney, A. M., E. Hilario, S.-S. Choi, J. Guhlin, J. M. Prebble et al., 2021 An exploration of assembly strategies and quality metrics on the accuracy of the rewarewa Knightia excelsa genome. Molecular Ecology Resources. 10.1111/1755-0998.13406
Nurk, S., S. Koren, A. Rhie, M. Rautiainen, A. V. Bzikadze et al., 2021 The complete sequence of a human genome. 10.1101/2021.05.26.445798
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{assembly-largegenome,
author = "Anna Syme",
title = "Large genome assembly and polishing (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/assembly/tutorials/largegenome/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Funding
These individuals or organisations provided funding support for the development of this resource
Questions: