This is an Introduction to Machine Learning in R, in which you’ll learn the basics of unsupervised learning for pattern recognition and supervised learning for prediction. At the end of this workshop, we hope that you will:
appreciate the importance of performing exploratory data analysis (or EDA) before starting to model your data.
understand the basics of unsupervised learning and know the examples of principal component analysis (PCA) and k-means clustering.
understand the basics of supervised learning for prediction and the differences between classification and regression.
understand modern machine learning techniques and principles, such as test train split, k-fold cross validation and regularization.
be able to write code to implement the above techniques and methodologies using R, caret and glmnet.
We will not be focusing on the mathematical foundation for each of the methods and approaches we’ll be discussing. There are many resources that can provide this context, but for the purposes of this workshop we believe that they are beyond the scope.
Note: All material here has been adapted from the course material for the Machine Learning course at SIB (22-23/07/2020) Baichoo et al. 2020
Machine Learning basic concepts
Machine Learning (ML) is a subset of Artificial Intelligence (AI) in the field of computer science that often uses statistical techniques to give computers the ability to “learn” (i.e., progressively improve performance on a specific task) with data, without being explicitly programmed.
Machine Learning is often closely related, if not used as an alternate term, to fields like Data Mining (the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems), Pattern Recognition, Statistical Inference or Statistical Learning. All these areas often employ the same methods and perhaps the name changes based on the practitioner’s expertise or the application domain.
Taxonomy of ML and examples of algorithms
The main ML tasks are typically classified into two broad categories, depending on whether there is “feedback” or a “teacher” available to the learning system or not.
Supervised Learning: The system is presented with example inputs and their desired outputs provided by the “teacher” and the goal of the machine learning algorithm is to create a mapping from the inputs to the outputs. The mapping can be thought of as a function that if it is given as an input one of the training samples it should output the desired value.
Unsupervised Learning: In the unsupervised learning case, the machine learning algorithm is not given any examples of desired output, and is left on its own to find structure in its input.
The main machine learning tasks are separated based on what the system tries to accomplish in the end:
Dimensionality Reduction: simplifies inputs by mapping them into a lower-dimensional space. Topic modeling is a related problem, where a program is given a list of human language documents and is tasked with finding out which documents cover similar topics.
Clustering: a set of inputs is to be divided into groups. Unlike in classification, the groups
are not known beforehand, making this typically an unsupervised task.
Classification: inputs are divided into two or more classes, and the learner must produce a model that assigns unseen inputs to one or more (multi-label classification) of these classes. This is typically tackled in a supervised manner. Identification of patient vs cases is an example of classification, where the inputs are gene expression and/or clinical profiles and the classes are “patient” and “healthy”.
Regression: also a supervised problem, the outputs are continuous rather than discrete.
Association Rules learning (or dependency modelling): Searches for relationships between inputs. For example, a supermarket might gather data on customer purchasing habits. Using association rule learning, the supermarket can determine which products are frequently bought together and use this information for marketing purposes. This is sometimes referred to as market basket analysis.
Overview of Deep learning
Deep learning is a recent trend in machine learning that models highly non-linear representations of data. In the past years, deep learning has gained a tremendous momentum and prevalence for a variety of applications. Among these are image and speech recognition, driverless cars, natural language processing and many more. Interestingly, the majority of mathematical concepts for deep learning have been known for decades. However, it is only through several recent developments that the full potential of deep learning has been unleashed. The success of deep learning has led to a wide range of frameworks and libraries for various programming languages. Examples include Caffee, Theano, Torch and TensorFlow, amongst others.
The R programming language has gained considerable popularity among statisticians and data miners for its ease-of-use, as well as its sophisticated visualizations and analyses. With the advent of the deep learning era, the support for deep learning in R has grown ever since, with an increasing number of packages becoming available. This section presents an overview on deep learning in R as provided by the following packages: MXNetR, darch, deepnet, H2O and deepr. It’s important noting that the underlying learning algorithms greatly vary from one package to another. As such, the following table shows a list of the available methods/architectures in each of the packages.
Simplify some functions from H2O and deepnet packages
Applications of ML in Bioinformatics
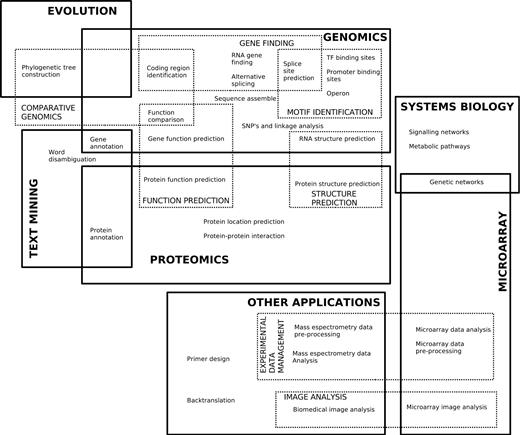
There are several biological domains where machine learning techniques are applied for knowledge extraction from data. The following figure (retrieved from Larrañaga et al. 2006) shows a scheme of the main biological problems where computational methods are being applied.
An extensive list of examples of applications of Machine Learning in Bioinformatics can be found in the Larrañaga et al. 2006
How to choose the right Machine Learning technique?
Tip 4 in the “Ten quick tips for machine learning in computational biology” (Chicco 2017) provides a nice overview of what one should keep in mind, when choosing the right Machine Learning technique in Bioinformatics.
Which algorithm should you choose to start? In short; The simplest one!
Once you understand what kind of biological problem you are trying to solve, and which method category can fit your situation, you then have to choose the machine learning algorithm with which to start your project. Even if it always advisable to use multiple techniques and compare their results, the decision on which one to start can be tricky.
Many textbooks suggest to select a machine learning method by just taking into account the problem representation, while Pedro Domingos (“A few useful things to know about machine learning”, Commun ACM. 2012; 55(10):78–87) suggests to take into account also the cost evaluation, and the performance optimization.
This algorithm-selection step, which usually occurs at the beginning of a machine learning journey, can be dangerous for beginners. In fact, an inexperienced practitioner might end up choosing a complicated, inappropriate data mining method which might lead him/her to bad results, as well as to lose precious time and energy. Therefore, this is our tip for the algorithm selection: if undecided, start with the simplest algorithm (Hand DJ, “Classifier technology and the illusion of progress”. Stat Sci. 2006; 21(1):1–14).
By employing a simple algorithm, you will be able to keep everything under control, and better understand what is happening during the application of the method. In addition, a simple algorithm will provide better generalization skills, less chance of overfitting, easier training and faster learning properties than complex methods. As David J. Hand explained, complex models should be employed only if the dataset features provide some reasonable justification for their usage.
Exploratory Data Analysis (EDA) and Unsupervised Learning
Before diving in the tutorial, we need to open RStudio. If you do not know how or never interacted with RStudio, please follow the dedicated tutorial.
Hands On: Launch RStudio
Depending on which server you are using, you may be able to run RStudio directly in Galaxy. If that is not available, RStudio Cloud can be an alternative.
The tool will start running and will stay running permanently
Click on the “User” menu at the top and go to “Active InteractiveTools” and locate the RStudio instance you started.
If RStudio is not available on the Galaxy instance:
Register for RStudio Cloud, or login if you already have an account
Create a new project
Hands On: Installing Required Packages
Run the following code to install required packages
## To install needed CRAN packages:install.packages("tidyverse")install.packages("GGally")install.packages("caret")install.packages("gmodels")install.packages("rpart")install.packages("rpart.plot")install.packages("dendextend")install.packages("randomForest")install.packages("mlr3")install.packages("devtools")## To install needed Bioconductor packages:if(!requireNamespace("BiocManager",quietly=TRUE))install.packages("BiocManager")BiocManager::install()BiocManager::install(c("limma","edgeR"))# To install libraries from GitHub sourcelibrary(devtools)install_github("vqv/ggbiplot")
Loading and exploring data
The data that we will be using for this workshop are from the following sources:
We will first load up the UCI dataset. The dataset itself does not contain column names, we’ve created a second file with only the column names, which we will use.
We will be using tidyverse, a collection of R packages for Data Science.
Hands On: Load the UCI Dataset
Load the data
library(tidyverse)# working with data frames, plottingbreastCancerData<-read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",col_names=FALSE)breastCancerDataColNames<-read_csv("https://raw.githubusercontent.com/fpsom/2020-07-machine-learning-sib/master/data/wdbc.colnames.csv",col_names=FALSE)colnames(breastCancerData)<-breastCancerDataColNames$X1
If all goes well, we can see that our dataset contains 569 observations across 32 variables. This is what the first 6 lines look like:
# Check out head of dataframe
breastCancerData %>% head()
# A tibble: 6 x 32
ID Diagnosis Radius.Mean Texture.Mean Perimeter.Mean Area.Mean Smoothness.Mean
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 8.42e5 M 18.0 10.4 123. 1001 0.118
2 8.43e5 M 20.6 17.8 133. 1326 0.0847
3 8.43e7 M 19.7 21.2 130 1203 0.110
4 8.43e7 M 11.4 20.4 77.6 386. 0.142
5 8.44e7 M 20.3 14.3 135. 1297 0.100
6 8.44e5 M 12.4 15.7 82.6 477. 0.128
# ... with 25 more variables: Compactness.Mean <dbl>, Concavity.Mean <dbl>,
# Concave.Points.Mean <dbl>, Symmetry.Mean <dbl>, Fractal.Dimension.Mean <dbl>,
# Radius.SE <dbl>, Texture.SE <dbl>, Perimeter.SE <dbl>, Area.SE <dbl>,
# Smoothness.SE <dbl>, Compactness.SE <dbl>, Concavity.SE <dbl>, Concave.Points.SE <dbl>,
# Symmetry.SE <dbl>, Fractal.Dimension.SE <dbl>, Radius.Worst <dbl>, Texture.Worst <dbl>,
# Perimeter.Worst <dbl>, Area.Worst <dbl>, Smoothness.Worst <dbl>,
# Compactness.Worst <dbl>, Concavity.Worst <dbl>, Concave.Points.Worst <dbl>,
# Symmetry.Worst <dbl>, Fractal.Dimension.Worst <dbl>
We will also make our Diagnosis column a factor:
# Make Diagnosis a factorbreastCancerData$Diagnosis<-as.factor(breastCancerData$Diagnosis)
Question
What is a factor?
TODO
What is Exploratory Data Analysis (EDA) and why is it useful?
Before thinking about modeling, have a look at your data. There is no point in throwing a 10000 layer convolutional neural network (whatever that means) at your data before you even know what you’re dealing with.
We will first remove the first column, which is the unique identifier of each row:
Question
Why?
TODO
Hands On: Exploratory Data Analysis
Remove the first column
# Remove first columnbreastCancerDataNoID<-breastCancerData[2:ncol(breastCancerData)]
View the dataset. The output should like like this:
Note that the features have widely varying centers and scales (means and standard deviations), so we’ll want to center and scale them in some situations. We will use the [caret](https://cran.r-project.org/web/packages/caret/vignettes/caret.html) package for this, and specifically, the preProcess function.
The preProcess function can be used for many operations on predictors, including centering and scaling. The function preProcess estimates the required parameters for each operation and predict.preProcess is used to apply them to specific data sets. This function can also be interfaced when calling the train function.
library(caret)# Center & scale datappv<-preProcess(breastCancerDataNoID,method=c("center","scale"))breastCancerDataNoID_tr<-predict(ppv,breastCancerDataNoID)
Let’s have a look on the impact of this process by viewing the summary of the first 5 variables before and after the process:
# Summarize first 5 columns of the original databreastCancerDataNoID[1:5]%>%summary()
It should look like:
Diagnosis Radius.Mean Texture.Mean Perimeter.Mean Area.Mean
B:357 Min. : 6.981 Min. : 9.71 Min. : 43.79 Min. : 143.5
M:212 1st Qu.:11.700 1st Qu.:16.17 1st Qu.: 75.17 1st Qu.: 420.3
Median :13.370 Median :18.84 Median : 86.24 Median : 551.1
Mean :14.127 Mean :19.29 Mean : 91.97 Mean : 654.9
3rd Qu.:15.780 3rd Qu.:21.80 3rd Qu.:104.10 3rd Qu.: 782.7
Max. :28.110 Max. :39.28 Max. :188.50 Max. :2501.0
Let’s check the summary of the re-centered and scaled data
# Summarize first 5 columns of the re-centered and scaled databreastCancerDataNoID_tr[1:5]%>%summary()
It now should look like this:
Diagnosis Radius.Mean Texture.Mean Perimeter.Mean Area.Mean
B:357 Min. :-2.0279 Min. :-2.2273 Min. :-1.9828 Min. :-1.4532
M:212 1st Qu.:-0.6888 1st Qu.:-0.7253 1st Qu.:-0.6913 1st Qu.:-0.6666
Median :-0.2149 Median :-0.1045 Median :-0.2358 Median :-0.2949
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.4690 3rd Qu.: 0.5837 3rd Qu.: 0.4992 3rd Qu.: 0.3632
Max. : 3.9678 Max. : 4.6478 Max. : 3.9726 Max. : 5.2459
As, we can observe here, all variables in our new data have a mean of 0 while maintaining the same distribution of the values. However, this also means that the absolute values do not correspond to the “real”, original data - and is just a representation of them.
We can also check whether our plot has changed with the new data:
Figure 3: ggpairs output of the first 5 variables of the recentered/rescaled data
Question
Do you see any differences?
TODO
Unsupervised Learning
Dimensionality Reduction and PCA
Machine learning is the science and art of giving computers the ability to learn to make decisions from data without being explicitly programmed.
Unsupervised learning, in essence, is the machine learning task of uncovering hidden patterns and structures from unlabeled data. For example, a researcher might want to group their samples into distinct groups, based on their gene expression data without in advance what these categories maybe. This is known as clustering, one branch of unsupervised learning.
Supervised learning (which will be addressed later in depth), is the branch of machine learning that involves predicting labels, such as whether a tumor will be benign or malignant.
Another form of unsupervised learning, is dimensionality reduction; in the UCI dataset, for example, there are too many features to keep track of. What if we could reduce the number of features yet still keep much of the information?
Principal component analysis (PCA) is one of the most commonly used methods of dimensionality reduction, and extracts the features with the largest variance. What PCA essentially does is the following:
The first step of PCA is to decorrelate your data and this corresponds to a linear transformation of the vector space your data lie in;
The second step is the actual dimension reduction; what is really happening is that your decorrelation step (the first step above) transforms the features into new and uncorrelated features; this second step then chooses the features that contain most of the information about the data.
Hands On: Dimensionality Reduction & PCA
Let’s have a look into the variables that we currently have, and apply PCA to them. As you can see, we will be using only the numerical variables (i.e. we will exclude the first two, ID and Diagnosis):
We can use the summary() function to get a summary of the PCA:
summary(ppv_pca)
The resulting table, shows us the importance of each Principal Component; the standard deviation, the proportion of the variance that it captures, as well as the cumulative proportion of variance capture by the principal components.
Principal Components are the underlying structure in the data. They are the directions where there is the most variance, the directions where the data is most spread out. This means that we try to find the straight line that best spreads the data out when it is projected along it. This is the first principal component, the straight line that shows the most substantial variance in the data.
PCA is a type of linear transformation on a given data set that has values for a certain number of variables (coordinates) for a certain amount of spaces. In this way, you transform a set of x correlated variables over y samples to a set of p uncorrelated principal components over the same samples.
Where many variables correlate with one another, they will all contribute strongly to the same principal component. Where your initial variables are strongly correlated with one another, you will be able to approximate most of the complexity in your dataset with just a few principal components. As you add more principal components, you summarize more and more of the original dataset. Adding additional components makes your estimate of the total dataset more accurate, but also more unwieldy.
Every eigenvector has a corresponding eigenvalue. Simply put, an eigenvector is a direction, such as “vertical” or “45 degrees”, while an eigenvalue is a number telling you how much variance there is in the data in that direction. The eigenvector with the highest eigenvalue is, therefore, the first principal component. The number of eigenvalues and eigenvectors that exits is equal to the number of dimensions the data set has. In our case, we had 30 variables (32 original, minus the first two), so we have produced 30 eigenvectors / PCs. And we can see that we can address more than 95% of the variance (0.95157) using only the first 10 PCs.
Hands On: Deeper look into PCA
We should also have a deeper look in our PCA object:
str(ppv_pca)
The output should look like this:
List of 5
$ sdev : num [1:30] 3.64 2.39 1.68 1.41 1.28 ...
$ rotation: num [1:30, 1:30] -0.219 -0.104 -0.228 -0.221 -0.143 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:30] "Radius.Mean" "Texture.Mean" "Perimeter.Mean" "Area.Mean" ...
.. ..$ : chr [1:30] "PC1" "PC2" "PC3" "PC4" ...
$ center : Named num [1:30] 14.1273 19.2896 91.969 654.8891 0.0964 ...
..- attr(*, "names")= chr [1:30] "Radius.Mean" "Texture.Mean" "Perimeter.Mean" "Area.Mean" ...
$ scale : Named num [1:30] 3.524 4.301 24.299 351.9141 0.0141 ...
..- attr(*, "names")= chr [1:30] "Radius.Mean" "Texture.Mean" "Perimeter.Mean" "Area.Mean" ...
$ x : num [1:569, 1:30] -9.18 -2.39 -5.73 -7.12 -3.93 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : NULL
.. ..$ : chr [1:30] "PC1" "PC2" "PC3" "PC4" ...
- attr(*, "class")= chr "prcomp"
The information listed captures the following:
The center point ($center), scaling ($scale) and the standard deviation($sdev) of each original variable
The relationship (correlation or anticorrelation, etc) between the initial variables and the principal components ($rotation)
The values of each sample in terms of the principal components ($x)
Let’s try to visualize the results we’ve got so far. We will be using the ggbiplot library for this purpose.
ggbiplot(ppv_pca,choices=c(1,2),labels=rownames(breastCancerData),ellipse=TRUE,groups=breastCancerData$Diagnosis,obs.scale=1,var.axes=TRUE,var.scale=1)+ggtitle("PCA of Breast Cancer Dataset")+theme_minimal()+theme(legend.position="bottom")
Figure 4: Visualization of the first two PCs on the UCI Breast Cancer dataset
Question
Try changing the parameters of the plot. For example, check the choices and the var.scale. Is there an impact? What does this mean?
We have been using the entire table of data. What if we restrict our analysis on the mean values (i.e. columns 3-12)? Is there an impact?
TODO
Clustering
One popular technique in unsupervised learning is clustering. As the name itself suggests, Clustering algorithms group a set of data points into subsets or clusters. The algorithms’ goal is to create clusters that are coherent internally, but clearly different from each other externally. In other words, entities within a cluster should be as similar as possible and entities in one cluster should be as dissimilar as possible from entities in another.
Broadly speaking there are two ways of clustering data points based on the algorithmic structure and operation, namely agglomerative and divisive.
Agglomerative: An agglomerative approach begins with each observation in a distinct (singleton) cluster, and successively merges clusters together until a stopping criterion is satisfied.
Divisive: A divisive method begins with all patterns in a single cluster and performs splitting until a stopping criterion is met.
Essentially, this is the task of grouping your data points, based on something about them, such as closeness in space. Clustering is more of a tool to help you explore a dataset, and should not always be used as an automatic method to classify data. Hence, you may not always deploy a clustering algorithm for real-world production scenario. They are often too unreliable, and a single clustering alone will not be able to give you all the information you can extract from a dataset.
K-Means
What we are going to do is group the tumor data points into two clusters using an algorithm called k-means, which aims to cluster the data in order to minimize the variances of the clusters. The basic idea behind k-means clustering consists of defining clusters so that the total intra-cluster variation (known as total within-cluster variation) is minimized. There are several k-means algorithms available. However, the standard algorithm defines the total within-cluster variation as the sum of squared distances Euclidean distances between items and the corresponding centroid:
Hands On: Let's cluster our data
Let’s cluster our data points (ignoring their know classes) using k-means and then we’ll compare the results to the actual labels that we know:
The nstart option attempts multiple initial configurations and reports on the best one within the kmeans function. Seeds allow us to create a starting point for randomly generated numbers, so that each time our code is run, the same answer is generated.
Also, note that k-means requires the number of clusters to be defined beforehand and given via the centers option.
Let’s check now what the output contains:
str(km.out)
The output will be:
List of 9
$ cluster : int [1:569] 2 2 2 1 2 1 2 1 1 1 ...
$ centers : num [1:2, 1:30] 12.6 19.4 18.6 21.7 81.1 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:2] "1" "2"
.. ..$ : chr [1:30] "Radius.Mean" "Texture.Mean" "Perimeter.Mean" "Area.Mean" ...
$ totss : num 2.57e+08
$ withinss : num [1:2] 28559677 49383423
$ tot.withinss: num 77943100
$ betweenss : num 1.79e+08
$ size : int [1:2] 438 131
$ iter : int 1
$ ifault : int 0
- attr(*, "class")= chr "kmeans"
The information contained here is:
$cluster: a vector of integers (from 1:k) indicating the cluster to which each point is allocated.
$centers: a matrix of cluster centers.
$withinss: vector of within-cluster sum of squares, one component per cluster.
$tot.withinss: total within-cluster sum of squares (i.e. sum(withinss)).
$size: the number of points in each cluster.
Let’s have a look at the clusters, and we will do this in relationship to the principal components we identified earlier:
ggplot(as.data.frame(ppv_pca$x),aes(x=PC1,y=PC2,color=as.factor(km.out$cluster),shape=breastCancerData$Diagnosis))+geom_point(alpha=0.6,size=3)+theme_minimal()+theme(legend.position="bottom")+labs(title="K-Means clusters against PCA",x="PC1",y="PC2",color="Cluster",shape="Diagnosis")
Figure 5: Visualization of the k-means results against the first two PCs on the UCI Breast Cancer dataset
This is a rather complex plotting command that is based on the ggplot library. For an overview of how ggplot works, have a look at the RNA Seq Counts to Viz in R tutorial.
Now that we have a cluster for each tumor (clusters 1 and 2), we can check how well they coincide with the labels that we know. To do this we will use a cool method called cross-tabulation: a cross-tab is a table that allows you to read off how many data points in clusters 1 and 2 were actually benign or malignant respectively.
# Cross-tab of clustering & known labelslibrary(gmodels)CrossTable(breastCancerData$Diagnosis,km.out$cluster)
The output should look like this:
Cell Contents
|-------------------------|
| N |
| Chi-square contribution |
| N / Row Total |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 569
| km.out$cluster
breastCancerData$Diagnosis | 1 | 2 | Row Total |
---------------------------|-----------|-----------|-----------|
B | 356 | 1 | 357 |
| 23.988 | 80.204 | |
| 0.997 | 0.003 | 0.627 |
| 0.813 | 0.008 | |
| 0.626 | 0.002 | |
---------------------------|-----------|-----------|-----------|
M | 82 | 130 | 212 |
| 40.395 | 135.060 | |
| 0.387 | 0.613 | 0.373 |
| 0.187 | 0.992 | |
| 0.144 | 0.228 | |
---------------------------|-----------|-----------|-----------|
Column Total | 438 | 131 | 569 |
| 0.770 | 0.230 | |
---------------------------|-----------|-----------|-----------|
Question: How well did the clustering work?
Optimal k
One technique to choose the best k is called the elbow method. This method uses within-group homogeneity or within-group heterogeneity to evaluate the variability. In other words, you are interested in the percentage of the variance explained by each cluster. You can expect the variability to increase with the number of clusters, alternatively, heterogeneity decreases. Our challenge is to find the k that is beyond the diminishing returns. Adding a new cluster does not improve the variability in the data because very few information is left to explain.
Hands On: Finding the optimal k
First of all, let’s create a function that computes the total within clusters sum of squares:
We can try for a single k (e.g. 2), and see the value:
kmean_withinss(2)
[1] 77943100
However, we need to test this n times. We will use the sapply() function to run the algorithm over a range of k. This technique is faster than creating a loop and store the value each time.
# Set maximum clustermax_k<-20# Run algorithm over a range of kwss<-sapply(2:max_k,kmean_withinss)
Finally, let’s save the results into a data frame, so that we can work with it:
# Create a data frame to plot the graphelbow<-data.frame(2:max_k,wss)
Now that we have the data, we can plot them and try to identify the “elbow” point:
# Plot the graph with gglopggplot(elbow,aes(x=X2.max_k,y=wss))+geom_point()+geom_line()+scale_x_continuous(breaks=seq(1,20,by=1))
From the graph, you can see the optimal k is around 10, where the curve is starting to have a diminishing return.
Question
Try re-running the clustering step with the new k. Is there a significant difference?
Try to think of alternative metrics that could be used as a “distance” measure, instead of the default “Euclidean”. Do you think there might be an optimal for our case?
TODO
Hierarchical clustering
k-means clustering requires us to specify the number of clusters, and determining the optimal number of clusters is often not trivial. Hierarchical clustering is an alternative approach which builds a hierarchy from the bottom-up, and doesn’t require us to specify the number of clusters beforehand but requires extra steps to extract final clusters.
The algorithm works as follows:
Put each data point in its own cluster.
Identify the closest two clusters and combine them into one cluster.
Repeat the above step till all the data points are in a single cluster.
Once this is done, it is usually represented by a dendrogram like structure. There are a few ways to determine how close two clusters are:
Complete linkage clustering: Find the maximum possible distance between points belonging to two different clusters.
Single linkage clustering: Find the minimum possible distance between points belonging to two different clusters.
Mean linkage clustering: Find all possible pairwise distances for points belonging to two different clusters and then calculate the average.
Centroid linkage clustering: Find the centroid of each cluster and calculate the distance between centroids of two clusters.
Hands On: k-means Clustering
We will be applying Hierarchical clustering to our dataset, and see what the result might be. Remember that our dataset has some columns with nominal (categorical) values (columns ID and Diagnosis), so we will need to make sure we only use the columns with numerical values. There are no missing values in this dataset that we need to clean before clustering. But the scales of the features are different and we need to normalize it.
There are several options for method: euclidean, maximum, manhattan, canberra, binary or minkowski.
The next step is to actually perform the hierarchical clustering, which means that at this point we should decide which linkage method we want to use. We can try all kinds of linkage methods and later decide on which one performed better. Here we will proceed with average linkage method (i.e. UPGMA); other methods include ward.D, ward.D2, single, complete, mcquitty (= WPGMA), median (= WPGMC) and centroid (= UPGMC).
Notice how the dendrogram is built and every data point finally merges into a single cluster with the height(distance) shown on the y-axis.
Next, we can cut the dendrogram in order to create the desired number of clusters. In our case, we might want to check whether our two groups (M and B) can be identified as sub-trees of our clustering - so we’ll set k = 2 and then plot the result.
cut_avg<-cutree(hclust_avg,k=2)plot(hclust_avg,labels=breastCancerData$ID,hang=-1,cex=0.2,main="Cluster dendrogram (k = 2)",xlab="Breast Cancer ID",ylab="Height")# k: Cut the dendrogram such that exactly k clusters are produced# border: Vector with border colors for the rectangles. Coild also be a number vector 1:2# which: A vector selecting the clusters around which a rectangle should be drawn (numbered from left to right)rect.hclust(hclust_avg,k=2,border=c("red","green"),which=c(1,2))# Draw a line at the height that the cut takes placeabline(h=18,col='red',lwd=3,lty=2)
Now we can see the two clusters enclosed in two different colored boxes. We can also use the color_branches() function from the dendextend library to visualize our tree with different colored branches.
library(dendextend)avg_dend_obj<-as.dendrogram(hclust_avg)# We can use either k (number of clusters), or clusters (and specify the cluster type)avg_col_dend<-color_branches(avg_dend_obj,k=2,groupLabels=TRUE)plot(avg_col_dend,main="Cluster dendrogram with color per cluster (k = 2)",xlab="Breast Cancer ID",ylab="Height")
We can change the way branches are colored, to reflect the Diagnosis value:
avg_col_dend<-color_branches(avg_dend_obj,clusters=breastCancerData$Diagnosis)plot(avg_col_dend,main="Cluster dendrogram with Diagnosis color",xlab="Breast Cancer ID",ylab="Height")
ggplot(as.data.frame(ppv_pca$x),aes(x=PC1,y=PC2,color=as.factor(cut_avg),shape=breastCancerData$Diagnosis))+geom_point(alpha=0.6,size=3)+theme_minimal()+theme(legend.position="bottom")+labs(title="Hierarchical clustering (cut at k=2) against PCA",x="PC1",y="PC2",color="Cluster",shape="Diagnosis")
Figure 11: Visualization of the Hierarchical clustering (cut at k=2) results against the first two PCs on the UCI Breast Cancer dataset
Question
The hierarchical clustering performed so far, only used two methods: euclidean and average. Try experimenting with different methods. Do the final results improve?
Obviously the cut-off selection (k=2) was not optimal. Try using different cut-offs to ensure that the final clustering could provide some context to the original question.
TODO
Supervised Learning
Supervised learning is the branch of Machine Learning (ML) that involves predicting labels, such as ‘Survived’ or ‘Not’. Such models learn from labelled data, which is data that includes whether a passenger survived (called “model training”), and then predict on unlabeled data.
These are generally called train and test sets because
You want to build a model that learns patterns in the training set, and
You then use the model to make predictions on the test set.
We can then calculate the percentage that you got correct: this is known as the accuracy of your model.
How To Start with Supervised Learning
As you might already know, a good way to approach supervised learning is the following:
Perform an Exploratory Data Analysis (EDA) on your data set;
Build a quick and dirty model, or a baseline model, which can serve as a comparison against later models that you will build;
Iterate this process. You will do more EDA and build another model;
Engineer features: take the features that you already have and combine them or extract more information from them to eventually come to the last point, which is
Get a model that performs better.
A common practice in all supervised learning is the construction and use of the train- and test- datasets. This process takes all of the input randomly splits into the two datasets (training and test); the ratio of the split is usually up to the researcher, and can be anything: 80/20, 70/30, 60/40…
Supervised Learning I: classification
There are various classifiers available:
Decision Trees – These are organized in the form of sets of questions and answers in the tree structure.
Naive Bayes Classifiers – A probabilistic machine learning model that is used for classification.
K-NN Classifiers – Based on the similarity measures like distance, it classifies new cases.
Support Vector Machines – It is a non-probabilistic binary classifier that builds a model to classify a case into one of the two categories. They rely on a kernel function that essentially projects the data points to higher-dimensional space; depending on this new space, there can be both linear and non-linear SVMs.
Decision trees
It is a type of supervised learning algorithm. We use it for classification problems. It works for both types of input and output variables. In this technique, we split the population into two or more homogeneous sets. Moreover, it is based on the most significant splitter/differentiator in input variables.
The Decision Tree is a powerful non-linear classifier. A Decision Tree makes use of a tree-like structure to generate relationship among the various features and potential outcomes. It makes use of branching decisions as its core structure.
There are two types of decision trees:
Categorical (classification) Variable Decision Tree: Decision Tree which has a categorical target variable.
Continuous (Regression) Variable Decision Tree: Decision Tree has a continuous target variable.
Regression trees are used when the dependent variable is continuous while classification trees are used when the dependent variable is categorical. In continuous, a value obtained is a mean response of observation. In classification, a value obtained by a terminal node is a mode of observations.
Hands On: Decision Trees
Here, we will use the rpart and the rpart.plot package in order to produce and visualize a decision tree. First of all, we’ll create the train and test datasets using a 70/30 ratio and a fixed seed so that we can reproduce the results.
# split into training and test subsetsset.seed(1000)ind<-sample(2,nrow(breastCancerData),replace=TRUE,prob=c(0.7,0.3))breastCancerData.train<-breastCancerDataNoID[ind==1,]breastCancerData.test<-breastCancerDataNoID[ind==2,]
Now, we will load the library and create our model. We would like to create a model that predicts the Diagnosis based on the mean of the radius and the area, as well as the SE of the texture. For ths reason we’ll use the notation of myFormula <- Diagnosis ~ Radius.Mean + Area.Mean + Texture.SE. If we wanted to create a prediction model based on all variables, we will have used myFormula <- Diagnosis ~ . instead. Finally, minsplit stands for the the minimum number of instances in a node so that it is split.
Now that we have a model, we should check how the prediction works in our test dataset.
## make predictionBreastCancer_pred<-predict(breastCancerData.pruned.model,newdata=breastCancerData.test,type="class")plot(BreastCancer_pred~Diagnosis,data=breastCancerData.test,xlab="Observed",ylab="Prediction")table(BreastCancer_pred,breastCancerData.test$Diagnosis)
Can we improve the above model? What are the key parameters that have the most impact?
We have been using only some of the variables in our model. What is the impact of using all variables / features for our prediction? Is this a good or a bad plan?
TODO
Random Forests
Random Forests is an ensemble learning technique, which essentially constructs multiple decision trees. Each tree is trained with a random sample of the training dataset and on a randomly chosen subspace. The final prediction result is derived from the predictions of all individual trees, with mean (for regression) or majority voting (for classification). The advantage is that it has better performance and is less likely to overfit than a single decision tree; however it has lower interpretability.
There are two main libraries in R that provide the functionality for Random Forest creation; the randomForest and the party: cforest().
Package randomForest
very fast
cannot handle data with missing values
a limit of 32 to the maximum number of levels of each categorical attribute
extensions: extendedForest, gradientForest
Package party: cforest()
not limited to the above maximum levels
slow
needs more memory
In this exercise, we will be using the randomForest.
The output shows the individual components and internal parameters of the Random Forest model.
Call:
randomForest(formula = Diagnosis ~ ., data = breastCancerData.train, ntree = 100, proximity = T)
Type of random forest: classification
Number of trees: 100
No. of variables tried at each split: 5
OOB estimate of error rate: 4.28%
Confusion matrix:
B M class.error
B 249 5 0.01968504
M 12 131 0.08391608
We can view the overall performance of the model here:
Let’s try to do a prediction of the Diagnosis for the test set, using the new model. The margin of a data point is as the proportion of votes for the correct class minus maximum proportion of votes for other classes. Positive margin means correct classification.
Figure 18: Random Forest Cross-Valdidation for feature selection
Supervised Learning II: regression
Linear regression
Linear regression is to predict response with a linear function of predictors. The most common function in R for this is lm. In our dataset, let’s try to investigate the relationship between Radius.Mean, Concave.Points.Mean and Area.Mean.
Hands On: Linear Regression
We can get a first impression by looking at the correlation of these variables:
## correlation between Radius.Mean and Concave.Points.Mean / Area.Meancor(breastCancerData$Radius.Mean,breastCancerData$Concave.Points.Mean)## [1] 0.8225285cor(breastCancerData$Concave.Points.Mean,breastCancerData$Area.Mean)## [1] 0.8232689
This tells us what are the coefficients of Concave.Points.Mean and Area.Mean, in the linear equation that connects them to Radius.Mean. Let’s see if we can predict now the mean radius of a new sample, with Concave.Points.Mean = 2.724931 and Area.Mean = 0.00964.
Let’s make predictions on our training dataset and visualize
We can also have a better look at what the model contains with summary(bc_model_full):
Call:
lm(formula = Radius.Mean ~ ., data = bc)
Residuals:
Min 1Q Median 3Q Max
-4.8307 -0.1827 0.1497 0.3608 0.7411
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.6808702 0.0505533 151.936 <2e-16 ***
Concave.Points.Mean 2.7249328 1.0598070 2.571 0.0104 *
Area.Mean 0.0096400 0.0001169 82.494 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.5563 on 566 degrees of freedom
Multiple R-squared: 0.9752, Adjusted R-squared: 0.9751
F-statistic: 1.111e+04 on 2 and 566 DF, p-value: < 2.2e-16
But his only provides the evaluation on the whole dataset that we sued for training. we don’t know how it will perform on unknown dataset. So, let’s split our dataset into training and test set, create the model on training set and visualize the predictions
set.seed(123)ind<-sample(2,nrow(bc),replace=TRUE,prob=c(0.75,0.25))bc_train<-bc[ind==1,]bc_test<-bc[ind==2,]#Let's build now a linear regression model using the training data and print it:(bc_model<-lm(Radius.Mean~Concave.Points.Mean+Area.Mean,data=bc_train))#We can also view the model's summarysummary(bc_model)######Evaluating graphically#Let's make predictions on our training dataset and store the predictions as a new columnbc_train$pred<-predict(bc_model)# plot the ground truths vs predictions for training setggplot(bc_train,aes(x=pred,y=Radius.Mean))+geom_point()+geom_abline(color="blue")
You will note that it is quite similar to when using whole dataset
Let’s predict using test data
bc_test$pred<-predict(bc_model,newdata=bc_test)
and plot
# plot the ground truths vs predictions for test set and examine the plot. Does it look as good with the predictions on the training set?ggplot(bc_test,aes(x=pred,y=Radius.Mean))+geom_point()+geom_abline(color="blue")
Now let’s use the RMSE and the R_square metrics to evaluate our model on the training and test set. R_square measures how much of variability in dependent variable can be explained by the model. It is defined as the square of the correlation coefficient (R), and that is why it is called “R Square” (more info on the Wikipedia page for CoD).
Question
Try evaluating model using RMSE, but on the training set this time
##### Answer to exercise 1.#Calculate residualsres<-bc_train$Radius.Mean-bc_train$pred#For training data we can also obtain the residuals using the bc_model$residuals# Calculate RMSE, assign it to the variable rmse and print it(rmse<-sqrt(mean(res^2)))[1]0.5624438# Calculate the standard deviation of actual outcome and print it(sd_bc_train<-sd(bc_train$Radius.Mean))[1]3.494182
So we can see that our RMSE is very small compared to SD, hence it is a good model
Question
Calculate RMSE for the test data and check if the model is not overfit.
Evaluating model using R_square - on training set.
Calculate R_square for the test data and check if the model is not overfit.
TODO
# Calculate mean of outcome: bc_mean.bc_mean<-mean(bc_train$Radius.Mean)# Calculate total sum of squares: tss.tss<-sum((bc_train$Radius.Mean-bc_mean)^2)# Calculate residual sum of squares: rss.err<-bc_train$Radius.Mean-bc_train$predrss<-sum(err^2)# Calculate R-squared: rsq. Print it. Is it a good fit?(rsq<-1-(rss/tss))[1]0.974028
This again confirms that our model is very good as the R_square value is very close to 1
Conclusion
With the rise in high-throughput sequencing technologies, the volume of omics data has grown exponentially in recent times and a major issue is to mine useful knowledge from these data which are also heterogeneous in nature. Machine learning (ML) is a discipline in which computers perform automated learning without being programmed explicitly and assist humans to make sense of large and complex data sets. The analysis of complex high-volume data is not trivial and classical tools cannot be used to explore their full potential. Machine learning can thus be very useful in mining large omics datasets to uncover new insights that can advance the field of bioinformatics.
This tutorial was only a first introductory step into the main concepts and approaches in machine learning. We looked at some of the common methods being used to analyse a representative dataset, by providing a practical context through the use of basic but widely used R libraries. Hopefully, at this point, you will have acquired a first understanding of the standard ML processes, as well as the practical skills in applying them on familiar problems and publicly available real-world data sets.
You've Finished the Tutorial
Please also consider filling out the Feedback Form as well!
Key points
To be added
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channels
Larrañaga, P., B. Calvo, R. Santana, C. Bielza, J. Galdiano et al., 2006 Machine learning in bioinformatics. Briefings in Bioinformatics 7: 86–112. 10.1093/bib/bbk007
Chicco, D., 2017 Ten quick tips for machine learning in computational biology. BioData Mining 10: 10.1186/s13040-017-0155-3
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{statistics-intro-to-ml-with-r,
author = "Fotis E. Psomopoulos",
title = "Introduction to Machine Learning using R (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/statistics/tutorials/intro-to-ml-with-r/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Funding
These individuals or organisations provided funding support for the development of this resource
4 stars:
Liked: Good overall idea on ML
Disliked: Give more detailed information on how to interpret the graph results and on some commands
May 2023
4 stars:
Liked: Really interesting topic and very helpful to be able to run script in R
Disliked: The packages do not all install on galaxy.eu and some of the questions do not yet have answers
5 stars:
Liked: Reapplication of theories as techniques learnt in previous tutorials and transferring them from Galaxy to R
Disliked: Issues related to the installation and loading of packages in the Galaxy RStudio environment, ended up using the RStudio Cloud for analyses. Linking the outputs accordingly to the Galaxy History would be greatly beneficial
February 2023
4 stars:
Liked: Walkthrough and explanation
Disliked: Explain some of the more obscure packages used and their functions. Some were explained but other were not.
August 2022
3 stars:
Liked: Great overview of ML and the basic models to start.
Disliked: Many questions still lack solutions and there are some typos within the text.
June 2022
5 stars:
Liked: I liked the real world data set, and the real world steps of exploration followed by the analysis. I thought the step wise progression made a lot of sense to me. I like having both predicting a categorical variable and the linear regression. It was great having both as many tutorials concentrate on predicting dichotomous outcomes and skip linear. I also like the exposure to handy R libraries, I am aware of quite a few (this isn't my first rodeo) but I learned of some more from this tutorial which was great.
Disliked: Perhaps be explicit about the goals for the data analysis of the breast cancer dataset, that way the reader gets emotionally engaged in the analysis. I didn't realise till after looking at the source link that the measurements were from fine-needle biopsies of breast lesions, and the measurements were of cell nucleus radius, (I thought originally it might have been referring to tumour radius in mm). And that the goals were from the cell data from the fine needle aspiration we need to predict whether the patient has breast cancer or not. I appreciate you don't want the tutorial to be too long but perhaps using the cross table to show the positive predictive value or sensitivity and specificity and how increasing the number of clusters could improve the diagnostic accuracy.
May 2022
4 stars:
Liked: Easy to understand
Disliked: Pls provide dataset so that we can practice alongside
Questions:
 Open image in new tab
Open image in new tabOpen image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab