Adding file-sources to Galaxy
Under Development!
This tutorial is not in its final state. The content may change a lot in the next months. Because of this status, it is also not listed in the topic pages.
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to set up an S3 bucket
Add your S3 bucket on Galaxy
Time estimation: 15 minutesSupporting Materials:
Published: Jan 20, 2025Last modification: Jan 20, 2025License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00529version Revision: 1
This tutorial demonstrates how to implement an S3 bucket as a Galaxy file-source within Galaxy. We will add here the public Argo data Amazon S3 bucket. Argo is an international program that observes the interior of the ocean with a fleet of profiling floats drifting in the deep ocean currents (https://argo.ucsd.edu). It started 20 years ago and is a dataset of 5 billion in situ ocean observations from 18.000 profiling floats (4.000 active). The Argo GDAC dataset is a collection of 18.000 NetCDF files. It is a major asset for ocean and climate science and a contributor to IOCCP reports.
AgendaIn this tutorial, we will cover:
Find the information you need
Hands On: Find an S3 bucketGo on Amazon Sustainability Data Initiative.
There you can visit the catalog of data, and by searching for Argo you can directly get to the Argo registry.
On this last page you’ll find all the information you’ll need to add the S3 bucket to Galaxy
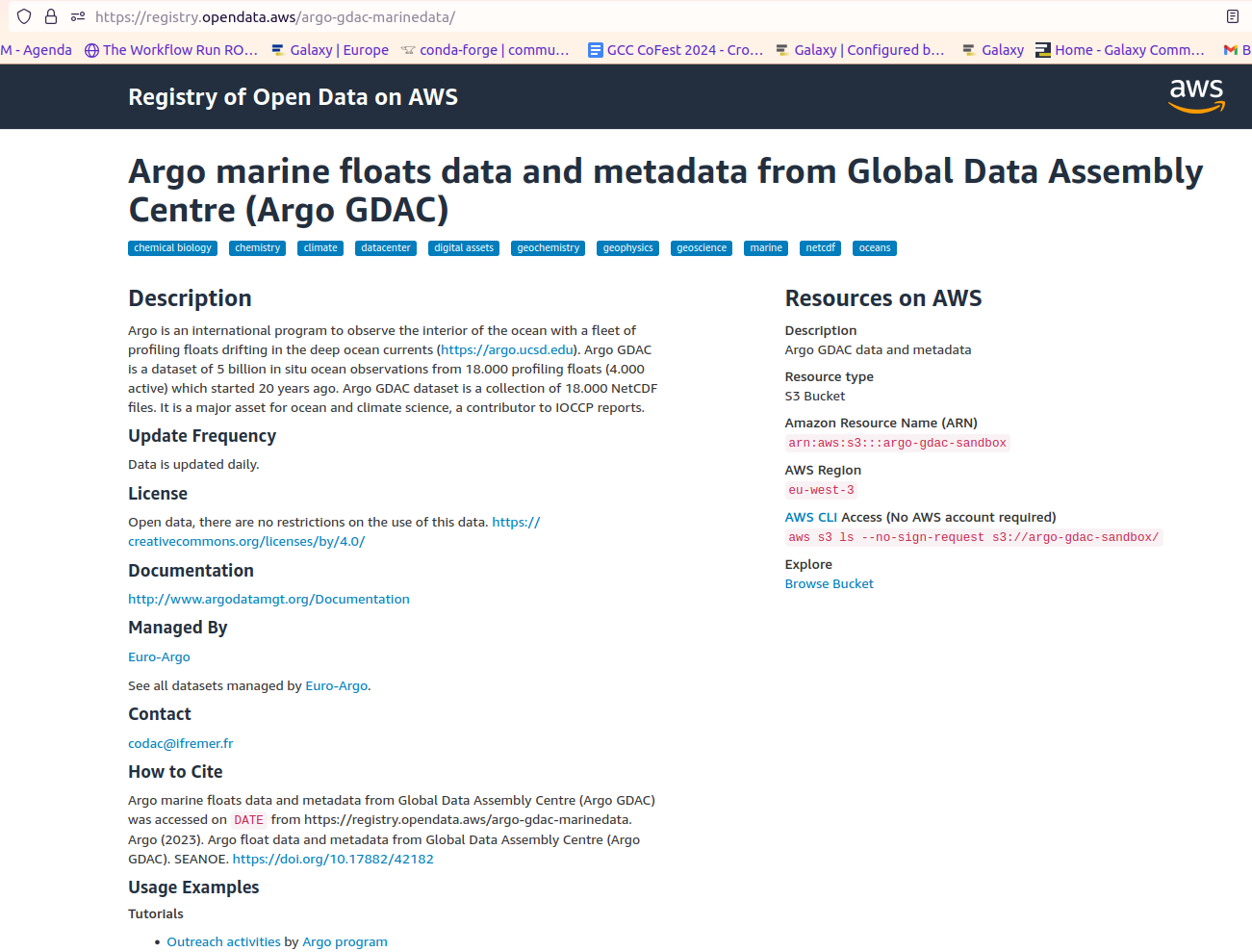
Add the S3 bucket
Hands On: Add on Galaxy
- If not already done clone the Galaxy Europe Infrastructure-playbook repo
- Create a branch on your fork
- Go to the file file_sources_conf.yml.j2 in templates/galaxy/config/
There you can edit the file and add your S3 bucket by adding a Argo specific section, like in the following:
- type: s3fs label: Argo marine floats data and metadata from Global Data Assembly Centre (Argo GDAC) id: argo-gdac-sandbox doc: Argo is an international program to observe the interior of the ocean with a fleet of profiling floats drifting in the deep ocean currents (https://argo.ucsd.edu). bucket: argo-gdac-sandbox anon: true
Finally, commit your changes and write a nice message for the admin when you open your Pull Request.
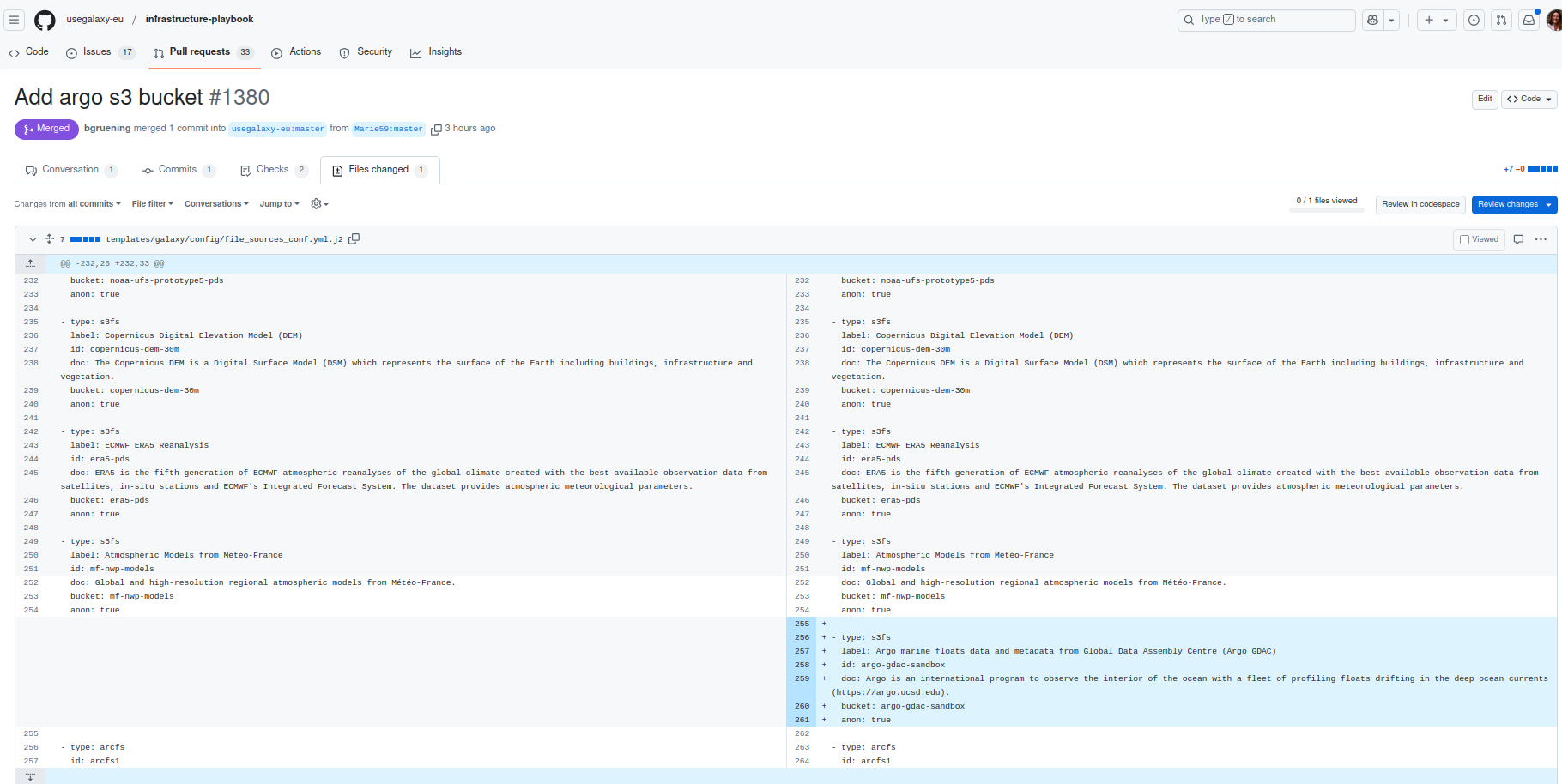
Conclusion
Here you are all set and once your Pull Request is merged you’ll soon be able to see your bucket in upload data, Choose remote files, and then search for your bucket label !
You've Finished the Tutorial
Key points
S3 bucket in as a data library
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsFeedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Marie Josse, Adding file-sources to Galaxy (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/admin/tutorials/file_sources/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{admin-file_sources, author = "Marie Josse", title = "Adding file-sources to Galaxy (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/admin/tutorials/file_sources/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }