This tutorial is based on Hugo W, Shi H, Sun L, Piva M et al.: Non-genomic and Immune Evolution of Melanoma Acquiring MAPKi Resistance Hugo et al. 2015.
We will use a small subset of the original data. If we run the tutorial on the orginal dataset, analysis will be time consuming and not reproducible Infinium Human Methylation BeadChip computation on the orginal data can be found at case study.
Introduction
The field of cancer genomics has demonstrated the power of massively parallel sequencing techniques to inform on genes and specific alterations that drive tumor onset and progression. Although large comprehensive sequence data sets continue to be made increasingly available, data analysis remains an ongoing challenge, particularly for laboratories lacking dedicated resources and bioinformatics expertise. To address this, we have provided training based on Galaxy Infinium Human Methylation BeadChip tool that represents many popular algorithms for detecting somatic genetic alterations from genome and exome data.
Figure 1: How epigenetics mechanism can effect health (adapted from https://commonfund.nih.gov/epigenomics/figure)
This exercise uses datasets from the Cell publication by Hugo et al. 2015. with the goal being the identification of differentially methylated regions and positions associated with treatment resistant melanomas.
Datasets include the Infinium Human Methylation BeadChip array performed in melanoma tumors in a sample of patients pre and post MAPKi and BRAFi treatment with different outcomes (sensitive and resistant). For each sample there is raw green (methylated) and red (unmethylated) colour arrays containing the summarised bead information generated by the Infinium Human Methylation BeadChip scanner.
The Infinium Human Methylation BeadChip uses two different bead types to detect changes in DNA methylation levels. In the figure we can see M - methylated and U - unmethylated bead types. In our study unmethylated and methylated bead signals are reported as green and red colors respectively.
The workflow combines 5 main steps, starting with raw intensity data loading (.idat) and then optional preprocessing and normalisation of the data. The next quality control step performs an additional sample check to remove low-quality data, which normalisation cannot detect. The workflow gives the user the opportunity to perform any of these preparation and data cleaning steps, including a highly recommended genetic variation annotation step resulting in single nucleotide polymorphism identification and removal. Finally, the dataset generated through all of these steps can be used to hunt (find) differentially-methylated positions (DMP) and regions (DMR) with respect to a phenotype covariate.
Raw intensity data loading
The first step of the Infinium Human Methylation BeadChip array analysis is raw methylation data loading (intensity information files for each two colour micro array)
Hands On: Data Loading
Create a new history for this tutorial and give it a proper name
To create a new history simply click the new-history icon at the top of the history panel:
Import the following IDAT files from Zenodo or from the data library (ask your instructor)
Click galaxy-uploadUpload at the top of the activity panel
Select galaxy-wf-editPaste/Fetch Data
Paste the link(s) into the text field
Press Start
Close the window
As an alternative to uploading the data from a URL or your computer, the files may also have been made available from a shared data library:
Go into Libraries (left panel)
Navigate to the correct folder as indicated by your instructor.
On most Galaxies tutorial data will be provided in a folder named GTN - Material –> Topic Name -> Tutorial Name.
Select the desired files
Click on Add to Historygalaxy-dropdown near the top and select as Datasets from the dropdown menu
In the pop-up window, choose
“Select history”: the history you want to import the data to (or create a new one)
Click on Import
Comment: Phenotype table
Phenotype table can be in different sizes with different arguments, however the second column is required to contain phenotype covariate information for each sample.
Run UCSC Maintool to obtain the reference genome. The tool will take you to the UCSC table browser. Use the following parameters to extract the reference genome
Click on the get output button at the bottom of the screen
On the next page, click on the Send Query to Galaxy button
Wait for the upload to finish
After exporting the reference genome from UCSC, we need to make sure that it is in the right dataset build.
Click on the Differentially_Methylated_Positions.bed output in your history to expand it.
Set the database build of your dataset to Human Feb. 2009 (GRCh37/hg19) (hg19)(if it is not set automatically)
Click the desired dataset’s name to expand it.
Click on the “?” next to database indicator:
In the central panel, change the Database/Build field
Select your desired database key from the dropdown list: hg19
Click the Save button
Click on display at UCSC towards the bottom of the history item.
This will launch UCSC Genome Browser with your Custom Track
Figure 3: UCSC genome track showing differentialy methylated regions located on chromosome 6
.idat preprocessing
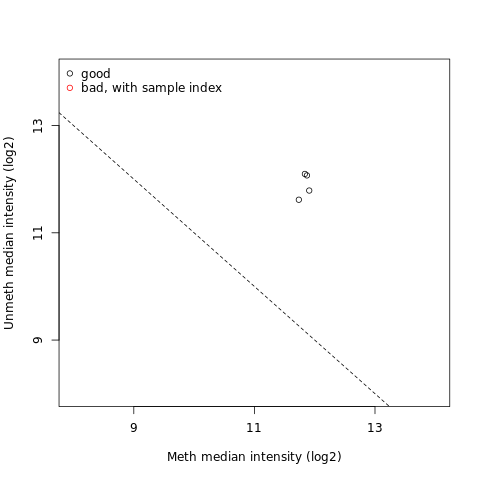
Preprocessing and data quality assurance is an important step in Infinium Methylation Assay analysis. Idat dataset represents two colour data with a green and a red channel and can be converted into methylated and unmethylated signals or into Beta values. The Infinium Human Methylation BeadChip tool extracts and plots the quality control data frame with two columns mMed and uMed which are the medians of methylation signals (Meth and Unmeth). Comparing them against one another allows users to detect and remove low-quality samples.
Comment: Normalisation of the data
If your files require normalisation, you might prefer to use one of the other preprocessing tools provided in Infinium Human Methylation BeadChip tool i.e. Preprocess Funnorm or Preprocess Quantile look for recommendation at Aryee et al. 2014.
Differentially methylated regions and positions analysis
The main goal of the Infinium Human Methylation BeadChip analysis is to simplify the way differentially methylated loci sites are detected. The Infinium Human Methylation BeadChip pipeline contains differentially methylated positions (DMPs) detection with respect to a phenotype covariate, and more complex solutions for finding differentially methylated regions (DMRs). Genomic regions that are differentially methylated between two conditions can be tracked using a bumphunting algorithm. The algorithm first implements a t-statistic at each methylated loci location, with optional smoothing, then groups probes into clusters with a maximum location gap and a cutoff size to refer the lowest possible value of genomic profile hunted by our tool.
Hands On: detecting methylated loci sites
Run Infinium Human Methylation BeadChip ( Galaxy version 2.1.0) with the following parameters to map the imported datasets against phenotype covariate and reference genome obtained from UCSC.
param-files“red channel files”: all files ending in _Red
param-files“green channel files”: all files ending in Grn
Ilumina methylation array data can be mapped to the genome with or without additional preprocessing methods. Incomplete annotation of genetic variations such as single nucleotide polymorphism (SNP) may affect DNA measurements and disrupt downstream analysis of results. Aryee et al. 2014 It is highly recommended to remove the probes that contain either an SNP at the methylated loci interrogation or at the single nucleotide extension. In this tutorial we will remove probes affected by genetic variation by selecting (Optional) Preprocessing Methodtool.
“(Optional) Preprocessing Method”: Remove SNPS
“Phenotype Table”:The phenotypeTable.txt file uploaded from Zenodo
“maxGap Size”:250
We will use the default gap of 250 base pairs (bps), i.e. any two points more than 250 bps away are put in a new cluster.
“Cutoff Size”:0.1
In order to find segments that are positive, near zero, and negative. We need a cutoff which is one number in which case “near zero” default 0.1
“Number of Resamples”:0
Default value 0 for permutation method apply selection of randomized cases with replacement from the original data while using ‘bootstrap’ method.
“nullMethod”:permutation
Method used to generate null candidate regions, must be one of ‘bootstrap’ or
‘permutation’ (defaults to ‘permutation’).
“Phenotype Type”:categorical
Identify regions where methylation is associated with a continuous or categorical phenotype.
“qCutoff Size”:0.5
Diffrentialy methylated positions with an FDR q-value greater than this value will not be returned.
“Variance Shrinkage”: TRUE
Default TRUE as it is recommended when sample sizes are small <10
“Genome Table”: wgEncodeHaibMethyl450 ...
Question
How do we define phenotype covariate?
Phenotype covariate is the set of observable characteristics of an individual resulting from the gene-environment interactions
Annotation and visualization
In addition to downstream analysis users can annotate the differentially methylated loci at the promoter regions of genes with gene function descriptions, and relationships between these concepts.
Hands On: Annotate Differentially Methylated Position
Run ChIPpeakAnno annoPeaks ( Galaxy version 0.1.0) on the output of Infinium Human Methylation BeadChip ( Galaxy version 2.1.0) with the following parameters
param-file“Differentialy methylated Positions”: output of Infinium Human Methylation BeadChip ( Galaxy version 2.1.0)
“bindingType”: StartSite
“bindingRegionStart”:-5000
“bindingRegionEnd”:3000
“Additional Column of Score”:5
Position of column of score optional value if it is required
Run Cut on the previous output adjusting the following parameters to cut “gene_name” column from table of annotated peaks and then get a list of genes
“Cut columns”: c16
“Delimited by”: Tab
param-file“From”: output of ChIPpeakAnno annoPeaks ( Galaxy version 0.1.0)
Use Remove beginning on Gene List with the following parameters
“Remove first”: 1
param-file“from”: output of Cut
Run Cluster Profiler Bitr ( Galaxy version 0.1.0) on the previous output adjusting the following parameters to convert the list of genes to list of entrez ID
“Input Type Gene ID”: SYMBOL
“Output Type Gene ID”: ENTREZID
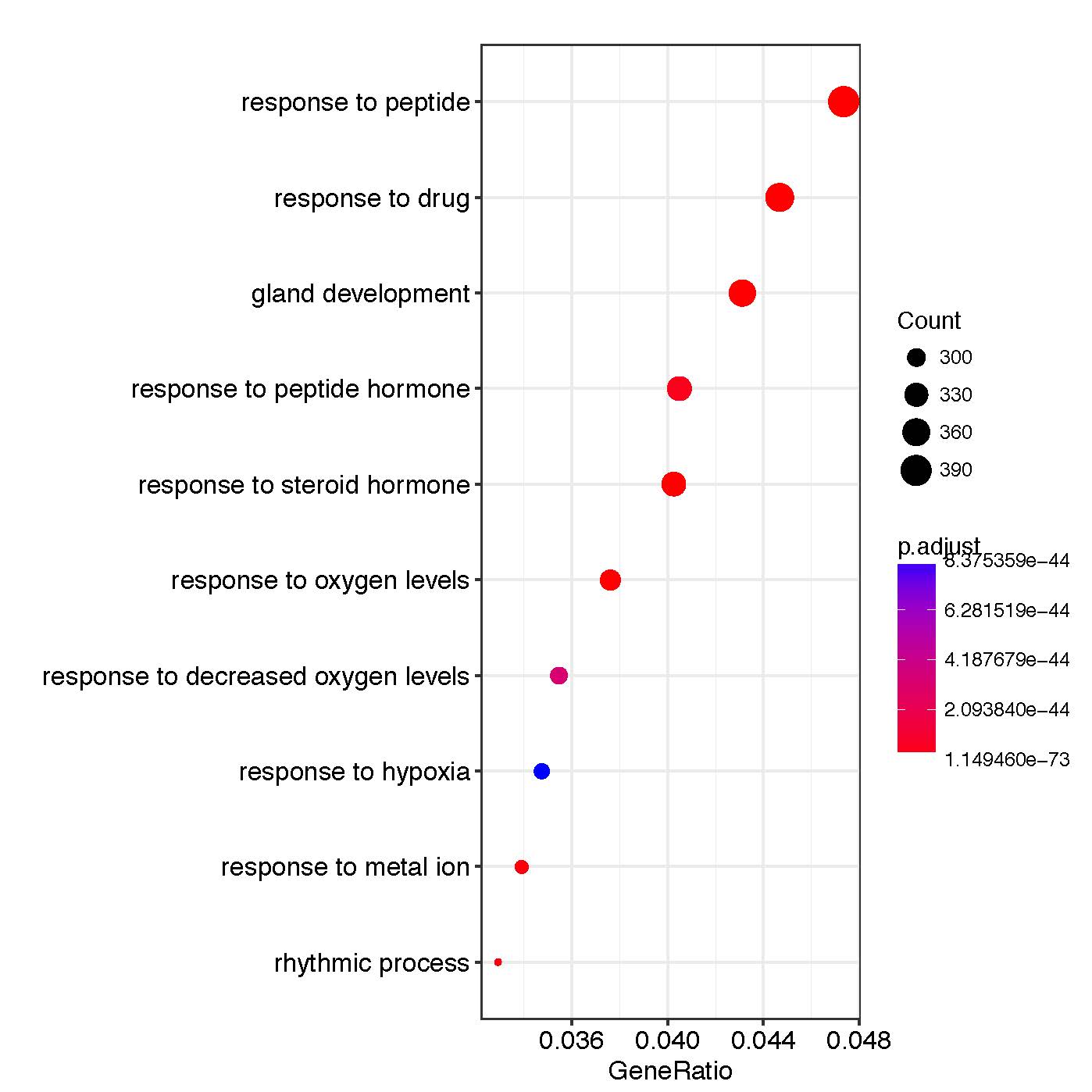
Run a GO Enrichment Analysis using clusterProfiler go ( Galaxy version 0.1.0) on the output of the Cluster Profiler Bitr ( Galaxy version 0.1.0)
Figure 4: Results of GO enrichments analysis for DMPs
ID
Description
pvalue
qvalue
geneID
Count
GO:0048732
gland development
1.38E-58
4.23E-55
PTGS2 / KCNC1 / FZD1 /SLC22A18 /SLC22A3 (…)
372
GO:1901652
response to peptide
3.99E-57
8.13E-54
SULF1/ LAMA5/ MED1 /CFLAR/ MSX2 (…)
359
GO:0048545
response to steroid hormone
1.38EE-54
2.11E-51
HDAC9/ RAB10/ CFLAR/ WDTC1 (…)
394
Conclusion
Epigenetic aberrations which involve DNA modifications give researchers an interest in identifying novel non-genetic factors responsible for complex human phenotypes such as height, weight, and disease. To identify methylation changes researchers need to perform complicated and time consuming computational analysis. Here, the EWAS suite becomes a solution for this inconvenience and provides a simplified downstream analysis available as a ready to run pipline in supplementary materials. For more details, see the associated publication Murat et al. 2020
You've Finished the Tutorial
Please also consider filling out the Feedback Form as well!
Key points
Infinium Human Methylation BeadChip is an array based technology to generate DNA methylation profiling at individual CpG loci in the human genome based on Illumina’s bead technology.
Time and cost efficiency followed by high sample output, and overall quantitative accuracy and reproducibility made Infinium Human Methylation BeadChip one of the most widely used arrays on the market.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channels
Aryee, M. J., A. E. Jaffe, H. Corrada-Bravo, C. Ladd-Acosta, A. P. Feinberg et al., 2014 Minfi: a flexible and comprehensive Bioconductor package for the analysis of Infinium DNA methylation microarrays. Bioinformatics 30: 1363–1369. 10.1093/bioinformatics/btu049
Hugo, W., H. Shi, L. Sun, M. Piva, C. Song et al., 2015 Non-genomic and Immune Evolution of Melanoma Acquiring MAPKi Resistance. Cell 162: 1271–1285. 10.1016/j.cell.2015.07.061
Murat, K., B. Grüning, P. W. Poterlowicz, G. Westgate, D. J. Tobin et al., 2020 Ewastools: Infinium Human Methylation BeadChip pipeline for population epigenetics integrated into Galaxy. GigaScience 9: 10.1093/gigascience/giaa049
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{epigenetics-ewas-suite,
author = "Katarzyna Kamieniecka and Khaled Jum'ah and Krzysztof Poterlowicz",
title = "Infinium Human Methylation BeadChip (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/epigenetics/tutorials/ewas-suite/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Funding
These individuals or organisations provided funding support for the development of this resource
Questions:
 Open image in new tab
Open image in new tab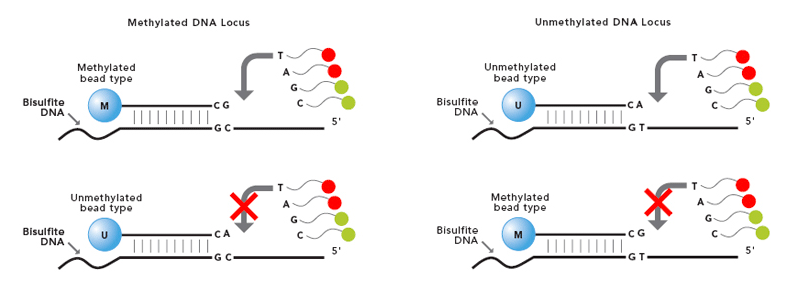 Open image in new tab
Open image in new tabOpen image in new tab


 Open image in new tab
Open image in new tab
