Classification in Machine Learning
Contributors
| Author(s) |
|
Questions
What is classification and how we can use classification techniques?
Objectives
Learn classification background
Learn what a quantitative structure-analysis relationship (QSAR) model is and how it can be constructed in Galaxy
Learn to apply logistic regression, k-nearest neighbors, support verctor machines, random forests and bagging algorithms
Learn how visualizations can be used to analyze the classification results
Requirements
last_modification Published: Mar 21, 2025
last_modification Last Updated: Apr 8, 2025
What is classification in machine learning?
Speaker Notes
What is classification in machine learning?
Classification
.pull-left[
- Class is a category
- Represented as an integer (0, 1, 2, 3 …)
- Known as categorical variables
- “Supervision” of classes
- Two class (binary) classification
- Cancer or no cancer, spam or no spam
- Multi-class classification
- Handwritten digit recognition ]
.pull-right[ 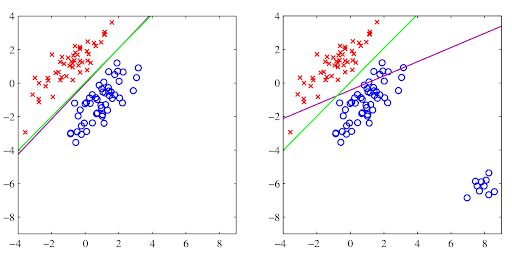 ]
]
Linear model
.pull-left[
- Input data point x (x1, x2)
- Weights w (w0, w1, w2)
- w0 is intercept
- w1, w2 are feature coefficients
- Function “y” is learned by a linear model
- Decision boundary: y(x) = 0
- If y(x) > 0, x is assigned to class C1
- If y(x) < 0, x is assigned to class C2 ]
.pull-right[ 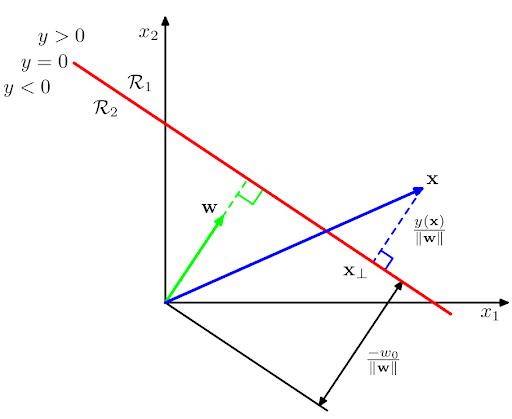 ]
]
Support vector machines
.pull-left[
- Linear and non-linear variants
- Learn decision boundary with maximum margin
- Support vectors are data points that lie closest to the decision boundary
- Need only support vectors for classifying new samples
- Other data points can be thrown away ]
.pull-right[ 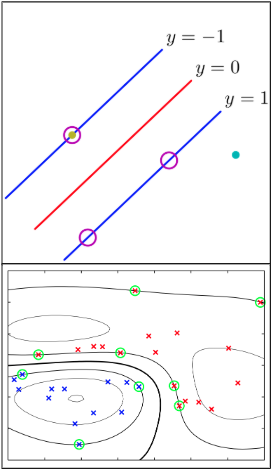 ]
]
Nearest neighbour
.pull-left[
- Find a certain number of neighbours
- Neighbours are closest based on a distance metric
- Distance metrics - Euclidean distance, Manhattan distance, …
- Class of a new sample is the class of the maximum number of its neighbours
- Example
- K-nearest neighbours - K is the predefined number of neighbours
- Stores training data
- Unsuitable for large datasets
- Learn even irregular boundaries ]
.pull-right[ 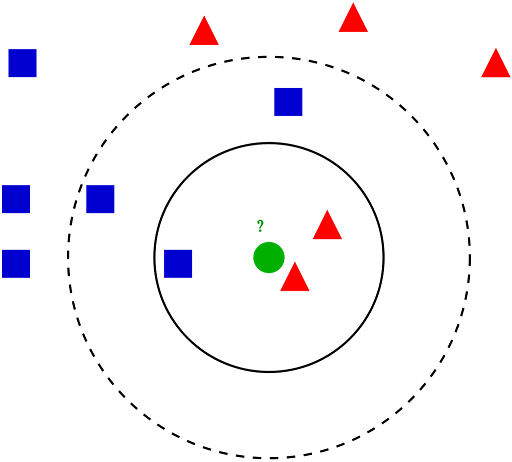 ]
]
Decision tree
.pull-left[
- Learn decision rules from features
- Split at each node (non-leaf) using feature values
- Contain labels at leaf nodes
- Advantages:
- Easy to understand
- Can be used with categorical and numerical data
- Prediction is logarithmic in the number of data points
- Disadvantages
- Overfitting
- High variance ]
.pull-right[ 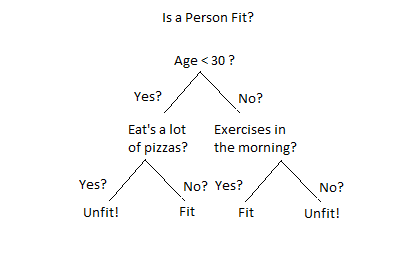 ]
]
Ensemble method
.pull-left[
- Combine multiple tree estimators
- Approaches - Bagging and boosting
- Bagging
- Average prediction of several estimators trained independent of each other
- Parallel execution
- Examples - Bagging, Random forest
- Boosting
- Improve estimators sequentially
- No parallel execution
- Examples - Adaboost, Gradient tree boosting ]
.pull-right[ 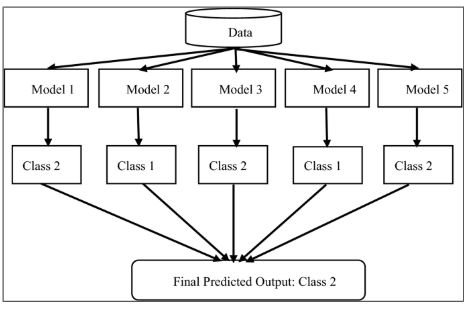 ]
]
References
- Book: Pattern Recognition and Machine Learning, Author: Christopher Bishop, 2006, Springer
- Nearest neighbours - https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
- Decision tree - https://scikit-learn.org/stable/modules/tree.html#tree
- Ensemble - https://scikit-learn.org/stable/modules/ensemble.html
For additional references, please see tutorial’s References section
- Galaxy Training Materials (training.galaxyproject.org)
Speaker Notes
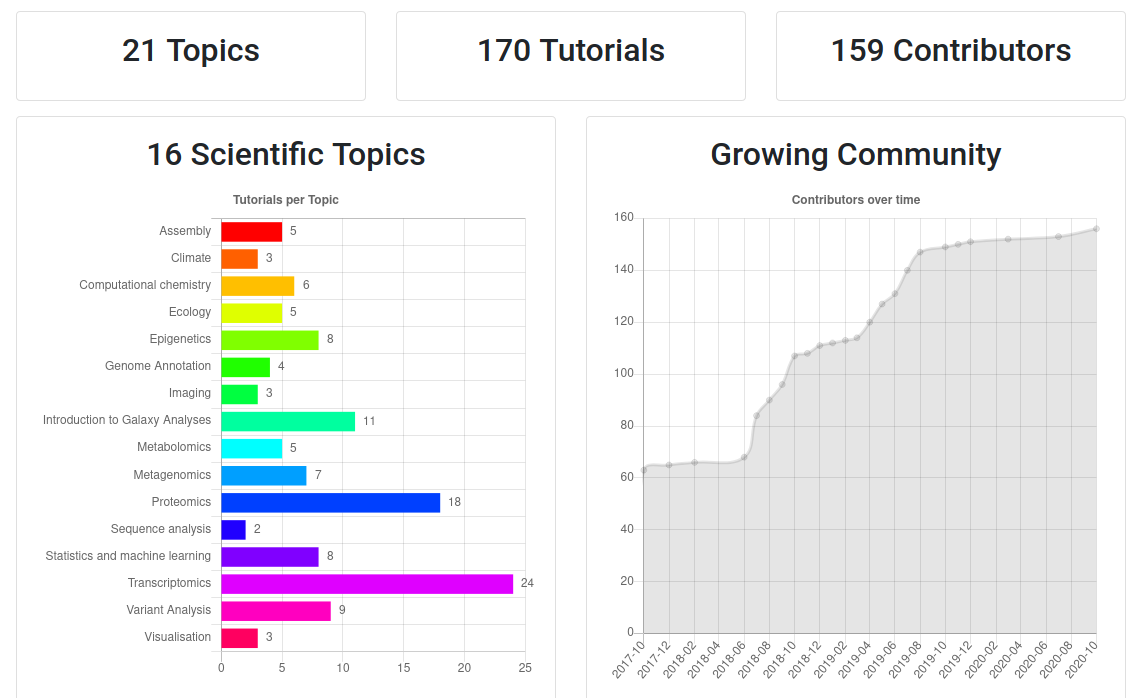
- If you would like to learn more about Galaxy, there are a large number of tutorials available.
- These tutorials cover a wide range of scientific domains.
Getting Help
-
Help Forum (help.galaxyproject.org)
-
Gitter Chat
- Main Chat
- Galaxy Training Chat
- Many more channels (scientific domains, developers, admins)
Speaker Notes
- If you get stuck, there are ways to get help.
- You can ask your questions on the help forum.
- Or you can chat with the community on Gitter.
Join an event
- Many Galaxy events across the globe
- Event Horizon: galaxyproject.org/events
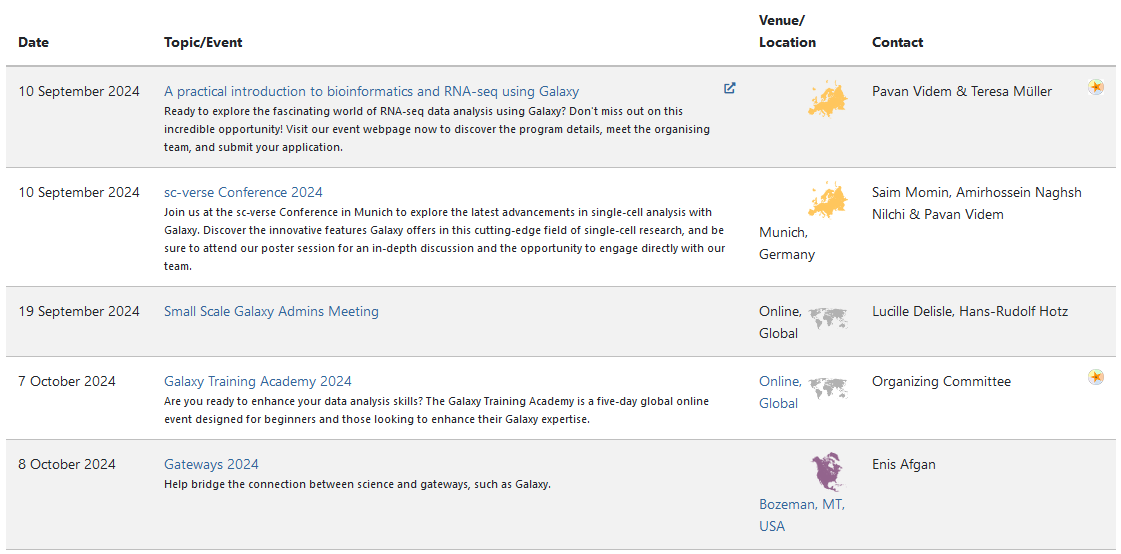
Speaker Notes
- There are frequent Galaxy events all around the world.
- You can find upcoming events on the Galaxy Event Horizon.
Key Points
- Classification is a supervised approach in machine learning.
- For classification tasks, data is divided into training and test sets.
- Using classification, the samples are learned using the training set and predicted using the test set.
- For each classification algorithm, the parameters should be optimised based on the dataset.
- Classification algorithms can be applied to, for example, chemical datasets to predict important properties.
Thank you!
This material is the result of a collaborative work. Thanks to the Galaxy Training Network and all the contributors! Tutorial Content is licensed under
Creative Commons Attribution 4.0 International License.
Tutorial Content is licensed under
Creative Commons Attribution 4.0 International License.