Jupyterlab is a popular integrated development environment (IDE) for a variety of tasks in data science such as prototyping analyses, creating meaningful plots, data manipulation and preprocessing. Python is one of the most used languages in such an environment. Given the usefulness of Jupyterlab, more importantly in online platforms, a robust Jupyterlab notebook application has been developed that is powered by GPU acceleration and contains numerous packages such as Pandas, Numpy, Scipy, Scikit-learn, Tensorflow, ONNX to support modern data science projects. It has been developed as an interactive Galaxy tool that runs on an isolated docker container. The docker container has been built using nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu20.04 as the base container. Moreover, a Galaxy tool ( run_jupyter_job) can be executed using Bioblend which uses Galaxy’s remote job handling for long-running machine learning and deep learning training. The training happens remotely on a Galaxy cluster and the outcome datasets such as the trained models, tabular files and so on are saved in a Galaxy history for further use.
Jupyterlab notebook has been augmented with several useful features and together they make it ready-to-use for quick prototyping and end-to-end artificial intelligence (AI) projects. Being able to serve online makes it convenient to share it with other researchers and users. Its features can be broadly classified into two categories - features that have been added solely as Python packages and those that have been added also as Python packages but have their respective user interfaces. We will briefly discuss these features and later, we will use some of those for building and using AI models.
Features (Python packages)
Accessibility to many features has been made possible by adding several compatible Python packages, the most prominent ones are Bioblend, CUDA and ONNX. Using Bioblend the notebook can be connected to Galaxy and its histories, tools and workflows can be accessed and operated using various commands from the notebook. GPUs have accelerated AI research, especially deep learning. Therefore, the backend of the Jupyterlab is powered by GPU to make long-running AI training programs finish faster by parallelizing matrix multiplications. CUDA acts as a bridge between GPU and AI algorithms. In addition, a standard AI model format, open neural network exchange (ONNX), has been supported in the notebook to transform Scikit-learn and Tensorflow models to onnx files. These model files can be conveniently shared and used for inference. Galaxy also supports onnx file format which makes it easier to interoperate such models from a notebook to Galaxy and vice-versa. Galaxy tool for remote training can also run on GPU. There are several additional packages, suited for performing machine learning tasks such as Scikit-learn and Tensorflow for developing AI algorithms, Open-CV and Scikit-Image for image processing, NiBabel package for processing images files have been made available to researchers.
Features (Python packages with user interfaces)
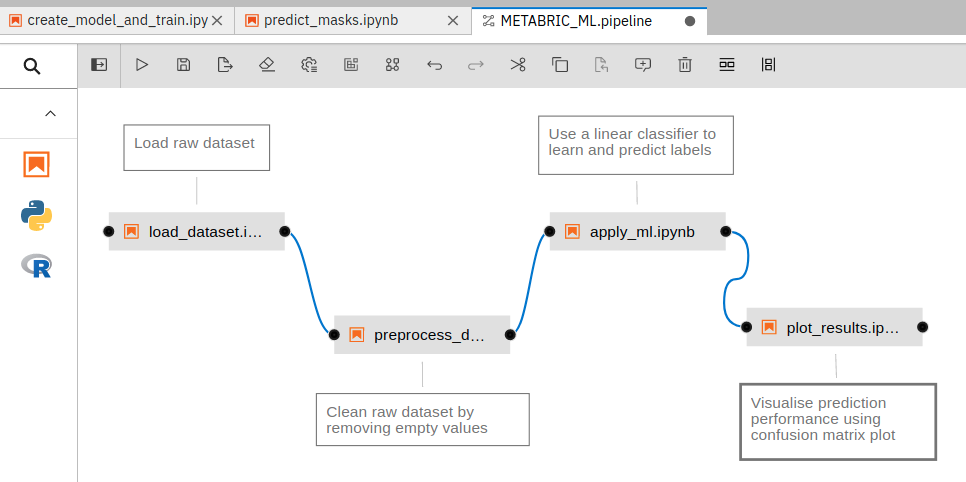
There are other features, added as Python packages, that have user interface components. These include GPU utilization dashboards for monitoring the GPU usage and system memory utilization, Voila for rendering output cells of a notebook in a separate tab hiding all code cells, interactive Bqplots for plotting, Git version control to clone, commit and maintain codebase directly from the notebook and Elyra AI pipelines for knitting together multiple notebooks to create a workflow. Many notebooks are created for processing datasets in different ways. These notebooks can be knit together to form one pipeline where each notebook transforms datasets taking a different form of data from its previous notebook and passing on the transformed datasets to its next notebook. An example workflow created using Elyra AI can be found by the name “METABRIC_ML.pipeline” in the “elyra” folder of a typical Jupyterlab instance. These pipelines can also be executed remotely on multiple “runtimes” supported by docker containers. An example pipeline created in the notebook can be seen in Figure 1. These features, integrated into the Jupyterlab notebook, are useful for the efficient execution and management of data science projects.
Figure 1: An example ML pipeline created using Elyra AI in a notebook. Each connected block of the pipeline is a different notebook
In the following sections, we will look at two examples of machine learning analyses - image segmentation and prediction of 3D structure of protein sequences. We will go through each step of how to perform such analyses in this Jupyterlab notebook.
Image segmentation
In an image classification task, a label is assigned to each image. For example, an image containing a cat gets a label as “cat” (“cat” is given an integer to be used in a machine learning program). But, in an image segmentation task, each pixel of an image gets a label. For example, in an image containing a cat, all the pixels occupied by the cat in the image are denoted by violet color (see Figure 2). More information can be found in the image segmentation tutorial. Image segmentation is a widely used technique in many fields such as medical imaging to find out abnormal regions in images of tissues, self-driving cars to detect different objects on highways and many more.
Figure 2: Image segmentation for cat. The violet region of the middle plot denotes the cat and the outline of the violet section denoted by the yellow color is the cat's mask
COVID CT scan
Segmenting lung CT scans task to locate infected regions has been actively proposed to augment the RT-PCR testing for initial screening of COVID infection in humans. Deep learning has been used to predict these regions with high accuracy in studies such as Fan 2020, Wu 2021 and many more. In Figure 3, the differences between the CT scans of a normal person and a person suffering from COVID-19 can be seen. The regions of the lungs marked by white patches are infected as discussed in Saeedizadeh 2021.
Figure 3: (Left) Lungs CT scan for a normal person and (right) lungs CT scan for a person having COVID-19
CT scans and masks
Figure 4 shows CT scans of infected lungs (top row) and borders around the infected regions have been drawn with red color (middle row). In the last row respective masks, from the CT scans, have been taken out denoting the infected regions. These masks are the “segmented” regions from the corresponding CT scans. While creating a dataset for training the deep learning model, Unet (briefly discussed in the following section), the CT scans are the data points and its “known” respective masks of infected regions become their labels (Saeedizadeh 2021).
Figure 4: Picture shows CT scans and their masks of infected regions that are drawn with red color in middle row plots
Unet neural network
Unet neural network is widely used for segmentation tasks in images (Ronneberger 2015). The name “Unet” resembles the shape of its architecture as “U” (see Figure 5). It has two parts - encoder and decoder. The left half of the “U” shape is the encoder that learns the feature representation (downsampling) at a lower level. The right half is the decoder that maps the low-resolution feature representation on the higher resolution (upsampling) pixel space.
Figure 5: Architecture of Unet neural network for image segmentation. The name "Unet" resembles the shape of its architecture as 'U'
In this tutorial, we will use the dataset of CTs scans and their respective masks to train an Unet neural network model. The model learns to map the infected regions in the CT scans to their masks. For prediction, the trained model is given unseen CT scans and for each CT scan, it predicts infected regions or masks. For this experiment, we will use Jupyterlab for cloning the notebooks from Github that contain scripts for downloading data, creating and training Unet model and prediction tasks. Data (CT scans and also the trained model) required for the notebooks can be downloaded from Zenodo (Kumar 2022). The model can either be trained in Jupyterlab or can be sent to Galaxy’s cluster for remote processing. After remote processing, the created datasets such as the trained model become available in new Galaxy history.
Protein 3D structure
Understanding the structure of proteins provides insights into their functions. But, only a few proteins have known structures out of billions of known proteins. To advance in the direction of predicting their 3D structures only from their sequences, AlphaFold2 (Jumper 2021) has made a breakthrough to predict their structures with high accuracy. However, the databases that it uses are large, approximately 2 terabytes (TB), and are hard to store and manage. Therefore, to make it more accessible, a few approaches such as ColabFold (Mirdita 2022), have been developed that consume significantly less memory, much faster and produce 3D structures with similar accuracy. We will look at, in later sections, how we can use ColabFold to predict 3D structure of a protein sequence using the Jupyterlab infrastructure in Galaxy.
Reproduce results from recent publications
First, we will discuss a few features of Jupyterlab to create and train a Unet deep learning model and then, predict segmented regions in COVID CT scans using the trained Unet model (Saeedizadeh 2021). In addition, we will predict 3D structure of protein sequence using ColabFold (Mirdita 2022), a faster implementation of AlphaFold2. First, let’s start the Jupyterlab instance on Galaxy Europe. The interactive tool can be found by searching “GPU enabled Interactive Jupyter Notebook for Machine Learning” name in the tool search.
Open Jupyterlab
Hands On: GPU enabled Interactive Jupyter Notebook for Machine Learning
GPU enabled Interactive Jupyter Notebook for Machine Learning
“Do you already have a notebook?”: Start with default notebooks
Click “Run Tool”
Now, we should wait for a few minutes until Galaxy creates the required compute environment for opening a new Jupyterlab. Usually, this task takes around 10-15 minutes. The progress can be checked by clicking on the “User>Active Interactive tools”. On “Active Interactive Tools” page, there is a list of all open interactive tools. When the job info shows “running” on the “Active Interactive Tools” page, then the name of the interactive tool gets associated with a URL to the running Jupyterlab. On clicking this URL, the running Jupyterlab can be opened. Several features of Jupyterlab running in Galaxy can be learned by going through the “home_page.ipynb” notebook. The folder “notebooks” contain several notebooks that show multiple use-cases of features and packages. Now, let’s download the necessary notebooks from Github for performing image segmentation and predicting 3D structure of protein sequences.
Clone Github repository
To use Git version control for cloning any codebase from GitHub, the following steps should be performed. Alternatively, the notebooks that showcase different usecases are also available by default at <<root>>/usecases/.
Hands On: Pull code
Create a new folder named covid_ct_segmentation alongside other folders such as “data”, “outputs”, “elyra” or you can use your favourite folder name.
Inside the created folder, clone a code repository by clicking on “Git” icon as shown in Figure 6.
In the shown popup, provide the repository path as shown below and then, click on “clone”:
The repository “anuprulez/gpu_jupyterlab_ct_image_segmentation” gets immediately cloned.
Move inside the created folder gpu_jupyterlab_ct_image_segmentation. A few notebooks can be found inside that are numbered.
Open image in new tab
Figure 6: Clone a code repository using Git
Now, we have all the notebooks available for performing image segmentation and predicting 3D structures of protein sequences. The entire analysis of image segmentation can be completed in two ways - first by running 3 notebooks (numbered as 1, 2 and 3) in the Jupyterlab itself and second by using 4, 5 and 6 notebooks that start remote training on Galaxy cluster invoking another Galaxy tool from one of the notebooks. First, let’s look at how we can run this analysis in the notebook itself.
Use-case 1: Run image segmentation analysis
Run notebooks in Jupyterlab
Hands On: Run notebooks in Jupyterlab
Download and save datasets in the notebook using “1_fetch_datasets.ipynb” notebook. It creates all the necessary folders and then, downloads two datasets - one “h5” file containing many matrices as sub-datasets belonging to training data, training labels, validation data, validation labels, test data and test labels.
Comment
Sub-datasets are stored as different variables after reading the original h5 file once. For training, we only need these datasets/matrices - training data, training labels, validation data and validation labels. The matrices, test data and test labels, are used only for prediction. We use h5 format for storing and retrieving datasets as all AI algorithms need input datasets in the form of matrices. Since, in the field of AI, there are many different types of datasets such as images, sequences, real numbers and so on, therefore, to converge all these different forms of datasets into one format, we use h5 to store matrices. In any AI analysis, different forms of datasets can be stored as h5 files. Therefore, for the image segmentation task, all the input datasets/matrices to the deep learning model are saved as sub-datasets in one h5 file so that they can be easily created, stored, downloaded and used. This step may take a few minutes as it downloads around 450 MB of data from Zenodo (Kumar 2022). Once these datasets are downloaded to the notebook, we can move to the next step to create a deep learning model and start training it.
Create and train a deep learning Unet model using “2_create_model_and_train.ipynb” notebook. This will read the input h5 dataset containing all images and train the model after creating deep learning model architecture.
Comment
This notebook first creates a deep learning architecture based on Unet including custom loss functions such as total variation and binary cross-entropy losses. After creating the deep learning architecture, all training datasets such as training data, training labels, validation data, validation labels are loaded from the combined h5 file. In the next step, all the datasets and deep learning architecture are compiled together and training starts for 10 epochs (10 iterations over the entire training dataset). The training is fast as it runs on GPU and finishes in a few minutes and creates a trained model. In the last step, the trained model containing several files is converted to one onnx file. Once a trained model is ready, we can move to the next step to make predictions on unseen CT scan masks.
Predict unseen masks using the trained model in “3_predict_masks.ipynb” notebook.
Comment
First, it reads test datasets from the combined “h5” file and then, loads the onnx model. Using this model, it predicts masks of unseen CT scans and then plots the ground truth and predicted masks in one plot (see Figure 7)
Figure 7: Ground truth and predicted masks of COVID CT scans. Predicted masks in the third and fourth columns (computed using slightly different loss functions) are very close to the corresponding original masks in the second column
Figure 7 shows original lungs CT scans in the first column. The second column shows the corresponding true infected regions in white. The third and fourth columns show the infected regions predicted with different loss functions, one is the binary cross-entropy loss and another is the combination of binary cross-entropy loss and total variation loss. Binary cross-entropy calculates loss between two corresponding pixels of true and predicted images. It measures how close the two corresponding pixels are. But, total variation loss measures the amount of noise in predicted images as noisy regions usually show large variations in their neighbourhood. The noise in the predicted images gets minimized and the connectivity of predicted masks improves as well when minimizing this loss.
Run Jupyterlab notebooks remotely on a Galaxy cluster
The training task completed in the notebook above can also be sent to a Galaxy cluster by executing a Galaxy tool in the notebook itself. Using Bioblend APIs, datasets in the form of h5 files and notebook are uploaded to a Galaxy history and then a Galaxy tool run_jupyter_job executes the notebook using the uploaded dataset on a Galaxy cluster and creates a trained model in the Galaxy history. Let’s look at how to execute a notebook remotely on a Galaxy cluster.
Hands On: Run Jupyterlab notebooks remotely on a Galaxy cluster
Download and save datasets in the notebook using “1_fetch_datasets.ipynb” notebook in the same way as before. Ignore this step if this notebook has already been executed.
Execute “5_run_remote_training.ipynb” notebook to dynamically execute code inside “4_create_model_and_train_remote.ipynb” notebook on a remote cluster using a different Galaxy tool (run_jupyter_job). The notebook “5_run_remote_training.ipynb” provides the path of a notebook to be executed remotely along with the datasets to the Galaxy tool by calling a custom function run_script_job which is part of the Jupyterlab notebook.
Comment
Executing “5_run_remote_training.ipynb” uploads datasets and dynamic Python script, extracted from the “4_create_model_and_train_remote.ipynb” notebook, to a newly created Galaxy history (Figure 8). When the task of uploading dataset and dynamic code is finished, the Galaxy tool (run_jupyter_job) executes the dynamically uploaded script with the uploaded dataset on a remote Galaxy cluster which is similar to running any other Galaxy tool. When the Galaxy tool (run_jupyter_job) finishes its execution, the resulting models and other datasets appear in the created Galaxy history. While the job is running on the Galaxy cluster, the Jupyter notebook can be closed as the model training task gets decoupled from the notebook and is entirely transferred to the Galaxy cluster. Specific history used for this job can be accessed in Galaxy. The Jupyterlab method run_script_job has multiple input parameters - script_path: relative path to the script that is to be executed remotely, data_dict: list of input datasets as h5 files, server: Galaxy server URL, key: Galaxy API key and new_history_name: the name of the Galaxy history that is created).
Figure 8: Galaxy history showing finished datasets after remote training on a Galaxy cluster
Note: The training may take longer depending on how busy Galaxy’s queueing is as it sends the training task to be done on a Galaxy cluster. Therefore, this feature should be used when the training task is expected to run for several hours. The training time is higher because a large Docker container is downloaded on the assigned cluster and only then, the training task can proceed.
When the Galaxy job finishes, it creates a history having a few datasets such as input h5 dataset, dynamic Python script extracted from the notebook, a trained model saved as onnx file, all saved lists and NumPy arrays and a zipped file containing all the intermediate files created and saved in the dynamic script. One such example of a Galaxy history is available. Datasets from this history can be downloaded into the Jupyterlab notebook and further analyses can be performed. Using the notebook “6_predict_masks_remote_model.ipynb”, the trained model can be downloaded from the newly created Galaxy history to Jupyterlab notebook and then, it can be used to make predictions of unseen CT scan masks in the same way as shown in “3_predict_masks.ipynb” notebook.
Use-case 2: Run ColabFold to predict 3D structure of protein
Google Deepmind’s AlphaFold2 has made a breakthrough in predicting the 3D structure of proteins with outstanding accuracy. However, due to their large database size (a few TB), it is not easily accessible to researchers. Therefore, a few approaches have been developed that replace the time-consuming steps of AlphaFold2 with slightly different steps to create input features and predict the 3D structure with comparable accuracy as AlphaFold2. One such approach is ColabFold which replaces the large database search in AlphaFold2 for finding homologous sequences by a significantly faster MMseqs2 API call to generate input features based on the query protein sequence. ColabFold is approximately 16 times faster than AlphaFold2 in predicting 3D structures of protein sequences. To make it accessible in this Jupyterlab, it has been integrated into the Docker container by having two additional packages - ColabFold and the GPU enabled JAX which is just-in-time compiler from Google used for mathematical transformations. In the following hands-on section, we will run a notebook and predict a 3D structure of a protein sequence.
Hands On: Predict 3D structure of protein using ColabFold
Clone a Github repository by following the steps described in the previous hands-on section Clone Github repository. Ignore this step if already done.
Open 7_ColabFold_MMseq2.ipynb notebook and execute it.
It needs a few minutes (around 5-10 minutes) to download AlphaFold2 weights (of size approximately 4 GB) and uses these weights for prediction. An example prediction is shown in figure 9.
Figure 9: 3D structure of a protein sequence of length 300 with side-chains predicted by ColabFold
Docker’s security
For remote training, a dynamic Python script is sent to a Galaxy tool for execution on a Galaxy cluster that may pose security risks of containing malicious code. To minimize the security risks that come along with executing dynamic Python scripts, the Galaxy tool run_jupyter_job is executed inside a Docker container. It is the same container inside which the Jupyterlab notebook runs. All the packages available inside the notebook are also available for the Galaxy tool. Programs run in isolated environments inside Docker containers and have their connections limited to necessary libraries, and network connections. Due to these restrictions, they have a reduced number of interactions with the host operating system.
GPU Juyterlab tool in a Galaxy workflow
Introduction
In addition to an interactive mode that opens a Jupyterlab in Galaxy, the GPU Jupyterlab tool can also be used as a tool in a Galaxy workflow. In this mode, it takes input datasets from a different tool along with an ipynb notebook file. It executes the ipynb file along with the input datasets and produces output datasets inside a dataset collection. This output dataset collection can then be used with other Galaxy tools. This feature enables it to be used in a Galaxy workflow like other Galaxy tools.
Execute an existing notebook
In this mode, the GPU Jupyterlab tool executes the input ipynb file and produces output datasets (in a collection) if created in the notebook file. Input datasets can also be attached to the notebook which become available at /galaxy_inputs/<<Name for parameter>> folder. The parameter Name for parameter is set for each input dataset that is used as the folder name inside /galaxy_inputs/. More than one input datasets can be attached to the notebook. Another feature Execute notebook and return a new one controls whether webfrontend becomes available showing Jupyterlab or a notebook is just executed. When this parameter is set to yes, then the attached notebook is executed and output datasets if any become available in an output dataset collection. When this parameter is set to no (by default), then Jupyterlab infrastructure as a webfrontend is opened along with the attached notebook and input datasets if attached.
Run as a tool in workflow
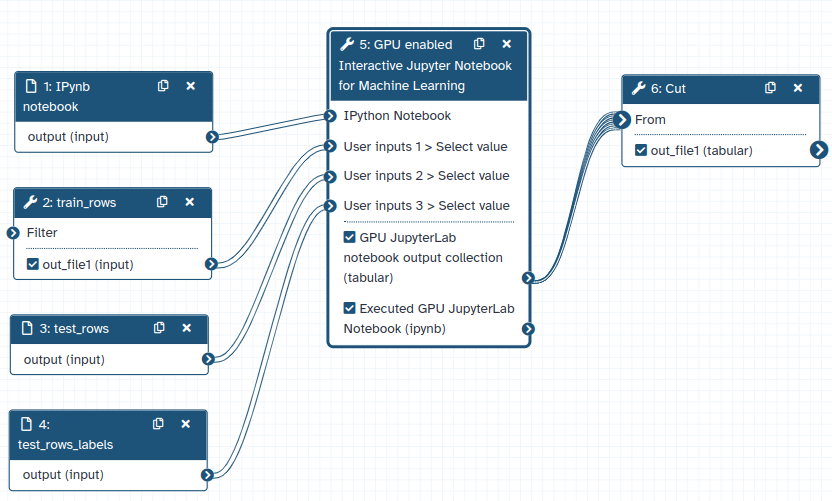
When the parameter Execute notebook and return a new one is set to yes, the GPU Jupyterlab tool can be used as a part of any workflow. In this mode, it requires an ipynb file/notebook that gets executed in Galaxy and output datasets if any become available in the Galaxy history. Along with a notebook, multiple input datasets can also be attached that become automatically available inside the notebook. They can be accessed inside the notebook and processed to produce desired output datasets. These output datasets can further be used with other Galaxy tools. The following image shows a sample workflow for illustration purposes. Similarly, high-quality workflows to analyse scientific datasets can be created.
Figure 10: A sample Galaxy workflow that uses GPU Jupyterlab as a tool which takes input datasets from one tool, trains a machine learning model to predict classes and then the predicted datasets is used as input to another Galaxy tool.
Let’s look at how can this workflow be created in a step-wise manner. There are 3 steps - first, the training dataset is filtered using the Filter tool. The output of this tool along with 2 other datasets (test_rows and test_rows_labels), a sample IPython notebook is executed by the GPU Jupyterlab tool. The sample IPython notebook trains a simple machine learning model using the train dataset and creates a classification model using RandomForestClassifier. The trained model is then used to predict classes using the test dataset. The predicted classes is produced as a file in an output collection by the GPU Jupyterlab tool. As a last step, Cut tool is used to extract the first column of the output collection. Together, these steps showcase how the GPU Jupyterlab tool is used with other Galaxy tools in a workflow.
Get data
Datasets such as train, test and sample IPython (ipynb) notebook files are downloaded from Zenodo to import them into a Galaxy history.
Hands On: Data upload
Make sure you have an empty analysis history.
To create a new history simply click the new-history icon at the top of the history panel:
Rename your history to make it easy to recognize
Click on the title of the history (by default the title is Unnamed history)
Click galaxy-uploadUpload at the top of the activity panel
Select galaxy-wf-editPaste/Fetch Data
Paste the link(s) into the text field
Press Start
Close the window
Rename the datasets as test_rows, train_rows and test_rows_labels respectively.
Click on the galaxy-pencilpencil icon for the dataset to edit its attributes
In the central panel, change the Name field
Click the Save button
Check that the datatype of all three tabular datasets is csv.
Click on the galaxy-pencilpencil icon for the dataset to edit its attributes
In the central panel, click galaxy-chart-select-dataDatatypes tab on the top
In the galaxy-chart-select-dataAssign Datatype, select datatypes from “New Type” dropdown
Tip: you can start typing the datatype into the field to filter the dropdown menu
Click the Save button
Filter training dataset
This tool showcases how a tool prior to using the GPU Jupyterlab tool (in a workflow) can be used and how its output can be used as input to the GPU Jupyterlab tool.
Hands On: Filter
Filter
“Filter *” : Select train_rows
“With following condition” :c3==0
“Number of header lines to skip”: 1
Click “Run Tool”
Rename the filtered dataset as new_train_rows which will be used as one of the inputs to the GPU Jupyterlab tool in the next step. The datatype should be tabular.
Execute IPython notebook using GPU Jupyterlab tool
This tool showcases GPU Jupyterlab tool that executes a notebook using input datasets produced by different tools. Galaxy tool like features for this interactive tool has been adapted from another interactive Galaxy tool Interactive JupyTool and notebook.
Hands On: GPU Jupyterlab tool
GPU Jupyterlab tool
“Do you already have a notebook?” : Select Load an existing notebook
“IPython Notebook” : Select sample_notebook.ipynb
“Execute notebook and return a new one”: Yes
In “User inputs”:
param-repeat“1: User inputs”
“Name for parameter”: train
“Choose the input type”: Dataset
“Select value”: Select new_train_rows
param-repeat“2: User inputs”
“Name for parameter”: test
“Choose the input type”: Dataset
“Select value”: Select test_rows
param-repeat“3: User inputs”
“Name for parameter”: testlabels
“Choose the input type”: Dataset
“Select value”: Select test_rows_labels
Cut a column from the output collection
This tool showcases how the output dataset collection produced by the GPU Jupyterlab tool can be used by a different Galaxy tool.
The above tool extracts the first column from dataset residing in the output dataset collection. All three steps explained above show how the GPU Jupyterlab tool can be used with other Galaxy tools to create a workflow.
Conclusion
In this tutorial, we have discussed several features of the Jupyterlab notebook in Galaxy and used a few of them to perform an image segmentation task on COVID CT scans by training Unet, a deep learning model. In addition, we have used it for predicting 3D structure of a protein sequence which is a memory-intensive and time-consuming task. The ready-to-use infrastructure that we employed here for developing an AI algorithm and training a model shows that it is convenient for creating quick prototypes and end-to-end projects, accelerated by GPU, in the data science field without caring much about the storage and compute resources.
The possibility of remote execution of long-running training tasks obviates keeping the notebook or computer open till the training finishes and at the same time, the datasets and models stay safe in Galaxy history. The usage of h5 files for input datasets to AI algorithms solves the problem of varying data formats across multiple fields that are used extensively for predictive tasks. Using onnx for creating, storing and sharing an AI model makes it easier to handle such it as one compact file. Git integration makes it easy to maintain an entire code repository directly in the notebook. The entire environment can be shared with other researchers only via sharing the URL of the Jupyterlab. Bioblend connects this infrastructure to Galaxy which makes its histories, workflows and tools accessible directly via the notebook. Overall, this infrastructure would prove useful for researchers having little access to large compute resources to develop and manage quick prototypes and end-to-end data science projects.
Feature to use GPU Jupyterlab as a regular Galaxy tool provides an ability to execute IPython notebooks in a workflow. The executed notebook is also available in the Galaxy history with the associated cell outputs.
You've Finished the Tutorial
Please also consider filling out the Feedback Form as well!
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channels
Ronneberger, O. et al., 2015 U-Net: Convolutional Networks for Biomedical Image Segmentation. CoRR.
Fan, D. et al., 2020 Inf-Net: Automatic COVID-19 Lung Infection Segmentation From CT Images. IEEE Transactions on Medical Imaging 39: 2626–2637. 10.1109/TMI.2020.2996645
Jumper, J. et al., 2021 Highly accurate protein structure prediction with AlphaFold. Nature 596(7873): 583–589. 10.1038/s41586-021-03819-2
Wu, Y. et al., 2021 JCS An Explainable COVID 19 Diagnosis System by Joint Classification and Segmentation. IEEE Transactions on Image Processing 30: 3113–3126. 10.1109/tip.2021.3058783
Kumar, A., 2022 COVID Image segmentation datasets and trained model. 10.5281/zenodo.6091361
Mirdita, M. et al., 2022 ColabFold - Making protein folding accessible to all. bioRxiv. 10.1101/2021.08.15.456425
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{statistics-gpu_jupyter_lab,
author = "Anup Kumar",
title = "A Docker-based interactive Jupyterlab powered by GPU for artificial intelligence in Galaxy (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/statistics/tutorials/gpu_jupyter_lab/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Funding
These individuals or organisations provided funding support for the development of this resource
Questions:
 Open image in new tab
Open image in new tab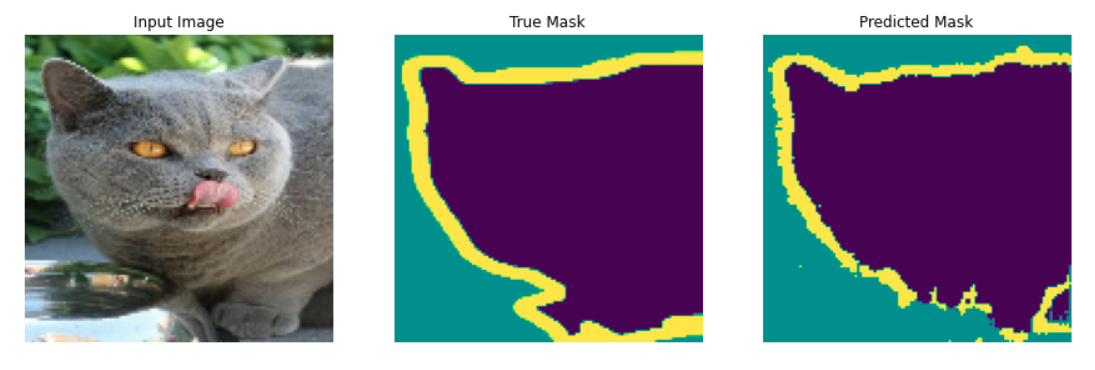 Open image in new tab
Open image in new tab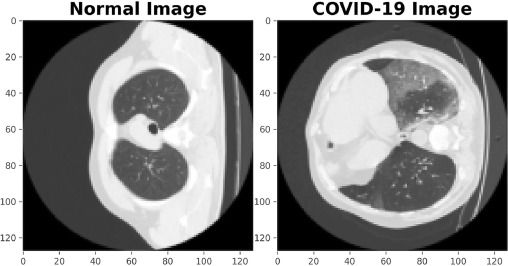 Open image in new tab
Open image in new tab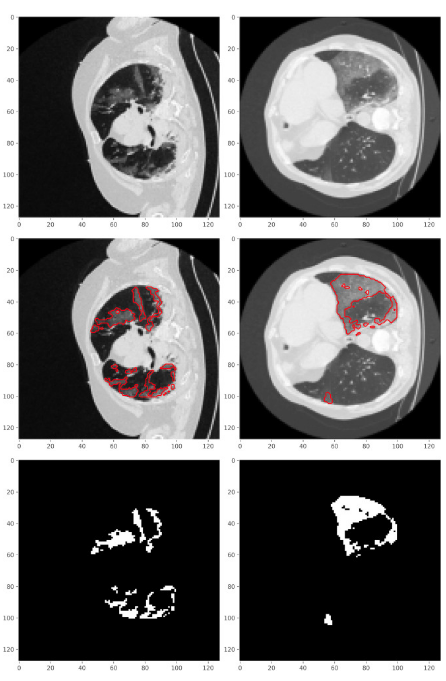 Open image in new tab
Open image in new tab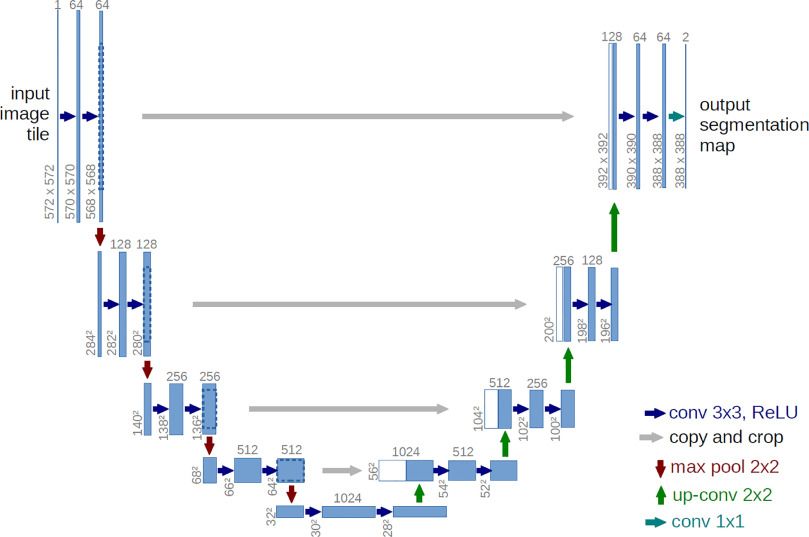 Open image in new tab
Open image in new tabOpen image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
 Open image in new tab
Open image in new tab